 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaQA: A Question Answering Dataset with Paraphrase Responses for Single-Turn Conversation
Mar 13, 2021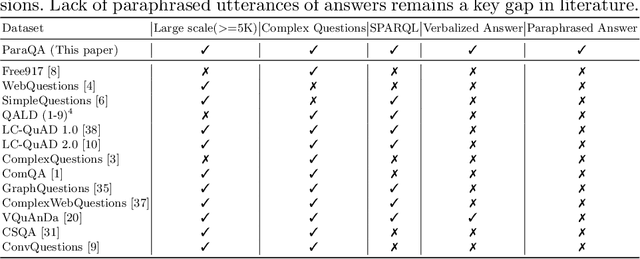
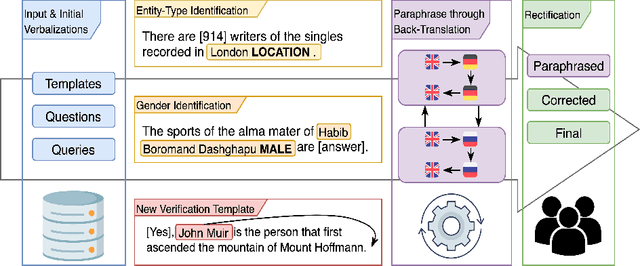

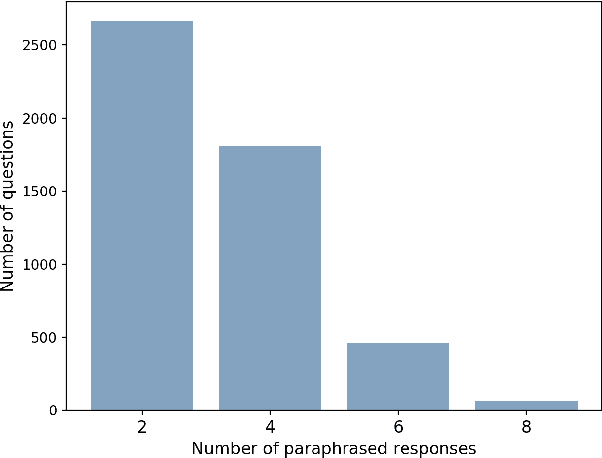
This paper presents ParaQA, a question answering (QA) dataset with multiple paraphrased responses for single-turn conversation over knowledge graphs (KG). The dataset was created using a semi-automated framework for generating diverse paraphrasing of the answers using techniques such as back-translation. The existing datasets for conversational question answering over KGs (single-turn/multi-turn) focus on question paraphrasing and provide only up to one answer verbalization. However, ParaQA contains 5000 question-answer pairs with a minimum of two and a maximum of eight unique paraphrased responses for each question. We complement the dataset with baseline models and illustrate the advantage of having multiple paraphrased answers through commonly used metrics such as BLEU and METEOR. The ParaQA dataset is publicly available on a persistent URI for broader usage and adaptation in the research community.
Context Transformer with Stacked Pointer Networks for Conversational Question Answering over Knowledge Graphs
Mar 13, 2021
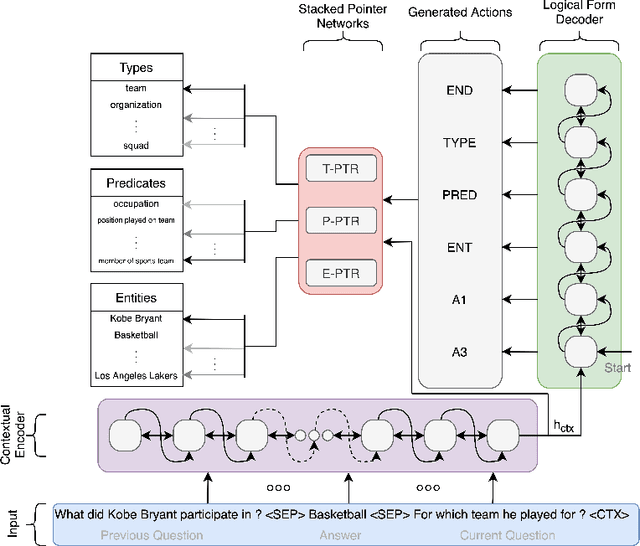
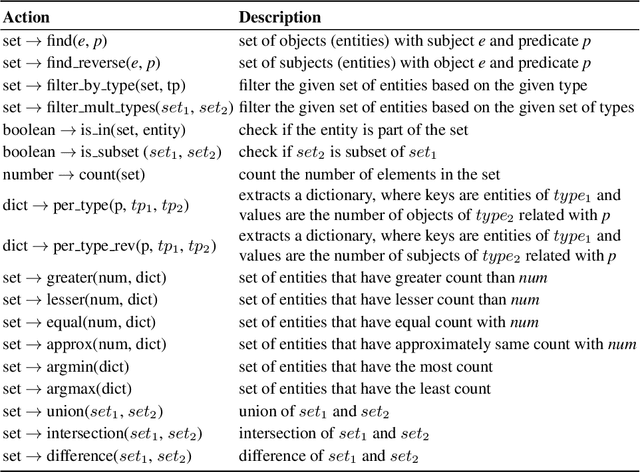
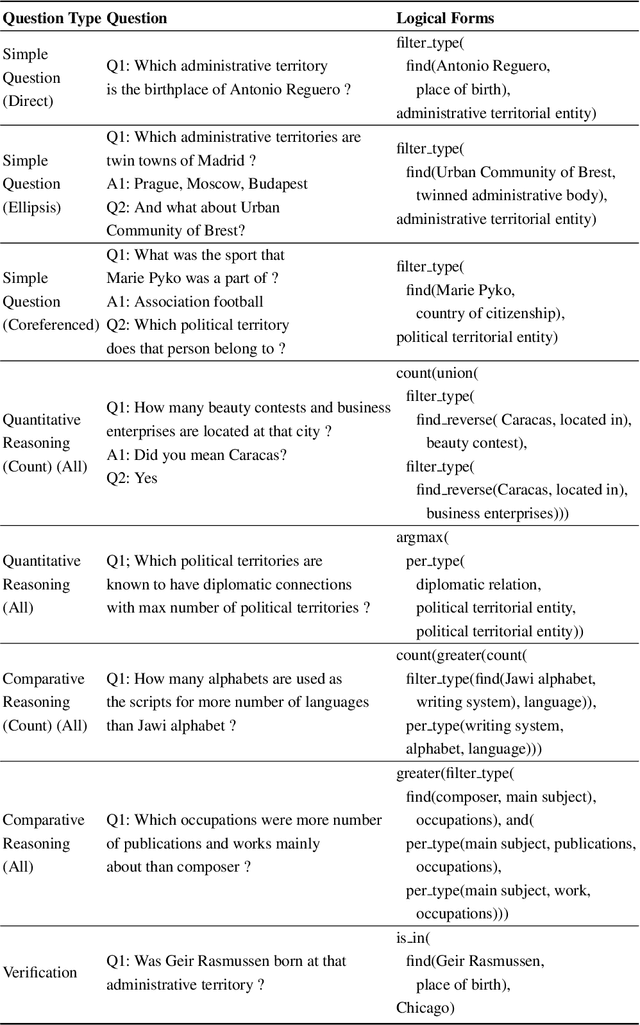
Neural semantic parsing approaches have been widely used for Question Answering (QA) systems over knowledge graphs. Such methods provide the flexibility to handle QA datasets with complex queries and a large number of entities. In this work, we propose a novel framework named CARTON, which performs multi-task semantic parsing for handling the problem of conversational question answering over a large-scale knowledge graph. Our framework consists of a stack of pointer networks as an extension of a context transformer model for parsing the input question and the dialog history. The framework generates a sequence of actions that can be executed on the knowledge graph. We evaluate CARTON on a standard dataset for complex sequential question answering on which CARTON outperforms all baselines. Specifically, we observe performance improvements in F1-score on eight out of ten question types compared to the previous state of the art. For logical reasoning questions, an improvement of 11 absolute points is reached.
CHOLAN: A Modular Approach for Neural Entity Linking on Wikipedia and Wikidata
Feb 08, 2021
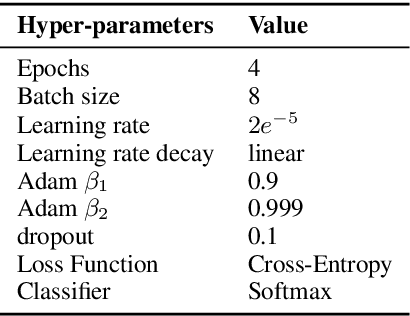
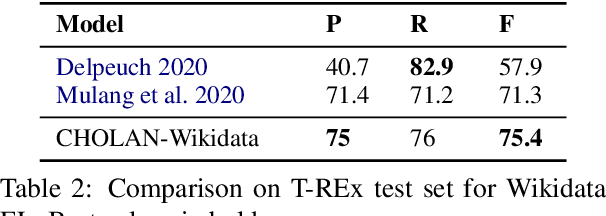
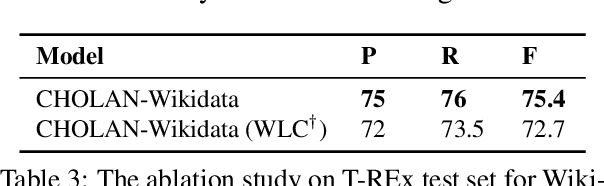
In this paper, we propose CHOLAN, a modular approach to target end-to-end entity linking (EL) over knowledge bases. CHOLAN consists of a pipeline of two transformer-based models integrated sequentially to accomplish the EL task. The first transformer model identifies surface forms (entity mentions) in a given text. For each mention, a second transformer model is employed to classify the target entity among a predefined candidates list. The latter transformer is fed by an enriched context captured from the sentence (i.e. local context), and entity description gained from Wikipedia. Such external contexts have not been used in the state of the art EL approaches. Our empirical study was conducted on two well-known knowledge bases (i.e., Wikidata and Wikipedia). The empirical results suggest that CHOLAN outperforms state-of-the-art approaches on standard datasets such as CoNLL-AIDA, MSNBC, AQUAINT, ACE2004, and T-REx.
SeMantic AnsweR Type prediction task at ISWC 2020 Semantic Web Challenge
Dec 01, 2020

Each year the International Semantic Web Conference accepts a set of Semantic Web Challenges to establish competitions that will advance the state of the art solutions in any given problem domain. The SeMantic AnsweR Type prediction task (SMART) was part of ISWC 2020 challenges. Question type and answer type prediction can play a key role in knowledge base question answering systems providing insights that are helpful to generate correct queries or rank the answer candidates. More concretely, given a question in natural language, the task of SMART challenge is, to predict the answer type using a target ontology (e.g., DBpedia or Wikidata).
TeRo: A Time-aware Knowledge Graph Embedding via Temporal Rotation
Oct 24, 2020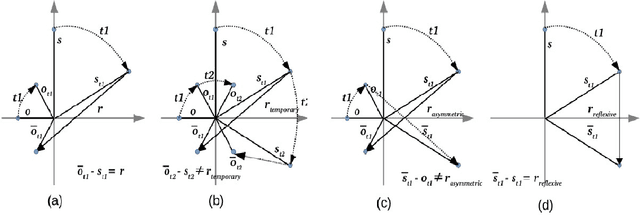

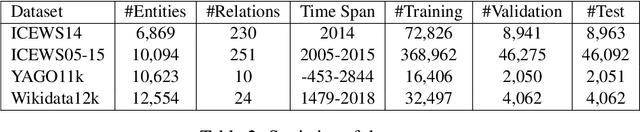
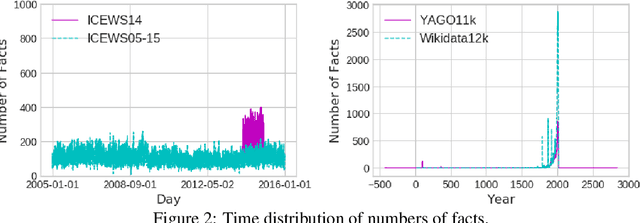
In the last few years, there has been a surge of interest in learning representations of entitiesand relations in knowledge graph (KG). However, the recent availability of temporal knowledgegraphs (TKGs) that contain time information for each fact created the need for reasoning overtime in such TKGs. In this regard, we present a new approach of TKG embedding, TeRo, which defines the temporal evolution of entity embedding as a rotation from the initial time to the currenttime in the complex vector space. Specially, for facts involving time intervals, each relation isrepresented as a pair of dual complex embeddings to handle the beginning and the end of therelation, respectively. We show our proposed model overcomes the limitations of the existing KG embedding models and TKG embedding models and has the ability of learning and inferringvarious relation patterns over time. Experimental results on four different TKGs show that TeRo significantly outperforms existing state-of-the-art models for link prediction. In addition, we analyze the effect of time granularity on link prediction over TKGs, which as far as we know hasnot been investigated in previous literature.
Knowledge Graph Embeddings in Geometric Algebras
Oct 24, 2020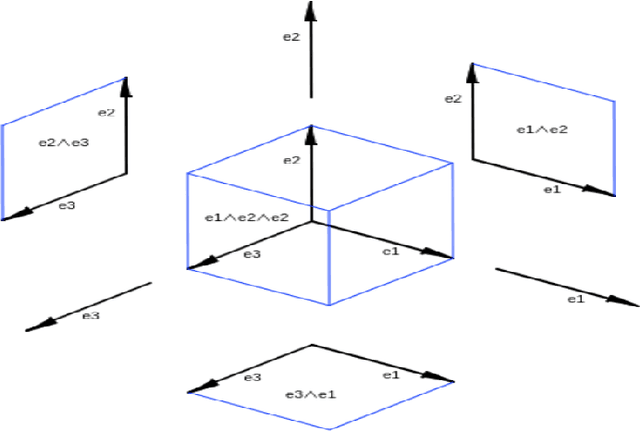

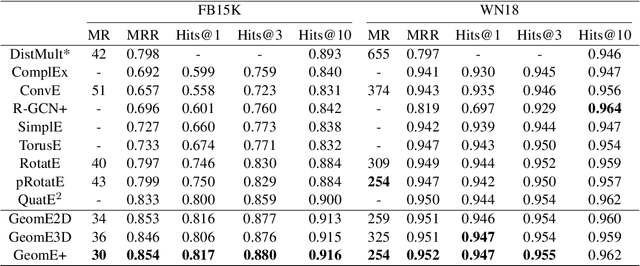
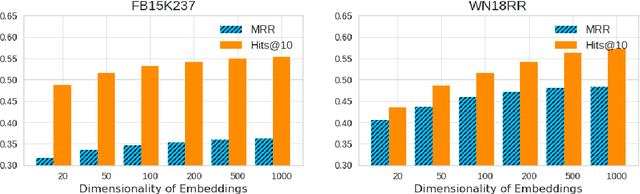
Knowledge graph (KG) embedding aims at embedding entities and relations in a KG into a lowdimensional latent representation space. Existing KG embedding approaches model entities andrelations in a KG by utilizing real-valued , complex-valued, or hypercomplex-valued (Quaternionor Octonion) representations, all of which are subsumed into a geometric algebra. In this work,we introduce a novel geometric algebra-based KG embedding framework, GeomE, which uti-lizes multivector representations and the geometric product to model entities and relations. Ourframework subsumes several state-of-the-art KG embedding approaches and is advantageouswith its ability of modeling various key relation patterns, including (anti-)symmetry, inversionand composition, rich expressiveness with higher degree of freedom as well as good general-ization capacity. Experimental results on multiple benchmark knowledge graphs show that theproposed approach outperforms existing state-of-the-art models for link prediction.
Motif Learning in Knowledge Graphs Using Trajectories Of Differential Equations
Oct 18, 2020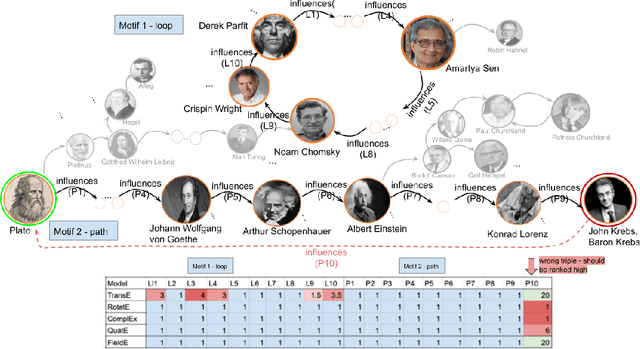

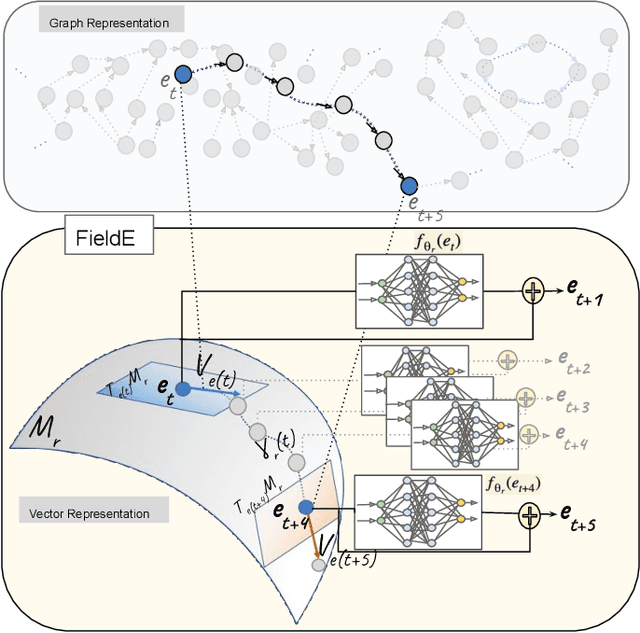

Knowledge Graph Embeddings (KGEs) have shown promising performance on link prediction tasks by mapping the entities and relations from a knowledge graph into a geometric space (usually a vector space). Ultimately, the plausibility of the predicted links is measured by using a scoring function over the learned embeddings (vectors). Therefore, the capability in preserving graph characteristics including structural aspects and semantics highly depends on the design of the KGE, as well as the inherited abilities from the underlying geometry. Many KGEs use the flat geometry which renders them incapable of preserving complex structures and consequently causes wrong inferences by the models. To address this problem, we propose a neuro differential KGE that embeds nodes of a KG on the trajectories of Ordinary Differential Equations (ODEs). To this end, we represent each relation (edge) in a KG as a vector field on a smooth Riemannian manifold. We specifically parameterize ODEs by a neural network to represent various complex shape manifolds and more importantly complex shape vector fields on the manifold. Therefore, the underlying embedding space is capable of getting various geometric forms to encode complexity in subgraph structures with different motifs. Experiments on synthetic and benchmark dataset as well as social network KGs justify the ODE trajectories as a means to structure preservation and consequently avoiding wrong inferences over state-of-the-art KGE models.
Message Passing for Hyper-Relational Knowledge Graphs
Sep 22, 2020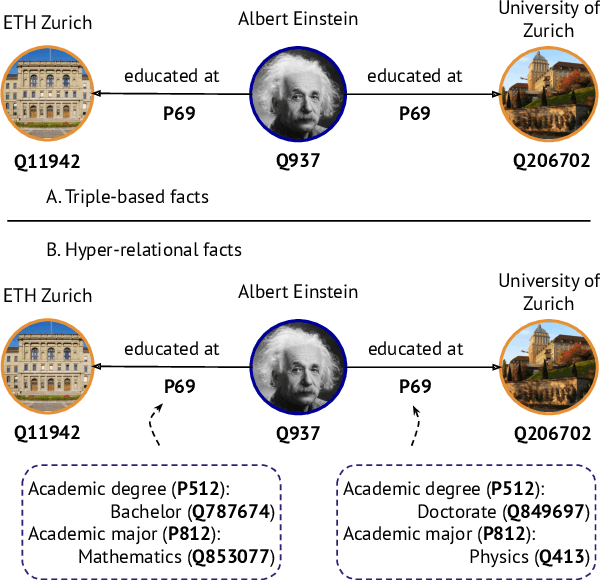
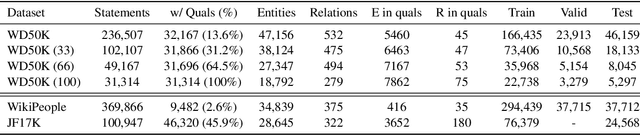
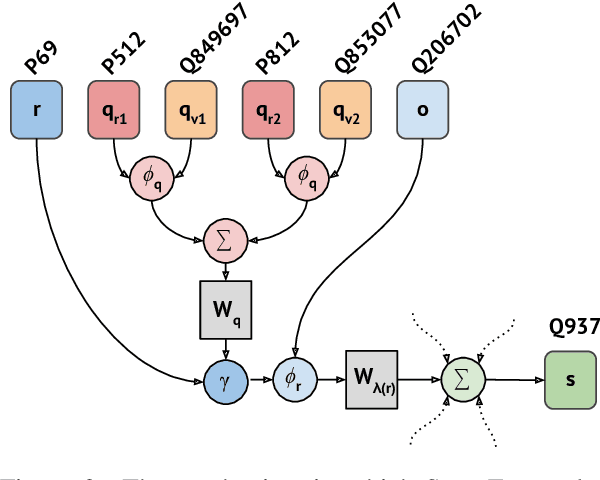
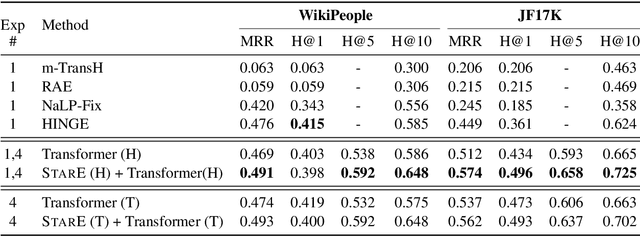
Hyper-relational knowledge graphs (KGs) (e.g., Wikidata) enable associating additional key-value pairs along with the main triple to disambiguate, or restrict the validity of a fact. In this work, we propose a message passing based graph encoder - StarE capable of modeling such hyper-relational KGs. Unlike existing approaches, StarE can encode an arbitrary number of additional information (qualifiers) along with the main triple while keeping the semantic roles of qualifiers and triples intact. We also demonstrate that existing benchmarks for evaluating link prediction (LP) performance on hyper-relational KGs suffer from fundamental flaws and thus develop a new Wikidata-based dataset - WD50K. Our experiments demonstrate that StarE based LP model outperforms existing approaches across multiple benchmarks. We also confirm that leveraging qualifiers is vital for link prediction with gains up to 25 MRR points compared to triple-based representations.
MLM: A Benchmark Dataset for Multitask Learning with Multiple Languages and Modalities
Sep 04, 2020
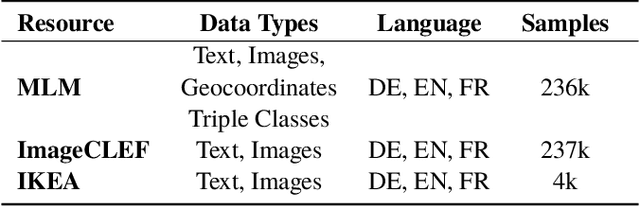
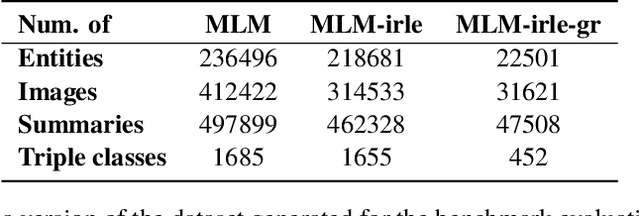
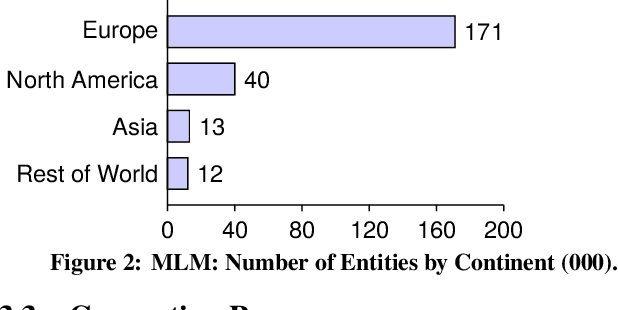
In this paper, we introduce the MLM (Multiple Languages and Modalities) dataset - a new resource to train and evaluate multitask systems on samples in multiple modalities and three languages. The generation process and inclusion of semantic data provide a resource that further tests the ability for multitask systems to learn relationships between entities. The dataset is designed for researchers and developers who build applications that perform multiple tasks on data encountered on the web and in digital archives. A second version of MLM provides a geo-representative subset of the data with weighted samples for countries of the European Union. We demonstrate the value of the resource in developing novel applications in the digital humanities with a motivating use case and specify a benchmark set of tasks to retrieve modalities and locate entities in the dataset. Evaluation of baseline multitask and single task systems on the full and geo-representative versions of MLM demonstrate the challenges of generalising on diverse data. In addition to the digital humanities, we expect the resource to contribute to research in multimodal representation learning, location estimation, and scene understanding.
PNEL: Pointer Network based End-To-End Entity Linking over Knowledge Graphs
Aug 31, 2020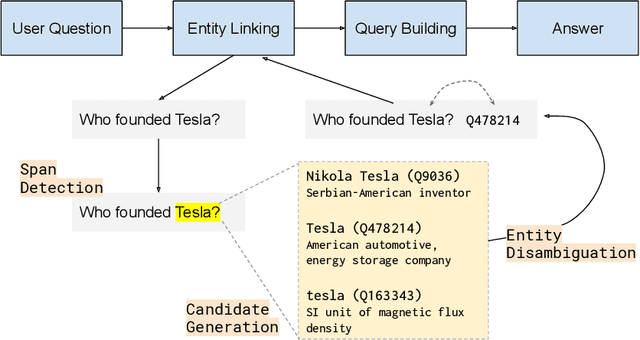
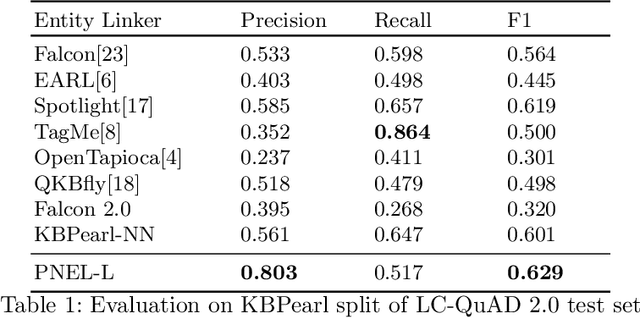
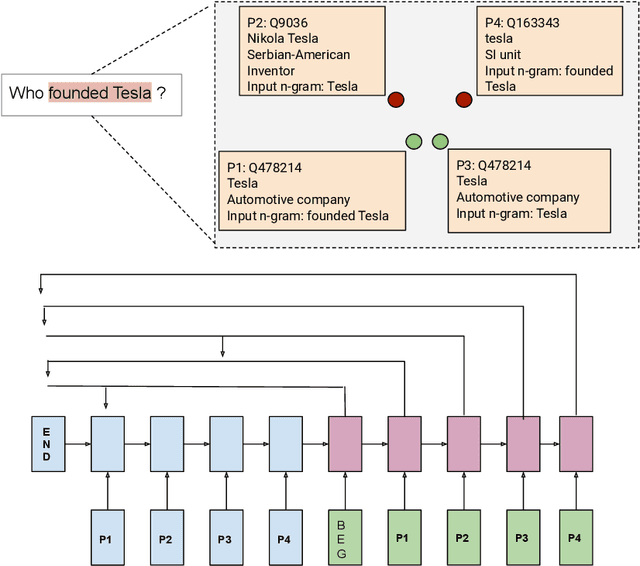
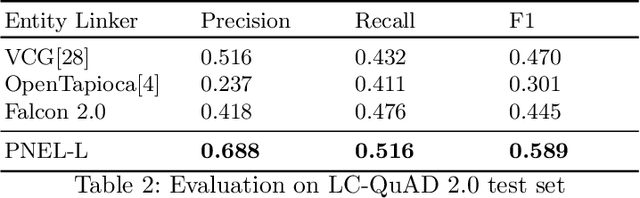
Question Answering systems are generally modelled as a pipeline consisting of a sequence of steps. In such a pipeline, Entity Linking (EL) is often the first step. Several EL models first perform span detection and then entity disambiguation. In such models errors from the span detection phase cascade to later steps and result in a drop of overall accuracy. Moreover, lack of gold entity spans in training data is a limiting factor for span detector training. Hence the movement towards end-to-end EL models began where no separate span detection step is involved. In this work we present a novel approach to end-to-end EL by applying the popular Pointer Network model, which achieves competitive performance. We demonstrate this in our evaluation over three datasets on the Wikidata Knowledge Graph.