 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinnish Paraphrase Corpus
Mar 24, 2021
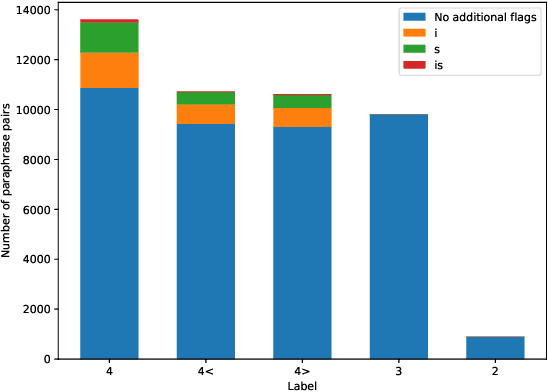

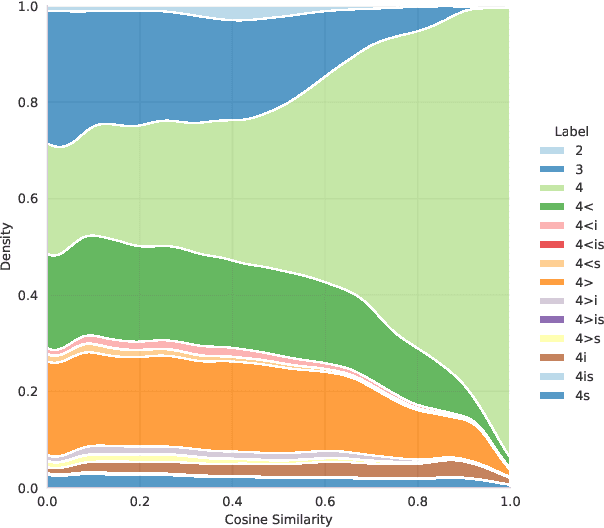
In this paper, we introduce the first fully manually annotated paraphrase corpus for Finnish containing 53,572 paraphrase pairs harvested from alternative subtitles and news headings. Out of all paraphrase pairs in our corpus 98% are manually classified to be paraphrases at least in their given context, if not in all contexts. Additionally, we establish a manual candidate selection method and demonstrate its feasibility in high quality paraphrase selection in terms of both cost and quality.
Towards Fully Bilingual Deep Language Modeling
Oct 22, 2020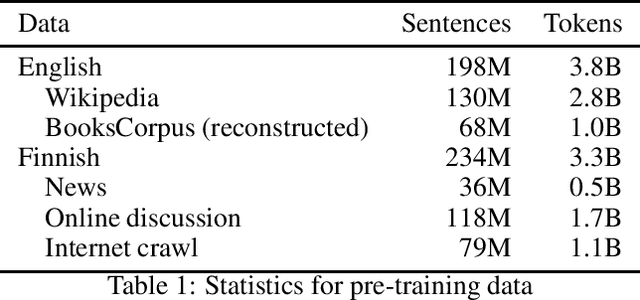


Language models based on deep neural networks have facilitated great advances in natural language processing and understanding tasks in recent years. While models covering a large number of languages have been introduced, their multilinguality has come at a cost in terms of monolingual performance, and the best-performing models at most tasks not involving cross-lingual transfer remain monolingual. In this paper, we consider the question of whether it is possible to pre-train a bilingual model for two remotely related languages without compromising performance at either language. We collect pre-training data, create a Finnish-English bilingual BERT model and evaluate its performance on datasets used to evaluate the corresponding monolingual models. Our bilingual model performs on par with Google's original English BERT on GLUE and nearly matches the performance of monolingual Finnish BERT on a range of Finnish NLP tasks, clearly outperforming multilingual BERT. We find that when the model vocabulary size is increased, the BERT-Base architecture has sufficient capacity to learn two remotely related languages to a level where it achieves comparable performance with monolingual models, demonstrating the feasibility of training fully bilingual deep language models. The model and all tools involved in its creation are freely available at https://github.com/TurkuNLP/biBERT
WikiBERT models: deep transfer learning for many languages
Jun 02, 2020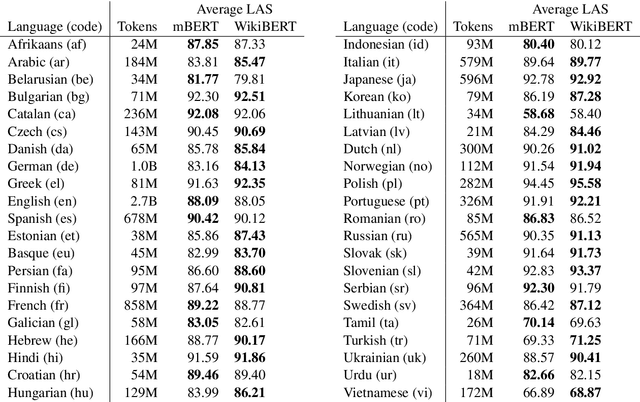
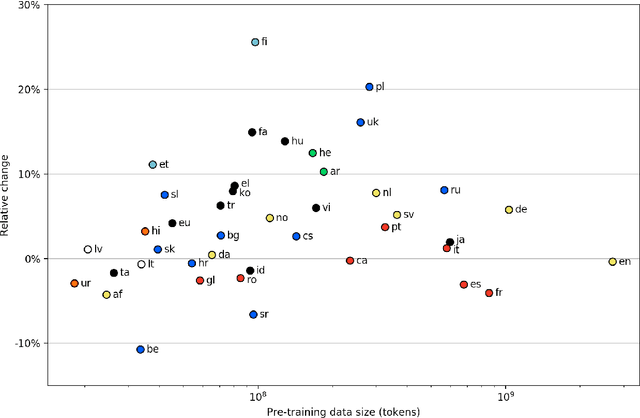
Deep neural language models such as BERT have enabled substantial recent advances in many natural language processing tasks. Due to the effort and computational cost involved in their pre-training, language-specific models are typically introduced only for a small number of high-resource languages such as English. While multilingual models covering large numbers of languages are available, recent work suggests monolingual training can produce better models, and our understanding of the tradeoffs between mono- and multilingual training is incomplete. In this paper, we introduce a simple, fully automated pipeline for creating language-specific BERT models from Wikipedia data and introduce 42 new such models, most for languages up to now lacking dedicated deep neural language models. We assess the merits of these models using the state-of-the-art UDify parser on Universal Dependencies data, contrasting performance with results using the multilingual BERT model. We find that UDify using WikiBERT models outperforms the parser using mBERT on average, with the language-specific models showing substantially improved performance for some languages, yet limited improvement or a decrease in performance for others. We also present preliminary results as first steps toward an understanding of the conditions under which language-specific models are most beneficial. All of the methods and models introduced in this work are available under open licenses from https://github.com/turkunlp/wikibert.
Multilingual is not enough: BERT for Finnish
Dec 15, 2019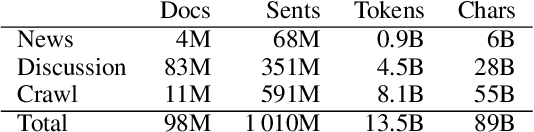
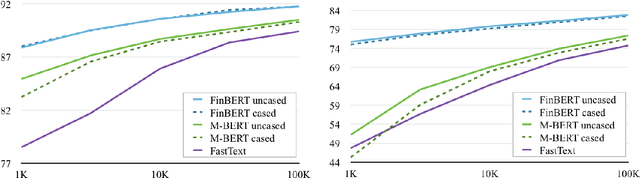
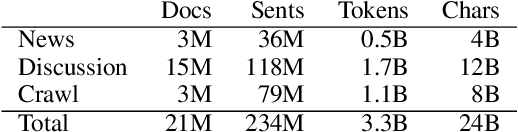
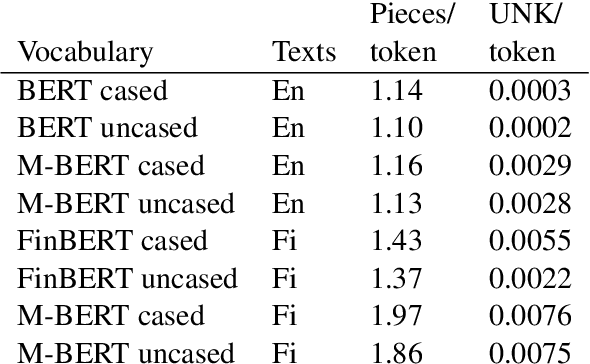
Deep learning-based language models pretrained on large unannotated text corpora have been demonstrated to allow efficient transfer learning for natural language processing, with recent approaches such as the transformer-based BERT model advancing the state of the art across a variety of tasks. While most work on these models has focused on high-resource languages, in particular English, a number of recent efforts have introduced multilingual models that can be fine-tuned to address tasks in a large number of different languages. However, we still lack a thorough understanding of the capabilities of these models, in particular for lower-resourced languages. In this paper, we focus on Finnish and thoroughly evaluate the multilingual BERT model on a range of tasks, comparing it with a new Finnish BERT model trained from scratch. The new language-specific model is shown to systematically and clearly outperform the multilingual. While the multilingual model largely fails to reach the performance of previously proposed methods, the custom Finnish BERT model establishes new state-of-the-art results on all corpora for all reference tasks: part-of-speech tagging, named entity recognition, and dependency parsing. We release the model and all related resources created for this study with open licenses at https://turkunlp.org/finbert .
Morphological Tagging and Lemmatization of Albanian: A Manually Annotated Corpus and Neural Models
Dec 02, 2019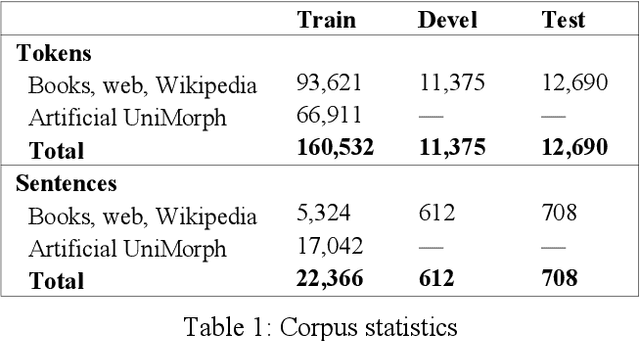
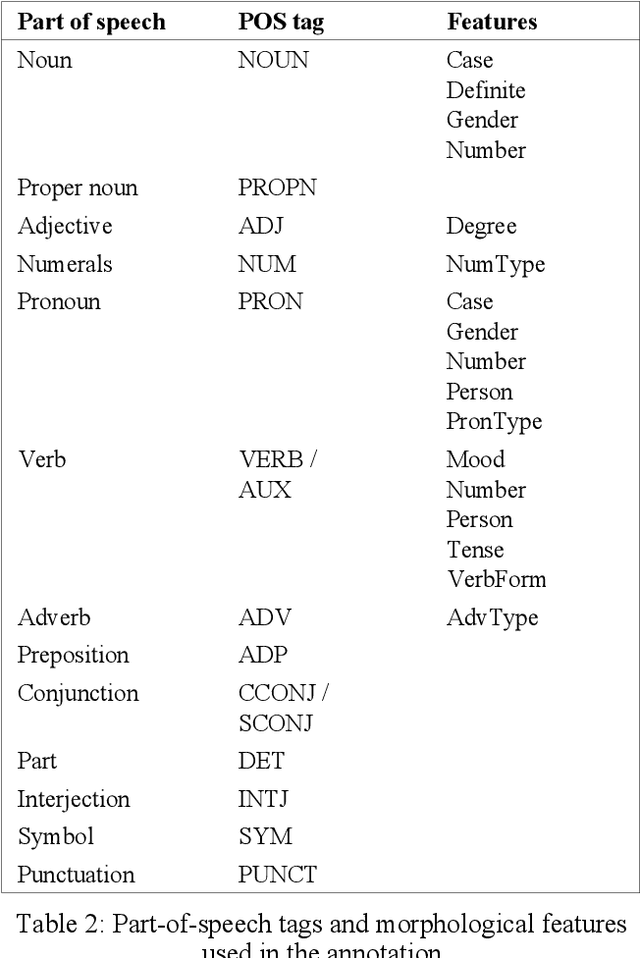

In this paper, we present the first publicly available part-of-speech and morphologically tagged corpus for the Albanian language, as well as a neural morphological tagger and lemmatizer trained on it. There is currently a lack of available NLP resources for Albanian, and its complex grammar and morphology present challenges to their development. We have created an Albanian part-of-speech corpus based on the Universal Dependencies schema for morphological annotation, containing about 118,000 tokens of naturally occuring text collected from different text sources, with an addition of 67,000 tokens of artificially created simple sentences used only in training. On this corpus, we subsequently train and evaluate segmentation, morphological tagging and lemmatization models, using the Turku Neural Parser Pipeline. On the held-out evaluation set, the model achieves 92.74% accuracy on part-of-speech tagging, 85.31% on morphological tagging, and 89.95% on lemmatization. The manually annotated corpus, as well as the trained models are available under an open license.
Is Multilingual BERT Fluent in Language Generation?
Oct 09, 2019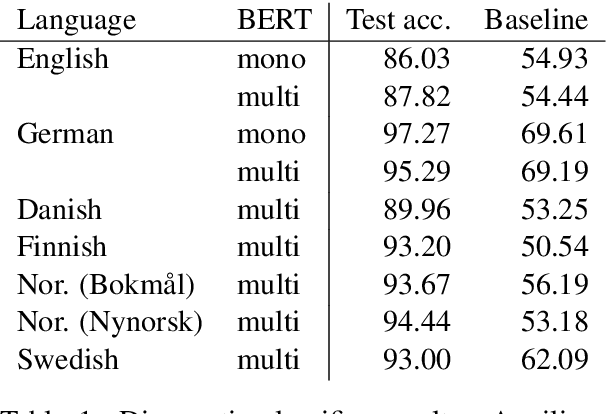


The multilingual BERT model is trained on 104 languages and meant to serve as a universal language model and tool for encoding sentences. We explore how well the model performs on several languages across several tasks: a diagnostic classification probing the embeddings for a particular syntactic property, a cloze task testing the language modelling ability to fill in gaps in a sentence, and a natural language generation task testing for the ability to produce coherent text fitting a given context. We find that the currently available multilingual BERT model is clearly inferior to the monolingual counterparts, and cannot in many cases serve as a substitute for a well-trained monolingual model. We find that the English and German models perform well at generation, whereas the multilingual model is lacking, in particular, for Nordic languages.
Template-free Data-to-Text Generation of Finnish Sports News
Oct 04, 2019
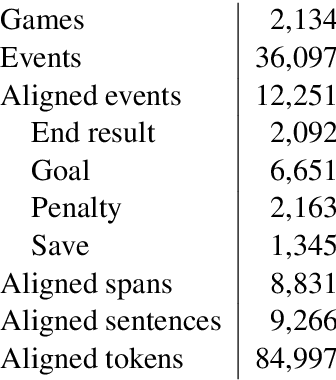
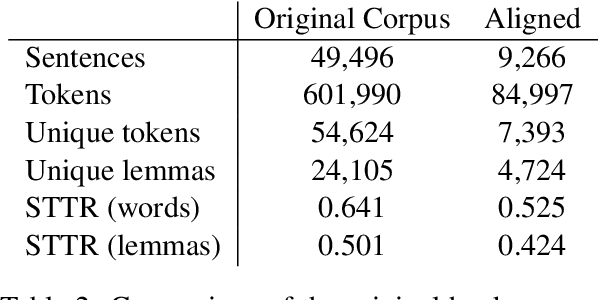
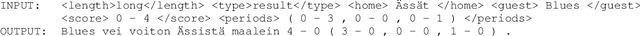
News articles such as sports game reports are often thought to closely follow the underlying game statistics, but in practice they contain a notable amount of background knowledge, interpretation, insight into the game, and quotes that are not present in the official statistics. This poses a challenge for automated data-to-text news generation with real-world news corpora as training data. We report on the development of a corpus of Finnish ice hockey news, edited to be suitable for training of end-to-end news generation methods, as well as demonstrate generation of text, which was judged by journalists to be relatively close to a viable product. The new dataset and system source code are available for research purposes at https://github.com/scoopmatic/finnish-hockey-news-generation-paper.
Universal Lemmatizer: A Sequence to Sequence Model for Lemmatizing Universal Dependencies Treebanks
Feb 03, 2019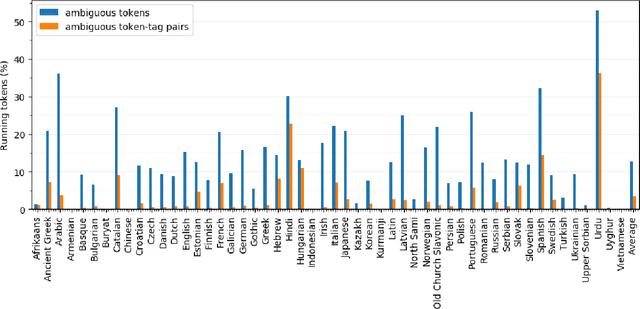
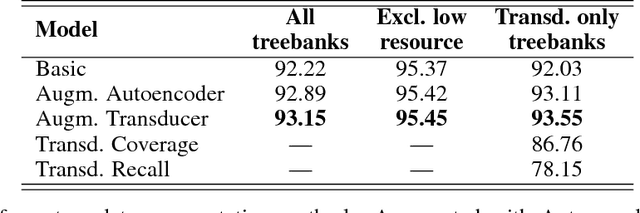
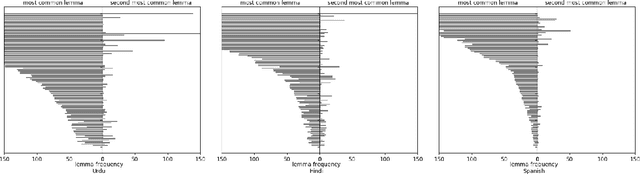
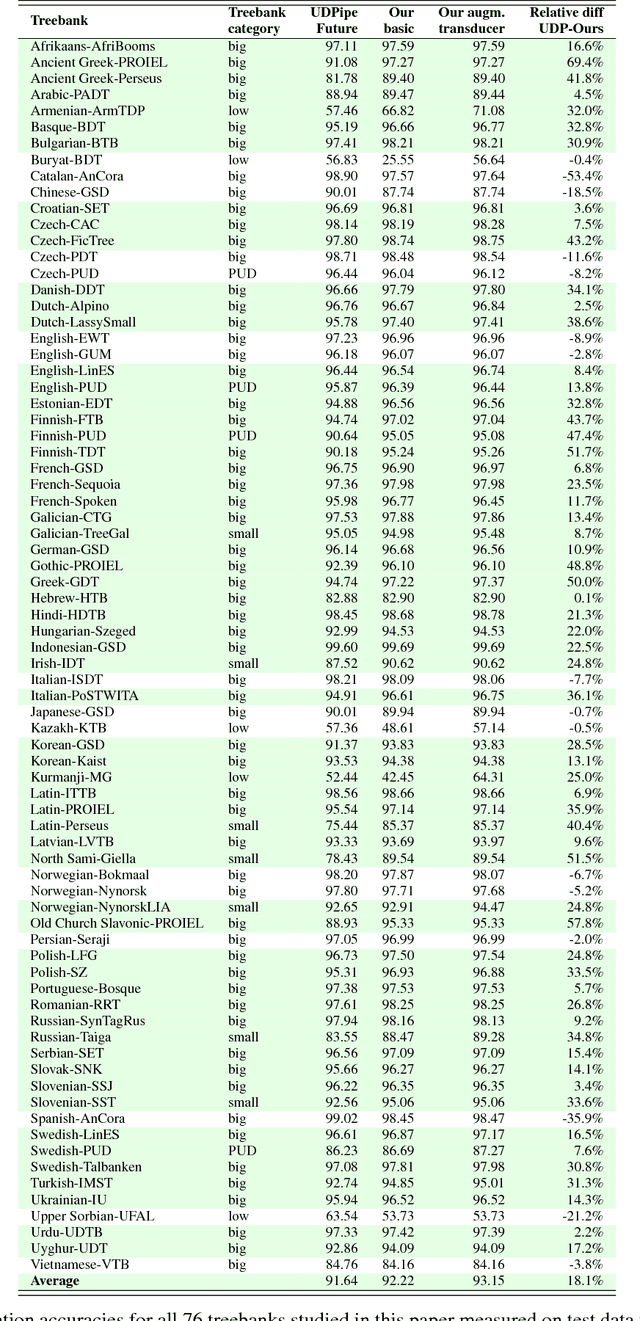
In this paper we present a novel lemmatization method based on a sequence-to-sequence neural network architecture and morphosyntactic context representation. In the proposed method, our context-sensitive lemmatizer generates the lemma one character at a time based on the surface form characters and its morphosyntactic features obtained from a morphological tagger. We argue that a sliding window context representation suffers from sparseness, while in majority of cases the morphosyntactic features of a word bring enough information to resolve lemma ambiguities while keeping the context representation dense and more practical for machine learning systems. Additionally, we study two different data augmentation methods utilizing autoencoder training and morphological transducers especially beneficial for low resource languages. We evaluate our lemmatizer on 52 different languages and 76 different treebanks, showing that our system outperforms all latest baseline systems. Compared to the best overall baseline, UDPipe Future, our system outperforms it on 60 out of 76 treebanks reducing errors on average by 18% relative. The lemmatizer together with all trained models is made available as a part of the Turku-neural-parsing-pipeline under the Apache 2.0 license.