 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJens Lehmann
How Complex is your classification problem? A survey on measuring classification complexity
Aug 10, 2018
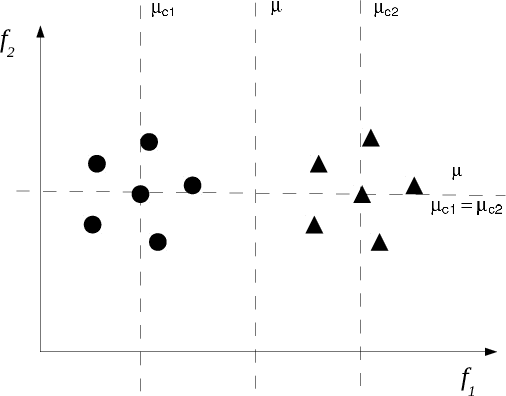
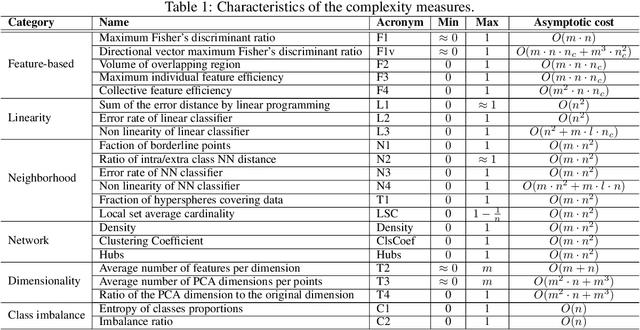
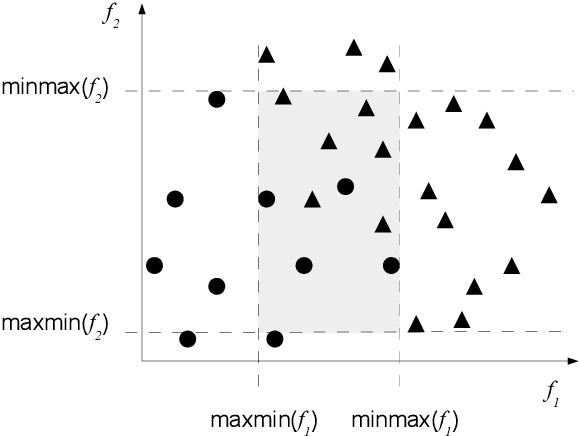
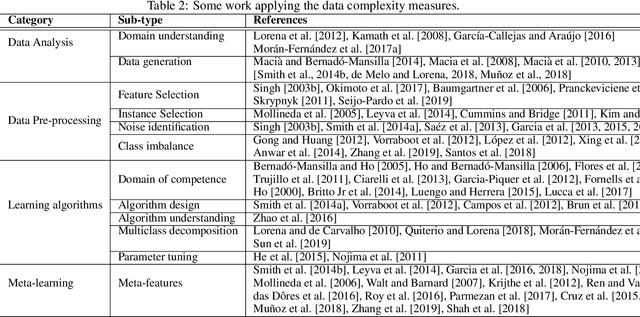
Extracting characteristics from the training datasets of classification problems has proven effective in a number of meta-analyses. Among them, measures of classification complexity can estimate the difficulty in separating the data points into their expected classes. Descriptors of the spatial distribution of the data and estimates of the shape and size of the decision boundary are among the existent measures for this characterization. This information can support the formulation of new data-driven pre-processing and pattern recognition techniques, which can in turn be focused on challenging characteristics of the problems. This paper surveys and analyzes measures which can be extracted from the training datasets in order to characterize the complexity of the respective classification problems. Their use in recent literature is also reviewed and discussed, allowing to prospect opportunities for future work in the area. Finally, descriptions are given on an R package named Extended Complexity Library (ECoL) that implements a set of complexity measures and is made publicly available.
EARL: Joint Entity and Relation Linking for Question Answering over Knowledge Graphs
Jun 25, 2018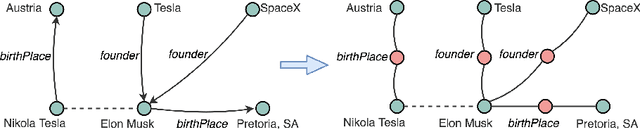
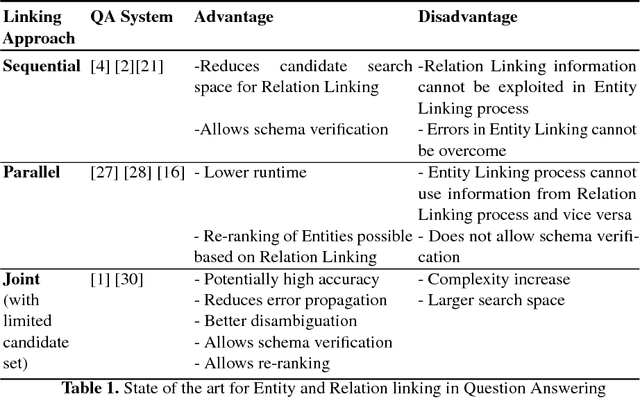
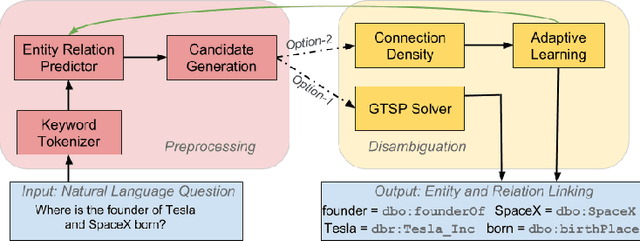
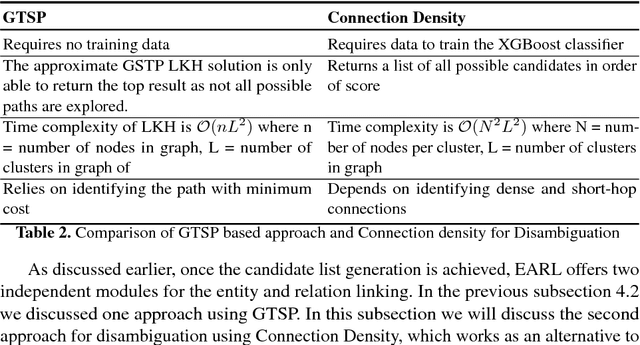
Many question answering systems over knowledge graphs rely on entity and relation linking components in order to connect the natural language input to the underlying knowledge graph. Traditionally, entity linking and relation linking have been performed either as dependent sequential tasks or as independent parallel tasks. In this paper, we propose a framework called EARL, which performs entity linking and relation linking as a joint task. EARL implements two different solution strategies for which we provide a comparative analysis in this paper: The first strategy is a formalisation of the joint entity and relation linking tasks as an instance of the Generalised Travelling Salesman Problem (GTSP). In order to be computationally feasible, we employ approximate GTSP solvers. The second strategy uses machine learning in order to exploit the connection density between nodes in the knowledge graph. It relies on three base features and re-ranking steps in order to predict entities and relations. We compare the strategies and evaluate them on a dataset with 5000 questions. Both strategies significantly outperform the current state-of-the-art approaches for entity and relation linking.
Incorporating Literals into Knowledge Graph Embeddings
May 25, 2018
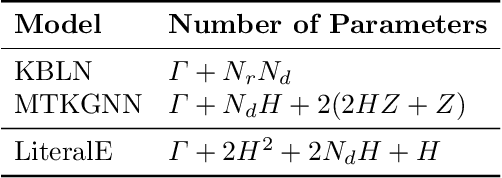
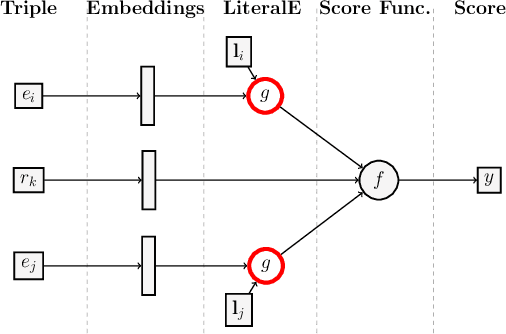
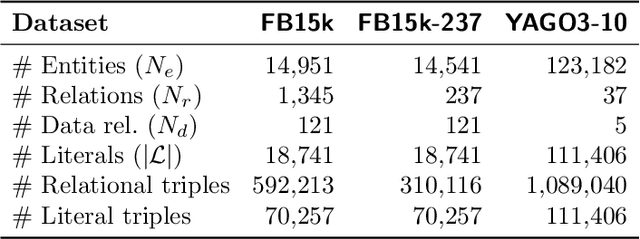
Knowledge graphs, on top of entities and their relationships, contain other important elements: literals. Literals encode interesting properties (e.g. the height) of entities that are not captured by links between entities alone. Most of the existing work on embedding (or latent feature) based knowledge graph analysis focuses mainly on the relations between entities. In this work, we study the effect of incorporating literal information into existing link prediction methods. Our approach, which we name LiteralE, is an extension that can be plugged into existing latent feature methods. LiteralE merges entity embeddings with their literal information using a learnable, parametrized function, such as a simple linear or nonlinear transformation, or a multilayer neural network. We extend several popular embedding models based on LiteralE and evaluate their performance on the task of link prediction. Despite its simplicity, LiteralE proves to be an effective way to incorporate literal information into existing embedding based methods, improving their performance on different standard datasets, which we augmented with their literals and provide as testbed for further research.
Formal Ontology Learning from English IS-A Sentences
Feb 11, 2018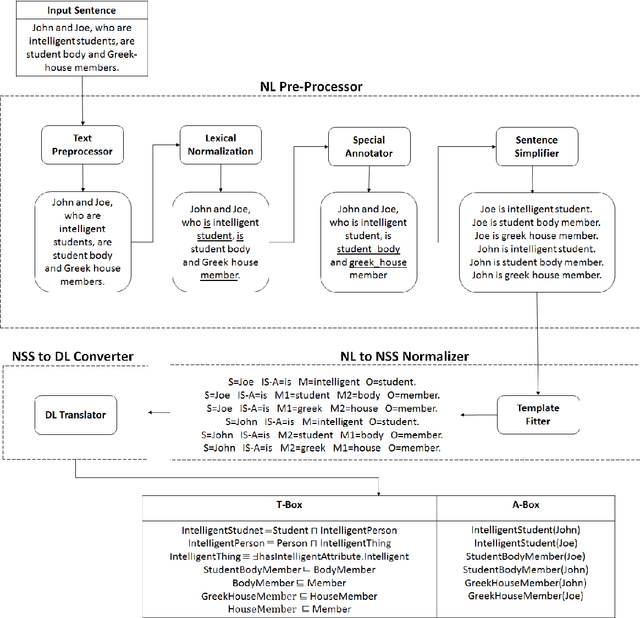
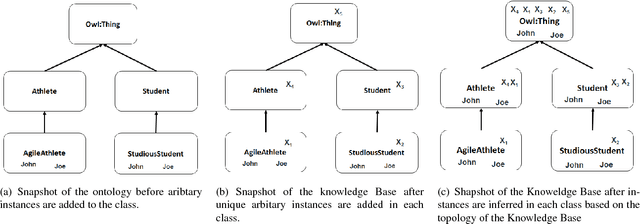
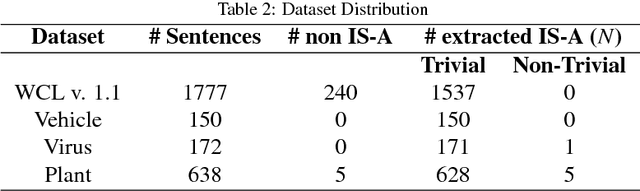

Ontology learning (OL) is the process of automatically generating an ontological knowledge base from a plain text document. In this paper, we propose a new ontology learning approach and tool, called DLOL, which generates a knowledge base in the description logic (DL) SHOQ(D) from a collection of factual non-negative IS-A sentences in English. We provide extensive experimental results on the accuracy of DLOL, giving experimental comparisons to three state-of-the-art existing OL tools, namely Text2Onto, FRED, and LExO. Here, we use the standard OL accuracy measure, called lexical accuracy, and a novel OL accuracy measure, called instance-based inference model. In our experimental results, DLOL turns out to be about 21% and 46%, respectively, better than the best of the other three approaches.
SimDoc: Topic Sequence Alignment based Document Similarity Framework
Nov 11, 2017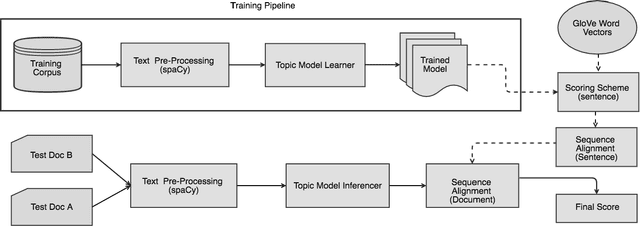

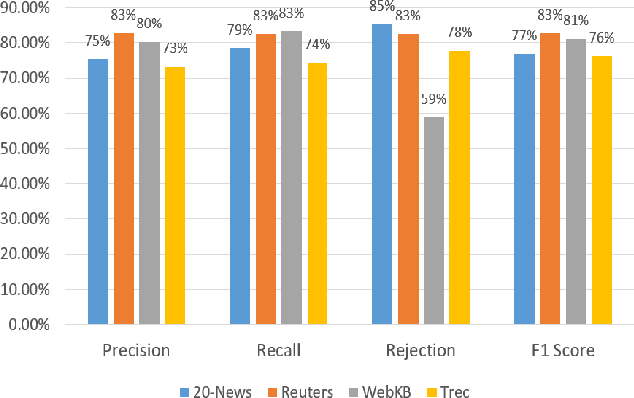

Document similarity is the problem of estimating the degree to which a given pair of documents has similar semantic content. An accurate document similarity measure can improve several enterprise relevant tasks such as document clustering, text mining, and question-answering. In this paper, we show that a document's thematic flow, which is often disregarded by bag-of-word techniques, is pivotal in estimating their similarity. To this end, we propose a novel semantic document similarity framework, called SimDoc. We model documents as topic-sequences, where topics represent latent generative clusters of related words. Then, we use a sequence alignment algorithm to estimate their semantic similarity. We further conceptualize a novel mechanism to compute topic-topic similarity to fine tune our system. In our experiments, we show that SimDoc outperforms many contemporary bag-of-words techniques in accurately computing document similarity, and on practical applications such as document clustering.
Named Entity Recognition in Twitter using Images and Text
Oct 30, 2017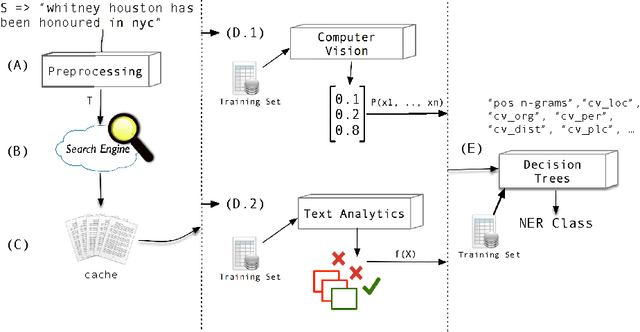

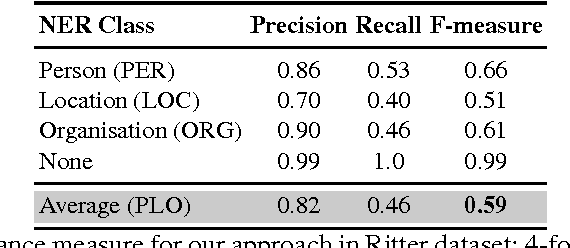

Named Entity Recognition (NER) is an important subtask of information extraction that seeks to locate and recognise named entities. Despite recent achievements, we still face limitations with correctly detecting and classifying entities, prominently in short and noisy text, such as Twitter. An important negative aspect in most of NER approaches is the high dependency on hand-crafted features and domain-specific knowledge, necessary to achieve state-of-the-art results. Thus, devising models to deal with such linguistically complex contexts is still challenging. In this paper, we propose a novel multi-level architecture that does not rely on any specific linguistic resource or encoded rule. Unlike traditional approaches, we use features extracted from images and text to classify named entities. Experimental tests against state-of-the-art NER for Twitter on the Ritter dataset present competitive results (0.59 F-measure), indicating that this approach may lead towards better NER models.
Using Multi-Label Classification for Improved Question Answering
Oct 24, 2017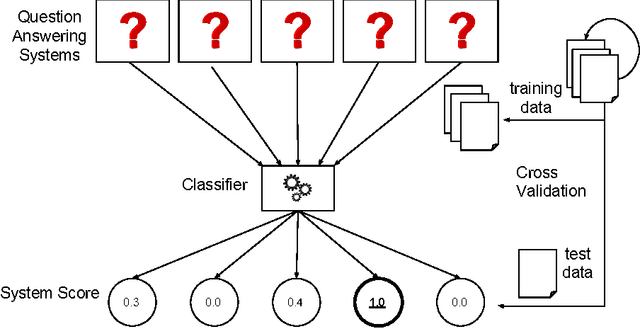
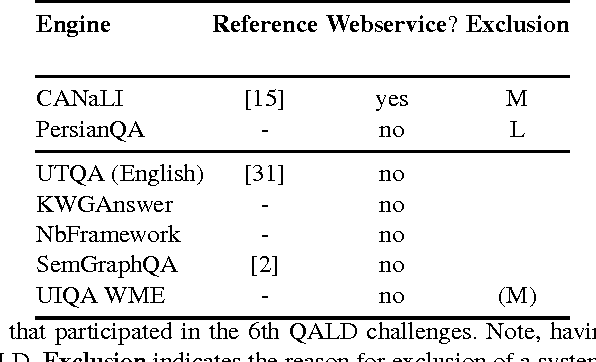
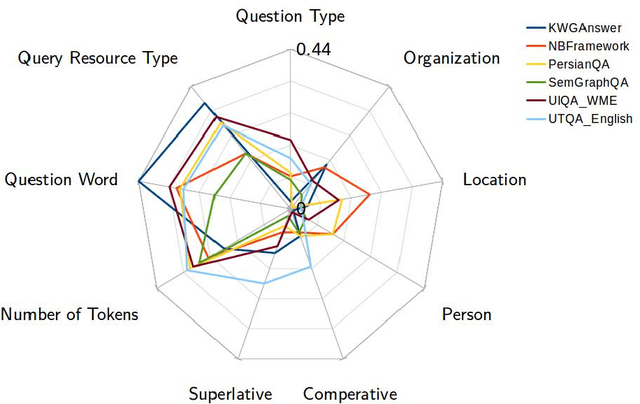
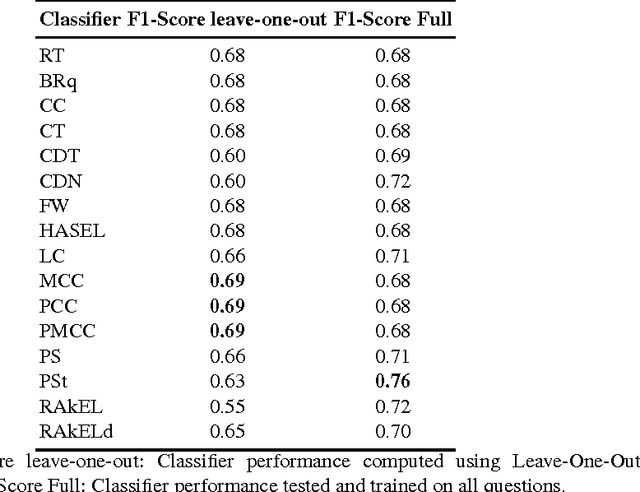
A plethora of diverse approaches for question answering over RDF data have been developed in recent years. While the accuracy of these systems has increased significantly over time, most systems still focus on particular types of questions or particular challenges in question answering. What is a curse for single systems is a blessing for the combination of these systems. We show in this paper how machine learning techniques can be applied to create a more accurate question answering metasystem by reusing existing systems. In particular, we develop a multi-label classification-based metasystem for question answering over 6 existing systems using an innovative set of 14 question features. The metasystem outperforms the best single system by 14% F-measure on the recent QALD-6 benchmark. Furthermore, we analyzed the influence and correlation of the underlying features on the metasystem quality.