 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Language Models to Generate, Validate, and Apply User Intent Taxonomies
Sep 14, 2023



Log data can reveal valuable information about how users interact with web search services, what they want, and how satisfied they are. However, analyzing user intents in log data is not easy, especially for new forms of web search such as AI-driven chat. To understand user intents from log data, we need a way to label them with meaningful categories that capture their diversity and dynamics. Existing methods rely on manual or ML-based labeling, which are either expensive or inflexible for large and changing datasets. We propose a novel solution using large language models (LLMs), which can generate rich and relevant concepts, descriptions, and examples for user intents. However, using LLMs to generate a user intent taxonomy and apply it to do log analysis can be problematic for two main reasons: such a taxonomy is not externally validated, and there may be an undesirable feedback loop. To overcome these issues, we propose a new methodology with human experts and assessors to verify the quality of the LLM-generated taxonomy. We also present an end-to-end pipeline that uses an LLM with human-in-the-loop to produce, refine, and use labels for user intent analysis in log data. Our method offers a scalable and adaptable way to analyze user intents in web-scale log data with minimal human effort. We demonstrate its effectiveness by uncovering new insights into user intents from search and chat logs from Bing.
Stationary Algorithmic Balancing For Dynamic Email Re-Ranking Problem
Aug 12, 2023



Email platforms need to generate personalized rankings of emails that satisfy user preferences, which may vary over time. We approach this as a recommendation problem based on three criteria: closeness (how relevant the sender and topic are to the user), timeliness (how recent the email is), and conciseness (how brief the email is). We propose MOSR (Multi-Objective Stationary Recommender), a novel online algorithm that uses an adaptive control model to dynamically balance these criteria and adapt to preference changes. We evaluate MOSR on the Enron Email Dataset, a large collection of real emails, and compare it with other baselines. The results show that MOSR achieves better performance, especially under non-stationary preferences, where users value different criteria more or less over time. We also test MOSR's robustness on a smaller down-sampled dataset that exhibits high variance in email characteristics, and show that it maintains stable rankings across different samples. Our work offers novel insights into how to design email re-ranking systems that account for multiple objectives impacting user satisfaction.
DYMOND: DYnamic MOtif-NoDes Network Generative Model
Aug 01, 2023Motifs, which have been established as building blocks for network structure, move beyond pair-wise connections to capture longer-range correlations in connections and activity. In spite of this, there are few generative graph models that consider higher-order network structures and even fewer that focus on using motifs in models of dynamic graphs. Most existing generative models for temporal graphs strictly grow the networks via edge addition, and the models are evaluated using static graph structure metrics -- which do not adequately capture the temporal behavior of the network. To address these issues, in this work we propose DYnamic MOtif-NoDes (DYMOND) -- a generative model that considers (i) the dynamic changes in overall graph structure using temporal motif activity and (ii) the roles nodes play in motifs (e.g., one node plays the hub role in a wedge, while the remaining two act as spokes). We compare DYMOND to three dynamic graph generative model baselines on real-world networks and show that DYMOND performs better at generating graph structure and node behavior similar to the observed network. We also propose a new methodology to adapt graph structure metrics to better evaluate the temporal aspect of the network. These metrics take into account the changes in overall graph structure and the individual nodes' behavior over time.
* In Proceedings of the Web Conference 2021 (WWW '21)
Generating Post-hoc Explanations for Skip-gram-based Node Embeddings by Identifying Important Nodes with Bridgeness
Apr 25, 2023



Node representation learning in a network is an important machine learning technique for encoding relational information in a continuous vector space while preserving the inherent properties and structures of the network. Recently, unsupervised node embedding methods such as DeepWalk, LINE, struc2vec, PTE, UserItem2vec, and RWJBG have emerged from the Skip-gram model and perform better performance in several downstream tasks such as node classification and link prediction than the existing relational models. However, providing post-hoc explanations of Skip-gram-based embeddings remains a challenging problem because of the lack of explanation methods and theoretical studies applicable for embeddings. In this paper, we first show that global explanations to the Skip-gram-based embeddings can be found by computing bridgeness under a spectral cluster-aware local perturbation. Moreover, a novel gradient-based explanation method, which we call GRAPH-wGD, is proposed that allows the top-q global explanations about learned graph embedding vectors more efficiently. Experiments show that the ranking of nodes by scores using GRAPH-wGD is highly correlated with true bridgeness scores. We also observe that the top-q node-level explanations selected by GRAPH-wGD have higher importance scores and produce more changes in class label prediction when perturbed, compared with the nodes selected by recent alternatives, using five real-world graphs.
Creating generalizable downstream graph models with random projections
Feb 17, 2023



We investigate graph representation learning approaches that enable models to generalize across graphs: given a model trained using the representations from one graph, our goal is to apply inference using those same model parameters when given representations computed over a new graph, unseen during model training, with minimal degradation in inference accuracy. This is in contrast to the more common task of doing inference on the unseen nodes of the same graph. We show that using random projections to estimate multiple powers of the transition matrix allows us to build a set of isomorphism-invariant features that can be used by a variety of tasks. The resulting features can be used to recover enough information about the local neighborhood of a node to enable inference with relevance competitive to other approaches while maintaining computational efficiency.
Federated Graph Representation Learning using Self-Supervision
Oct 27, 2022



Federated graph representation learning (FedGRL) brings the benefits of distributed training to graph structured data while simultaneously addressing some privacy and compliance concerns related to data curation. However, several interesting real-world graph data characteristics viz. label deficiency and downstream task heterogeneity are not taken into consideration in current FedGRL setups. In this paper, we consider a realistic and novel problem setting, wherein cross-silo clients have access to vast amounts of unlabeled data with limited or no labeled data and additionally have diverse downstream class label domains. We then propose a novel FedGRL formulation based on model interpolation where we aim to learn a shared global model that is optimized collaboratively using a self-supervised objective and gets downstream task supervision through local client models. We provide a specific instantiation of our general formulation using BGRL a SoTA self-supervised graph representation learning method and we empirically verify its effectiveness through realistic cross-slio datasets: (1) we adapt the Twitch Gamer Network which naturally simulates a cross-geo scenario and show that our formulation can provide consistent and avg. 6.1% gains over traditional supervised federated learning objectives and on avg. 1.7% gains compared to individual client specific self-supervised training and (2) we construct and introduce a new cross-silo dataset called Amazon Co-purchase Networks that have both the characteristics of the motivated problem setting. And, we witness on avg. 11.5% gains over traditional supervised federated learning and on avg. 1.9% gains over individually trained self-supervised models. Both experimental results point to the effectiveness of our proposed formulation. Finally, both our novel problem setting and dataset contributions provide new avenues for the research in FedGRL.
Lightweight Compositional Embeddings for Incremental Streaming Recommendation
Feb 04, 2022



Most work in graph-based recommender systems considers a {\em static} setting where all information about test nodes (i.e., users and items) is available upfront at training time. However, this static setting makes little sense for many real-world applications where data comes in continuously as a stream of new edges and nodes, and one has to update model predictions incrementally to reflect the latest state. To fully capitalize on the newly available data in the stream, recent graph-based recommendation models would need to be repeatedly retrained, which is infeasible in practice. In this paper, we study the graph-based streaming recommendation setting and propose a compositional recommendation model -- Lightweight Compositional Embedding (LCE) -- that supports incremental updates under low computational cost. Instead of learning explicit embeddings for the full set of nodes, LCE learns explicit embeddings for only a subset of nodes and represents the other nodes {\em implicitly}, through a composition function based on their interactions in the graph. This provides an effective, yet efficient, means to leverage streaming graph data when one node type (e.g., items) is more amenable to static representation. We conduct an extensive empirical study to compare LCE to a set of competitive baselines on three large-scale user-item recommendation datasets with interactions under a streaming setting. The results demonstrate the superior performance of LCE, showing that it achieves nearly skyline performance with significantly fewer parameters than alternative graph-based models.
Adversarial Graph Augmentation to Improve Graph Contrastive Learning
Jun 25, 2021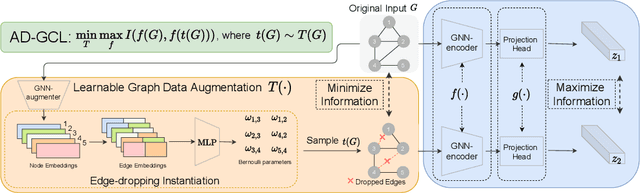
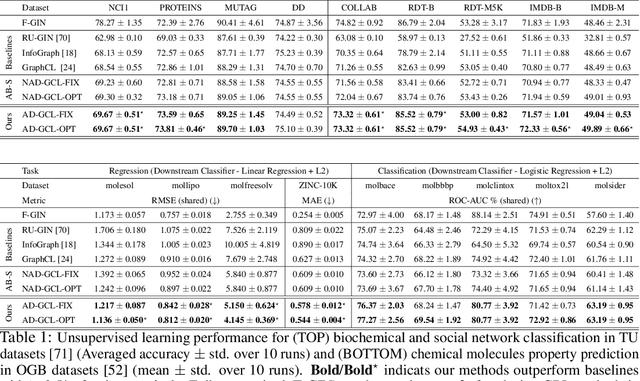
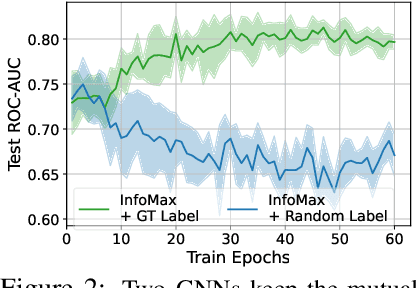
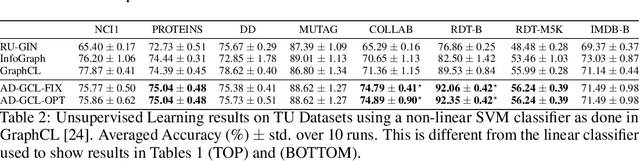
Self-supervised learning of graph neural networks (GNN) is in great need because of the widespread label scarcity issue in real-world graph/network data. Graph contrastive learning (GCL), by training GNNs to maximize the correspondence between the representations of the same graph in its different augmented forms, may yield robust and transferable GNNs even without using labels. However, GNNs trained by traditional GCL often risk capturing redundant graph features and thus may be brittle and provide sub-par performance in downstream tasks. Here, we propose a novel principle, termed adversarial-GCL (AD-GCL), which enables GNNs to avoid capturing redundant information during the training by optimizing adversarial graph augmentation strategies used in GCL. We pair AD-GCL with theoretical explanations and design a practical instantiation based on trainable edge-dropping graph augmentation. We experimentally validate AD-GCL by comparing with the state-of-the-art GCL methods and achieve performance gains of up-to $14\%$ in unsupervised, $6\%$ in transfer, and $3\%$ in semi-supervised learning settings overall with 18 different benchmark datasets for the tasks of molecule property regression and classification, and social network classification.
Breaking the Limit of Graph Neural Networks by Improving the Assortativity of Graphs with Local Mixing Patterns
Jun 11, 2021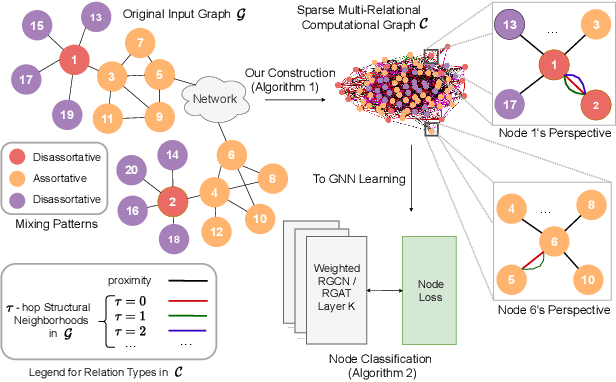
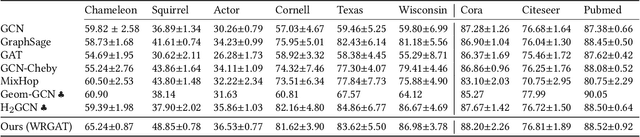
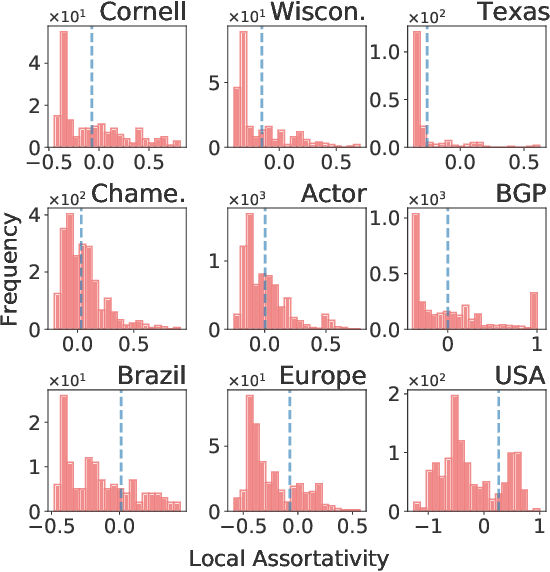
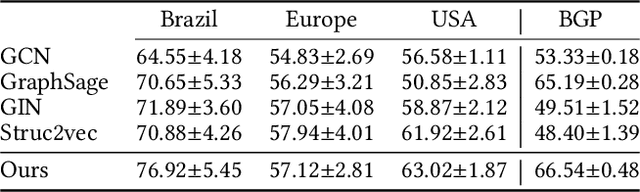
Graph neural networks (GNNs) have achieved tremendous success on multiple graph-based learning tasks by fusing network structure and node features. Modern GNN models are built upon iterative aggregation of neighbor's/proximity features by message passing. Its prediction performance has been shown to be strongly bounded by assortative mixing in the graph, a key property wherein nodes with similar attributes mix/connect with each other. We observe that real world networks exhibit heterogeneous or diverse mixing patterns and the conventional global measurement of assortativity, such as global assortativity coefficient, may not be a representative statistic in quantifying this mixing. We adopt a generalized concept, node-level assortativity, one that is based at the node level to better represent the diverse patterns and accurately quantify the learnability of GNNs. We find that the prediction performance of a wide range of GNN models is highly correlated with the node level assortativity. To break this limit, in this work, we focus on transforming the input graph into a computation graph which contains both proximity and structural information as distinct type of edges. The resulted multi-relational graph has an enhanced level of assortativity and, more importantly, preserves rich information from the original graph. We then propose to run GNNs on this computation graph and show that adaptively choosing between structure and proximity leads to improved performance under diverse mixing. Empirically, we show the benefits of adopting our transformation framework for semi-supervised node classification task on a variety of real world graph learning benchmarks.
ReadNet: A Hierarchical Transformer Framework for Web Article Readability Analysis
Mar 06, 2021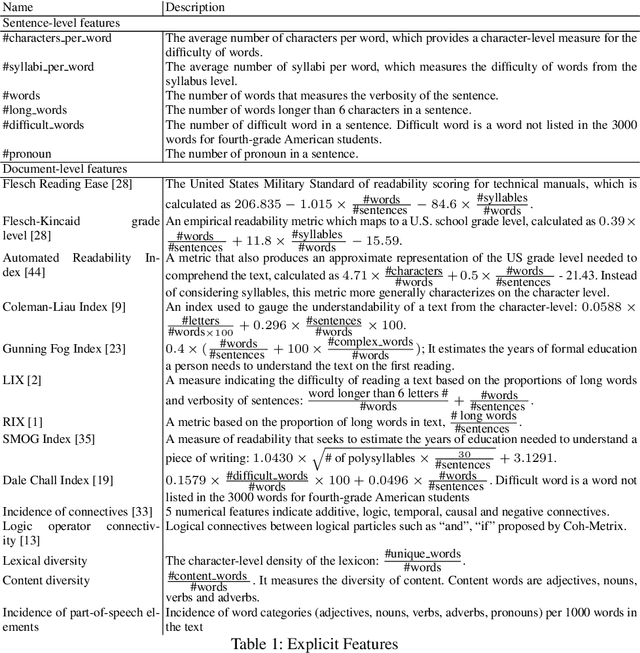
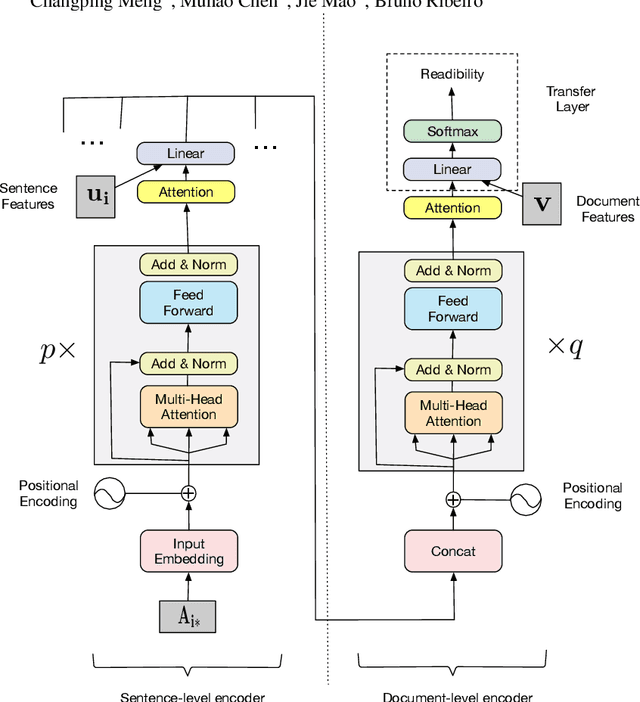
Analyzing the readability of articles has been an important sociolinguistic task. Addressing this task is necessary to the automatic recommendation of appropriate articles to readers with different comprehension abilities, and it further benefits education systems, web information systems, and digital libraries. Current methods for assessing readability employ empirical measures or statistical learning techniques that are limited by their ability to characterize complex patterns such as article structures and semantic meanings of sentences. In this paper, we propose a new and comprehensive framework which uses a hierarchical self-attention model to analyze document readability. In this model, measurements of sentence-level difficulty are captured along with the semantic meanings of each sentence. Additionally, the sentence-level features are incorporated to characterize the overall readability of an article with consideration of article structures. We evaluate our proposed approach on three widely-used benchmark datasets against several strong baseline approaches. Experimental results show that our proposed method achieves the state-of-the-art performance on estimating the readability for various web articles and literature.