 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Entity Linking with Attentive Neural Networks on Wikidata Knowledge Graph
Dec 12, 2019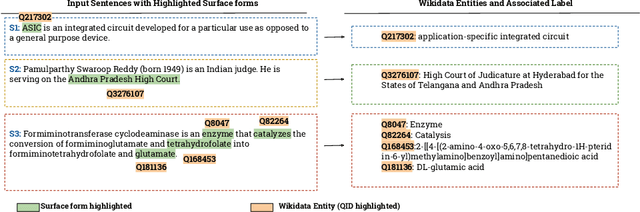
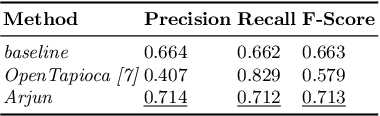
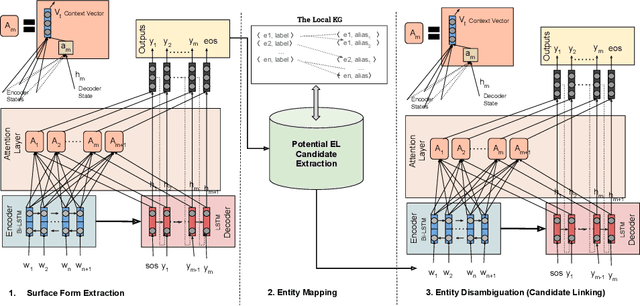
The Entity Linking (EL) approaches have been a long-standing research field and find applicability in various use cases such as semantic search, text annotation, question answering, etc. Although effective and robust, current approaches are still limited to particular knowledge repositories (e.g. Wikipedia) or specific knowledge graphs (e.g. Freebase, DBpedia, and YAGO). The collaborative knowledge graphs such as Wikidata excessively rely on the crowd to author the information. Since the crowd is not bound to a standard protocol for assigning entity titles, the knowledge graph is populated by non-standard, noisy, long or even sometimes awkward titles. The issue of long, implicit, and nonstandard entity representations is a challenge in EL approaches for gaining high precision and recall. In this paper, we advance the state-of-the-art approaches by developing a context-aware attentive neural network approach for entity linking on Wikidata. Our approach contributes by exploiting the sufficient context from a Knowledge Graph as a source of background knowledge, which is then fed into the neural network. This approach demonstrates merit to address challenges associated with entity titles (multi-word, long, implicit, case-sensitive). Our experimental study shows $\approx$8\% improvements over the baseline approach, and significantly outperform an end to end approach for Wikidata entity linking. This work, first of its kind, opens a new direction for the research community to pay attention to developing context-aware EL approaches for collaborative knowledge graphs.
Open-domain Event Extraction and Embedding for Natural Gas Market Prediction
Dec 08, 2019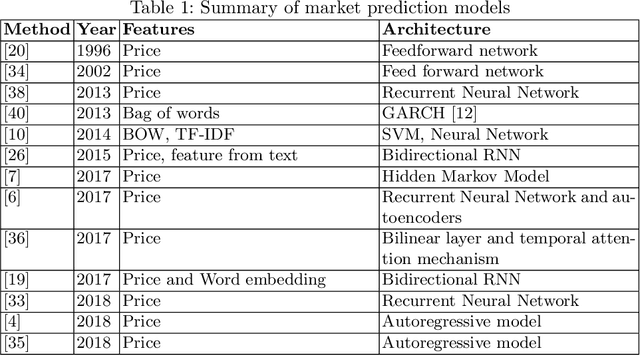
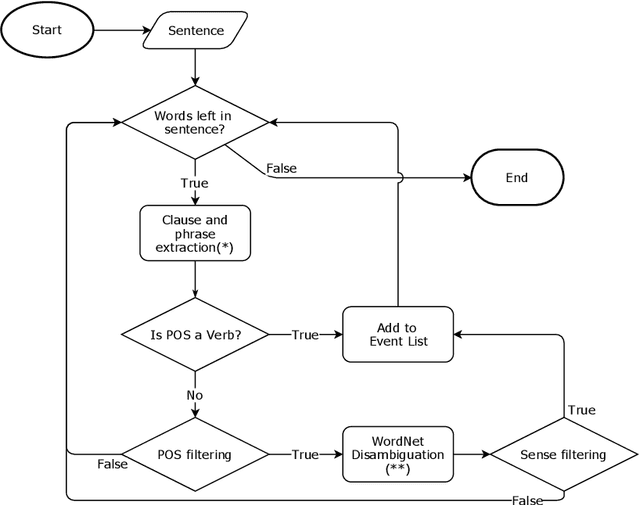
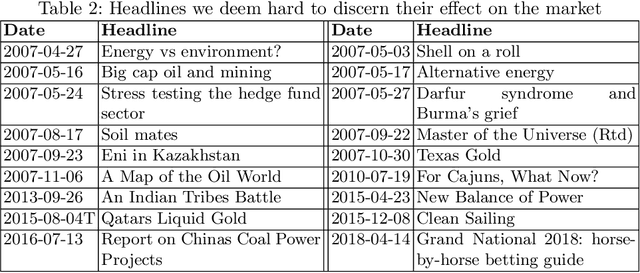
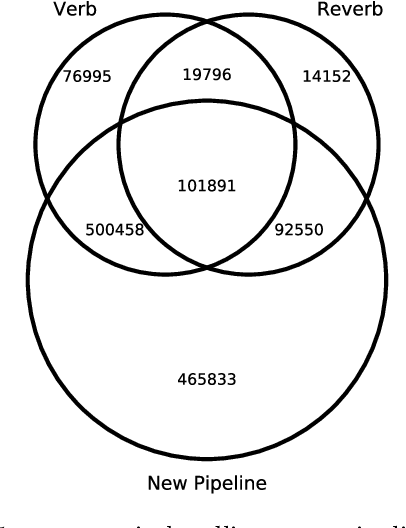
We propose an approach to predict the natural gas price in several days using historical price data and events extracted from news headlines. Most previous methods treats price as an extrapolatable time series, those analyze the relation between prices and news either trim their price data correspondingly to a public news dataset, manually annotate headlines or use off-the-shelf tools. In comparison to off-the-shelf tools, our event extraction method detects not only the occurrence of phenomena but also the changes in attribution and characteristics from public sources. Instead of using sentence embedding as a feature, we use every word of the extracted events, encode and organize them before feeding to the learning models. Empirical results show favorable results, in terms of prediction performance, money saved and scalability.
Direct Mappings between RDF and Property Graph Databases
Dec 04, 2019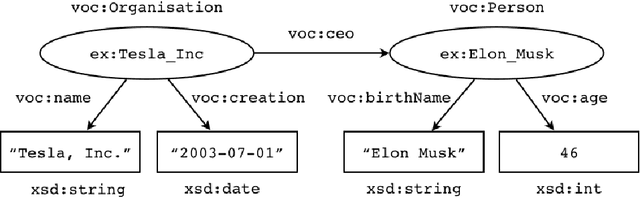
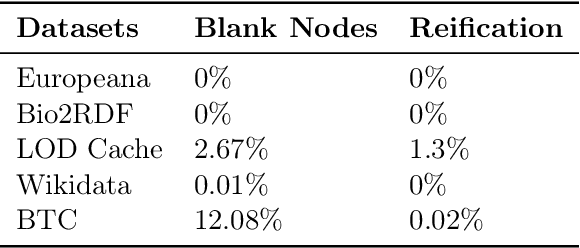
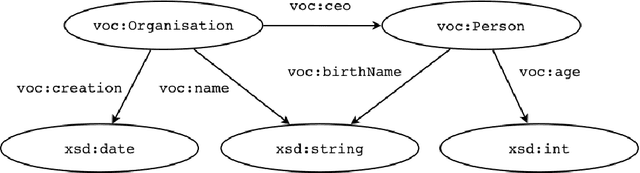
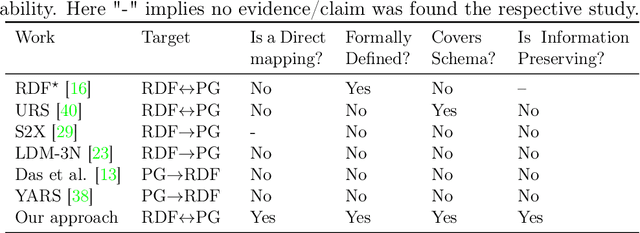
Resource Description Framework (RDF) triplestores and Property Graph (PG) database systems are two approaches for data management that are based on modeling, storing and querying graph-like data. Given the heterogeneity between these systems, it becomes necessary to develop methods to allow interoperability among them. While there exist some approaches to exchange data and schema between RDF and PG databases, they lack compatibility and even a solid formal foundation. In this paper, we study the semantic interoperability between RDF and PG databases. Specifically, we present two direct mappings (schema-dependent and schema-independent) for transforming an RDF database into a PG database. We show that the proposed mappings possess the fundamental properties of semantics preservation and information preservation. The existence of both mappings allows us to conclude that the PG data model subsumes the expressiveness or information capacity of the RDF data model.
Temporal Knowledge Graph Embedding Model based on Additive Time Series Decomposition
Nov 18, 2019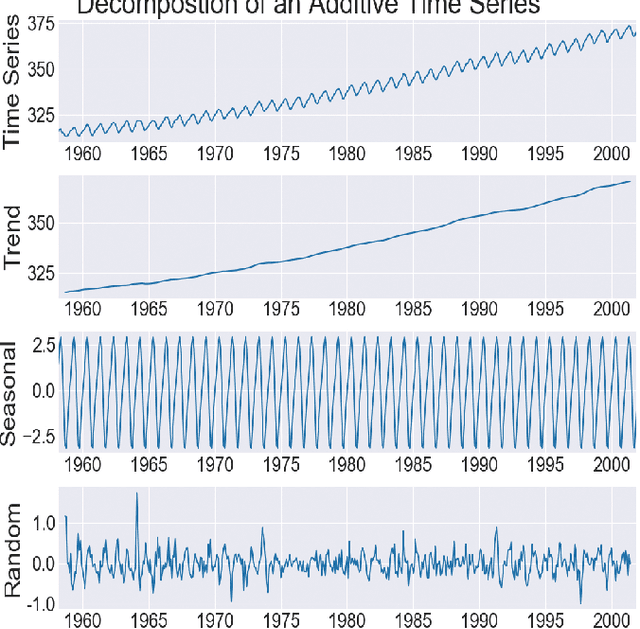
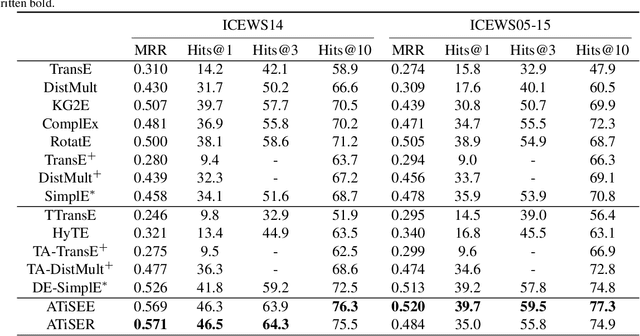
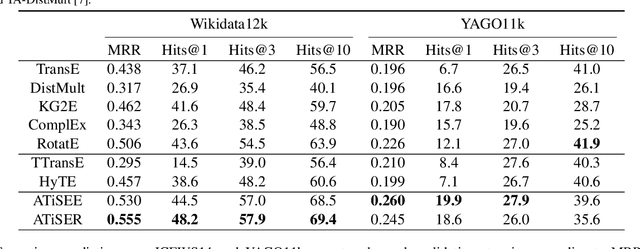
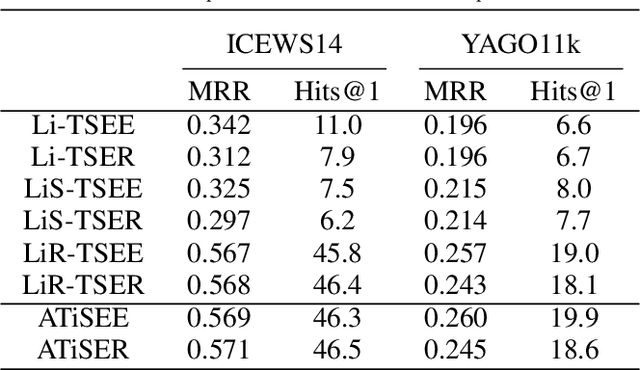
Knowledge Graph (KG) embedding has attracted more attention in recent years. Most of KG embedding models learn from time-unaware triples. However, the inclusion of temporal information beside triples would further improve the performance of a KGE model. In this regard, we propose ATiSE, a temporal KG embedding model which incorporates time information into entity/relation representations by using Additive Time Series decomposition. Moreover, considering the temporal uncertainty during the evolution of entity/relation representations over time, we map the representations of temporal KGs into the space of multi-dimensional Gaussian distributions. The mean of each entity/relation embedding at a time step shows the current expected position, whereas its covariance (which is temporally stationary) represents its temporal uncertainty. Experimental results show that ATiSE not only achieves the state-of-the-art on link prediction over temporal KGs, but also can predict the occurrence time of facts with missing time annotations, as well as the existence of future events. To the best of our knowledge, no other model is capable to perform all these tasks.
Using a KG-Copy Network for Non-Goal Oriented Dialogues
Oct 17, 2019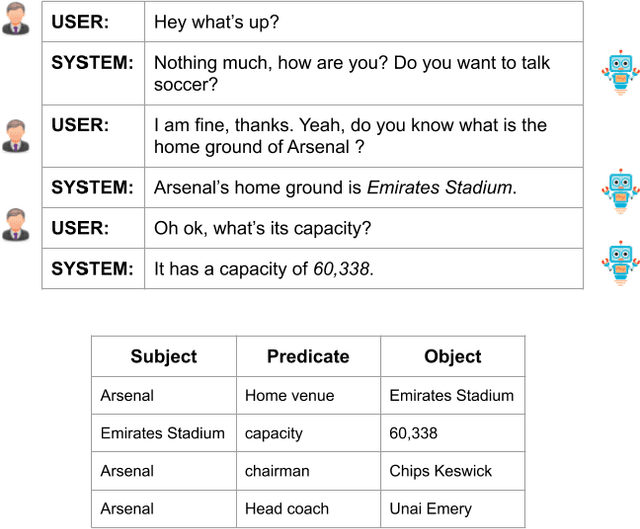
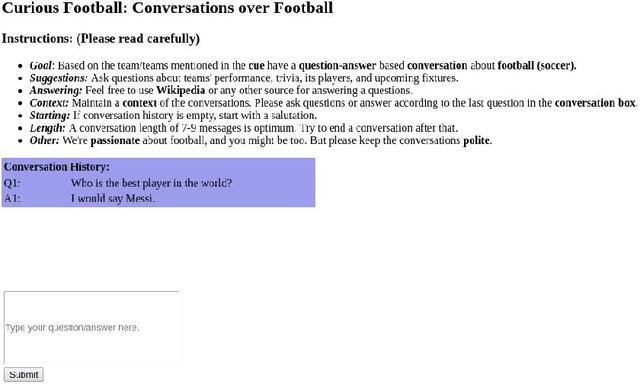
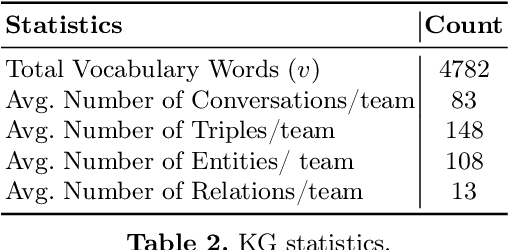
Non-goal oriented, generative dialogue systems lack the ability to generate answers with grounded facts. A knowledge graph can be considered an abstraction of the real world consisting of well-grounded facts. This paper addresses the problem of generating well grounded responses by integrating knowledge graphs into the dialogue systems response generation process, in an end-to-end manner. A dataset for nongoal oriented dialogues is proposed in this paper in the domain of soccer, conversing on different clubs and national teams along with a knowledge graph for each of these teams. A novel neural network architecture is also proposed as a baseline on this dataset, which can integrate knowledge graphs into the response generation process, producing well articulated, knowledge grounded responses. Empirical evidence suggests that the proposed model performs better than other state-of-the-art models for knowledge graph integrated dialogue systems.
Toward Understanding The Effect Of Loss function On Then Performance Of Knowledge Graph Embedding
Oct 10, 2019
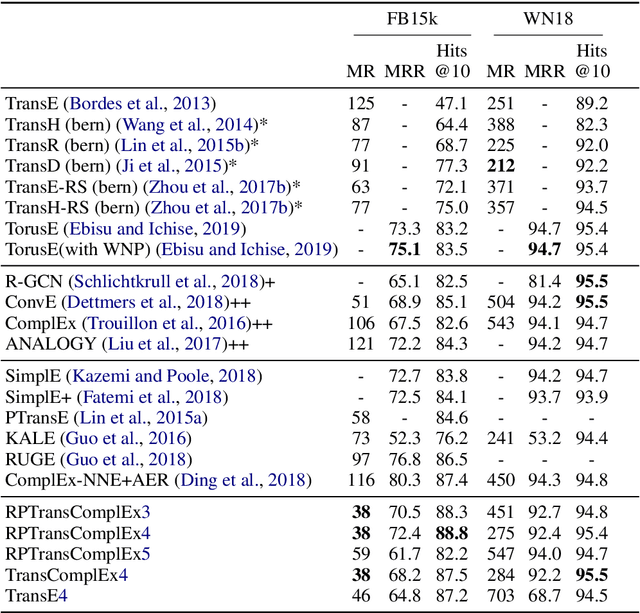
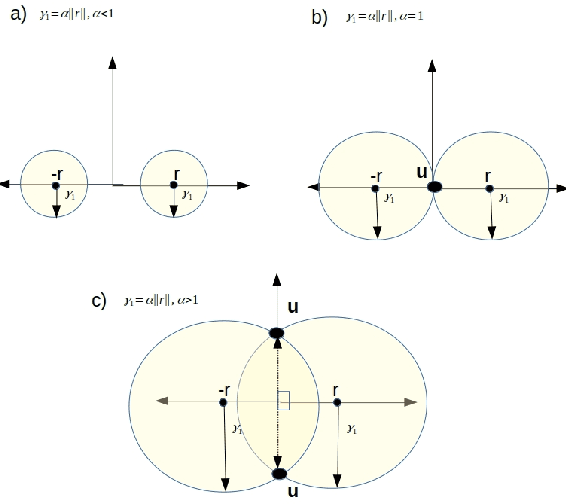
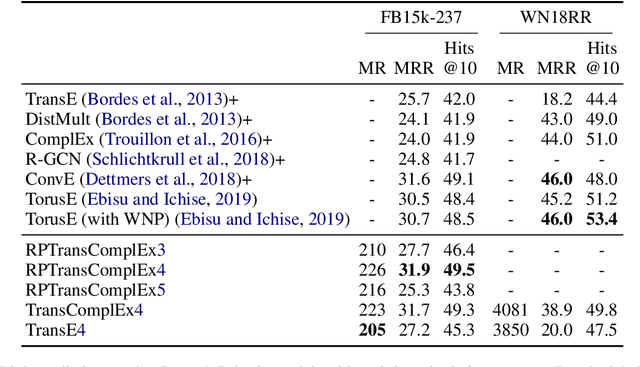
Knowledge graphs (KGs) represent world's facts in structured forms. KG completion exploits the existing facts in a KG to discover new ones. Translation-based embedding model (TransE) is a prominent formulation to do KG completion. Despite the efficiency of TransE in memory and time, it suffers from several limitations in encoding relation patterns such as symmetric, reflexive etc. To resolve this problem, most of the attempts have circled around the revision of the score function of TransE i.e., proposing a more complicated score function such as Trans(A, D, G, H, R, etc) to mitigate the limitations. In this paper, we tackle this problem from a different perspective. We show that existing theories corresponding to the limitations of TransE are inaccurate because they ignore the effect of loss function. Accordingly, we pose theoretical investigations of the main limitations of TransE in the light of loss function. To the best of our knowledge, this has not been investigated so far comprehensively. We show that by a proper selection of the loss function for training the TransE model, the main limitations of the model are mitigated. This is explained by setting upper-bound for the scores of positive samples, showing the region of truth (i.e., the region that a triple is considered positive by the model). Our theoretical proofs with experimental results fill the gap between the capability of translation-based class of embedding models and the loss function. The theories emphasise the importance of the selection of the loss functions for training the models. Our experimental evaluations on different loss functions used for training the models justify our theoretical proofs and confirm the importance of the loss functions on the performance.
The Query Translation Landscape: a Survey
Oct 07, 2019
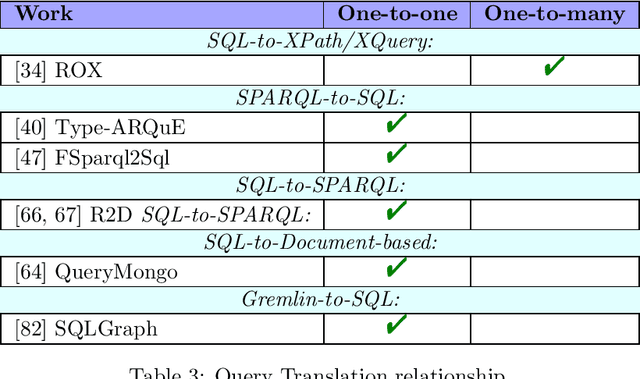
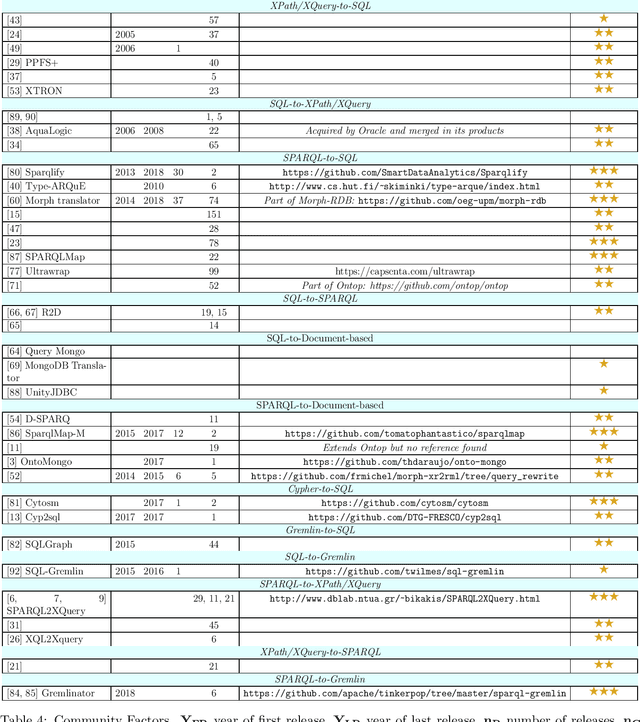
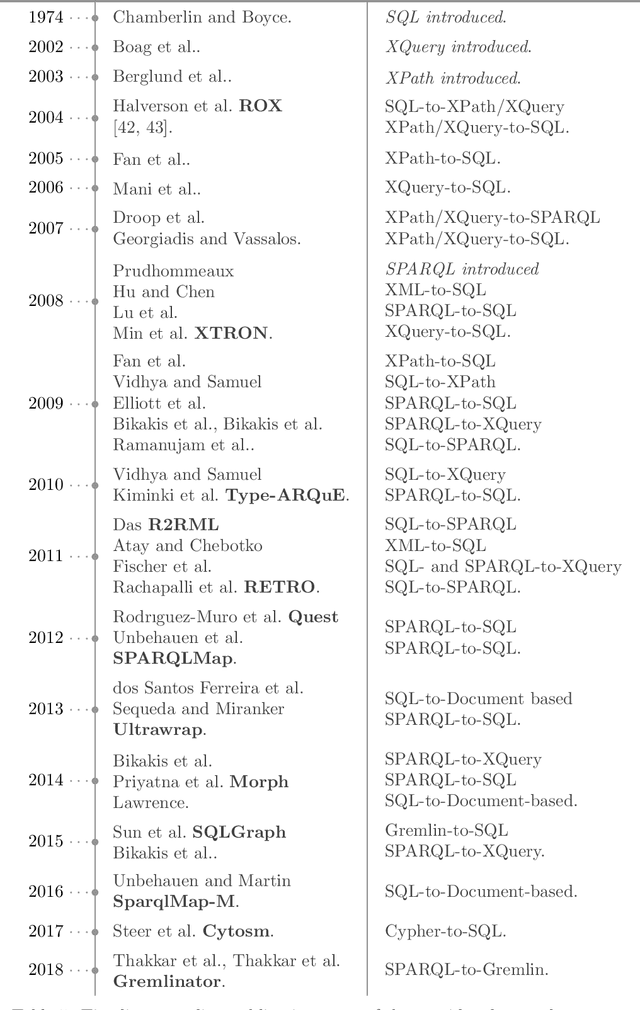
Whereas the availability of data has seen a manyfold increase in past years, its value can be only shown if the data variety is effectively tackled ---one of the prominent Big Data challenges. The lack of data interoperability limits the potential of its collective use for novel applications. Achieving interoperability through the full transformation and integration of diverse data structures remains an ideal that is hard, if not impossible, to achieve. Instead, methods that can simultaneously interpret different types of data available in different data structures and formats have been explored. On the other hand, many query languages have been designed to enable users to interact with the data, from relational, to object-oriented, to hierarchical, to the multitude emerging NoSQL languages. Therefore, the interoperability issue could be solved not by enforcing physical data transformation, but by looking at techniques that are able to query heterogeneous sources using one uniform language. Both industry and research communities have been keen to develop such techniques, which require the translation of a chosen 'universal' query language to the various data model specific query languages that make the underlying data accessible. In this article, we survey more than forty query translation methods and tools for popular query languages, and classify them according to eight criteria. In particular, we study which query language is a most suitable candidate for that 'universal' query language. Further, the results enable us to discover the weakly addressed and unexplored translation paths, to discover gaps and to learn lessons that can benefit future research in the area.
Method for the semantic indexing of concept hierarchies, uniform representation, use of relational database systems and generic and case-based reasoning
Oct 03, 2019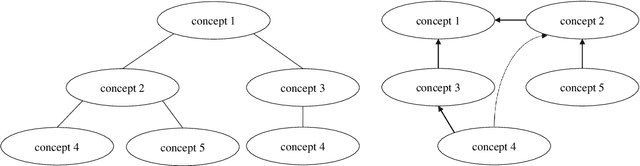

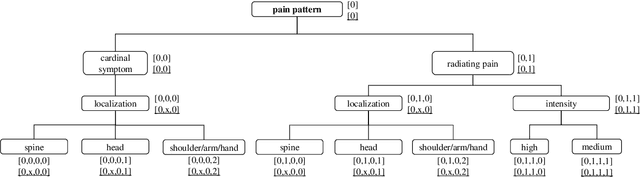
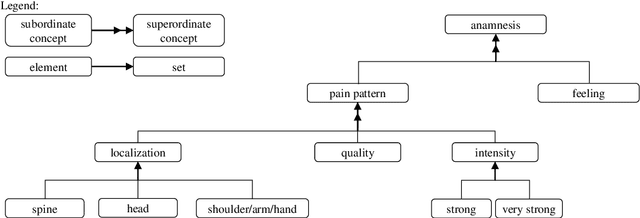
This paper presents a method for semantic indexing and describes its application in the field of knowledge representation. Starting point of the semantic indexing is the knowledge represented by concept hierarchies. The goal is to assign keys to nodes (concepts) that are hierarchically ordered and syntactically and semantically correct. With the indexing algorithm, keys are computed such that concepts are partially unifiable with all more specific concepts and only semantically correct concepts are allowed to be added. The keys represent terminological relationships. Correctness and completeness of the underlying indexing algorithm are proven. The use of classical relational databases for the storage of instances is described. Because of the uniform representation, inference can be done using case-based reasoning and generic problem solving methods.
MDP-based Shallow Parsing in Distantly Supervised QA Systems
Sep 27, 2019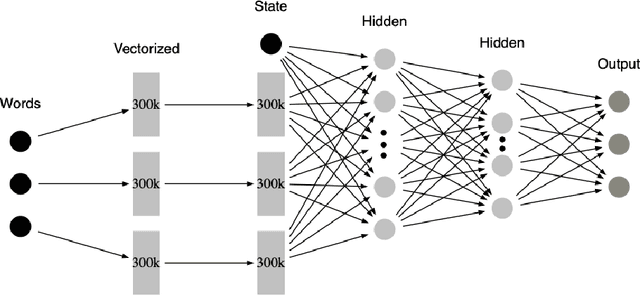

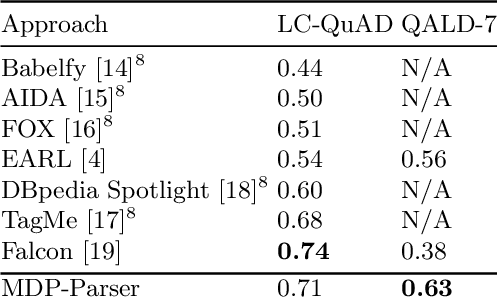
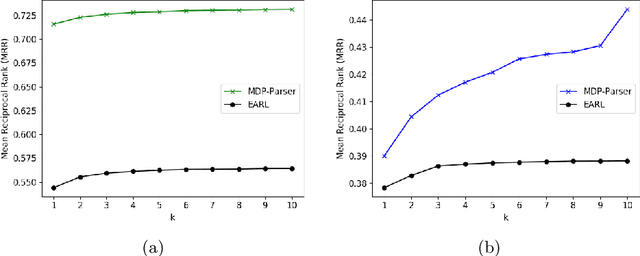
Question answering systems over knowledge graphs commonly consist of multiple components such as shallow parser, entity/relation linker, query generation and answer retrieval. We focus on the first task, shallow parsing, which so far received little attention in the QA community. Despite the lack of gold annotations for shallow parsing in question answering datasets, we devise a Reinforcement Learning based model called MDP-Parser, and show that it outperforms the current state-of-the-art approaches. Furthermore, it can be easily embedded into the existing entity/relation linking tools to boost the overall accuracy.
LogicENN: A Neural Based Knowledge Graphs Embedding Model with Logical Rules
Aug 20, 2019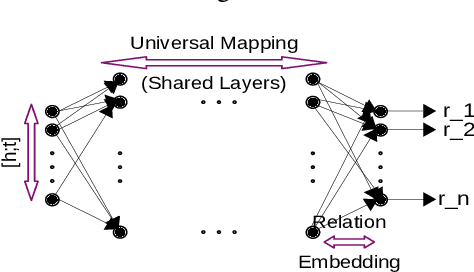
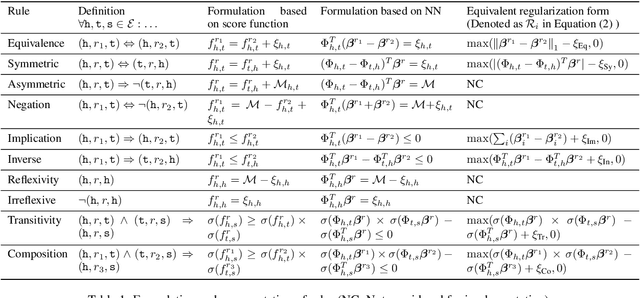
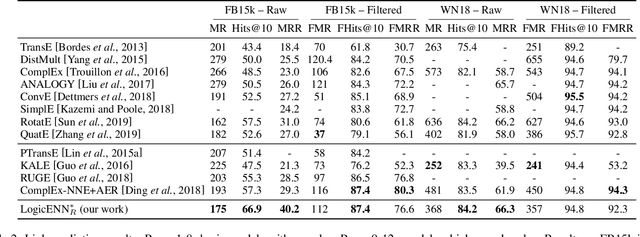
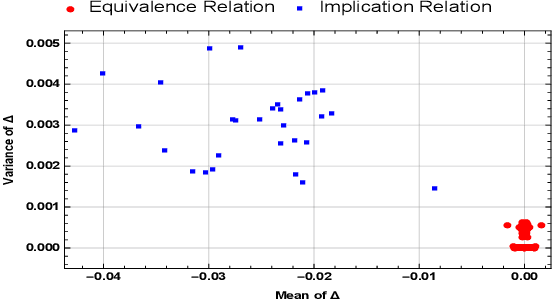
Knowledge graph embedding models have gained significant attention in AI research. Recent works have shown that the inclusion of background knowledge, such as logical rules, can improve the performance of embeddings in downstream machine learning tasks. However, so far, most existing models do not allow the inclusion of rules. We address the challenge of including rules and present a new neural based embedding model (LogicENN). We prove that LogicENN can learn every ground truth of encoded rules in a knowledge graph. To the best of our knowledge, this has not been proved so far for the neural based family of embedding models. Moreover, we derive formulae for the inclusion of various rules, including (anti-)symmetric, inverse, irreflexive and transitive, implication, composition, equivalence and negation. Our formulation allows to avoid grounding for implication and equivalence relations. Our experiments show that LogicENN outperforms the state-of-the-art models in link prediction.