 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInput Dropout for Spatially Aligned Modalities
Feb 07, 2020



Computer vision datasets containing multiple modalities such as color, depth, and thermal properties are now commonly accessible and useful for solving a wide array of challenging tasks. However, deploying multi-sensor heads is not possible in many scenarios. As such many practical solutions tend to be based on simpler sensors, mostly for cost, simplicity and robustness considerations. In this work, we propose a training methodology to take advantage of these additional modalities available in datasets, even if they are not available at test time. By assuming that the modalities have a strong spatial correlation, we propose Input Dropout, a simple technique that consists in stochastic hiding of one or many input modalities at training time, while using only the canonical (e.g. RGB) modalities at test time. We demonstrate that Input Dropout trivially combines with existing deep convolutional architectures, and improves their performance on a wide range of computer vision tasks such as dehazing, 6-DOF object tracking, pedestrian detection and object classification.
Associative Alignment for Few-shot Image Classification
Dec 11, 2019
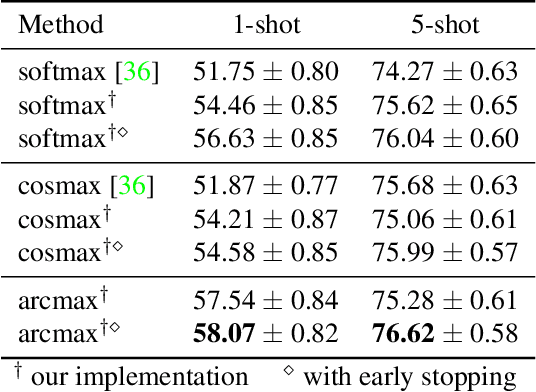

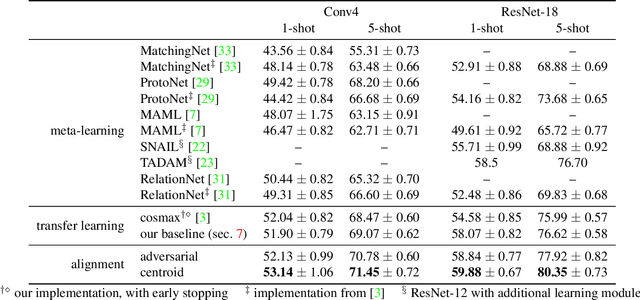
Few-shot image classification aims at training a model by using only a few (e.g., 5 or even 1) examples of novel classes. The established way of doing so is to rely on a larger set of base data for either pre-training a model, or for training in a meta-learning context. Unfortunately, these approaches often suffer from overfitting since the models can easily memorize all of the novel samples. This paper mitigates this issue and proposes to leverage part of the base data by aligning the novel training instances to the closely related ones in the base training set. This expands the size of the effective novel training set by adding extra related base instances to the few novel ones, thereby allowing to train the entire network. Doing so limits overfitting and simultaneously strengthens the generalization capabilities of the network. We propose two associative alignment strategies: 1) a conditional adversarial alignment loss based on the Wasserstein distance; and 2) a metric-learning loss for minimizing the distance between related base samples and the centroid of novel instances in the feature space. Experiments on two standard datasets demonstrate that combining our centroid-based alignment loss results in absolute accuracy improvements of 4.4%, 1.2%, and 6.0% in 5-shot learning over the state of the art for object recognition, fine-grained classification, and cross-domain adaptation, respectively.
Learning to Match Templates for Unseen Instance Detection
Nov 26, 2019



Detecting objects in images is a quintessential problem in computer vision. Much of the focus in the literature has been on the problem of identifying the bounding box of a particular type of objects in an image. Yet, in many contexts such as robotics and augmented reality, it is more important to find a specific object instance---a unique toy or a custom industrial part for example---rather than a generic object class. Here, applications can require a rapid shift from one object instance to another, thus requiring fast turnaround which affords little-to-no training time. In this context, we propose a method for detecting objects that are unknown at training time. Our approach frames the problem as one of learned template matching, where a network is trained to match the template of an object in an image. The template is obtained by rendering a textured 3D model of the object. At test time, we provide a novel 3D object, and the network is able to successfully detect it, even under significant occlusion. Our method offers an improvement of almost 30 mAP over the previous template matching methods on the challenging Occluded Linemod (overall mAP of 50.7). With no access to the objects at training time, our method still yields detection results that are on par with existing ones that are allowed to train on the objects. By reviving this research direction in the context of more powerful, deep feature extractors, our work sets the stage for more development in the area of unseen object instance detection.
Deep Parametric Indoor Lighting Estimation
Oct 19, 2019

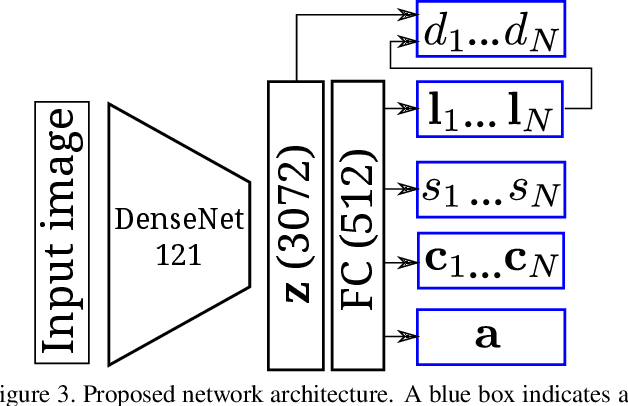

We present a method to estimate lighting from a single image of an indoor scene. Previous work has used an environment map representation that does not account for the localized nature of indoor lighting. Instead, we represent lighting as a set of discrete 3D lights with geometric and photometric parameters. We train a deep neural network to regress these parameters from a single image, on a dataset of environment maps annotated with depth. We propose a differentiable layer to convert these parameters to an environment map to compute our loss; this bypasses the challenge of establishing correspondences between estimated and ground truth lights. We demonstrate, via quantitative and qualitative evaluations, that our representation and training scheme lead to more accurate results compared to previous work, while allowing for more realistic 3D object compositing with spatially-varying lighting.
Physics-Based Rendering for Improving Robustness to Rain
Aug 27, 2019
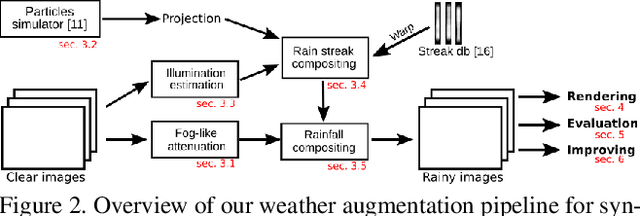
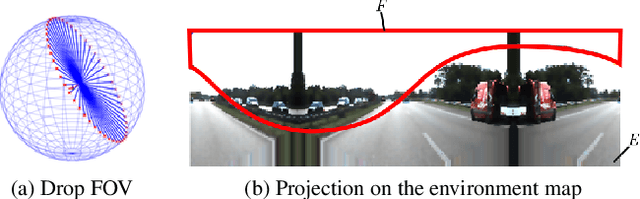

To improve the robustness to rain, we present a physically-based rain rendering pipeline for realistically inserting rain into clear weather images. Our rendering relies on a physical particle simulator, an estimation of the scene lighting and an accurate rain photometric modeling to augment images with arbitrary amount of realistic rain or fog. We validate our rendering with a user study, proving our rain is judged 40% more realistic that state-of-the-art. Using our generated weather augmented Kitti and Cityscapes dataset, we conduct a thorough evaluation of deep object detection and semantic segmentation algorithms and show that their performance decreases in degraded weather, on the order of 15% for object detection and 60% for semantic segmentation. Furthermore, we show refining existing networks with our augmented images improves the robustness of both object detection and semantic segmentation algorithms. We experiment on nuScenes and measure an improvement of 15% for object detection and 35% for semantic segmentation compared to original rainy performance. Augmented databases and code are available on the project page.
All-Weather Deep Outdoor Lighting Estimation
Jun 12, 2019
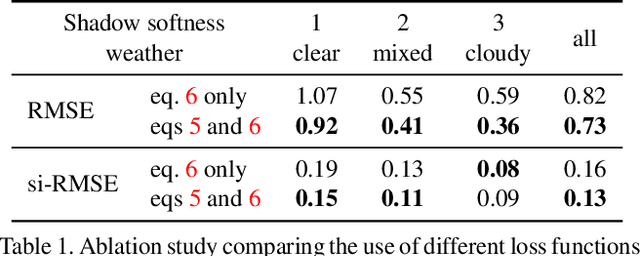
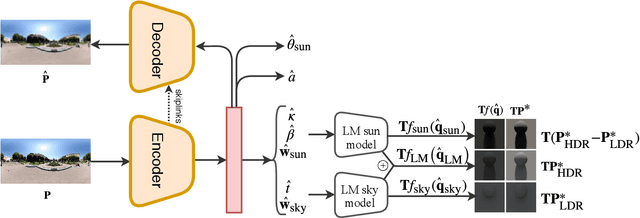
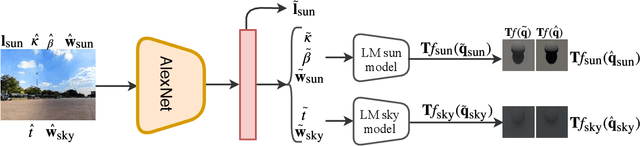
We present a neural network that predicts HDR outdoor illumination from a single LDR image. At the heart of our work is a method to accurately learn HDR lighting from LDR panoramas under any weather condition. We achieve this by training another CNN (on a combination of synthetic and real images) to take as input an LDR panorama, and regress the parameters of the Lalonde-Matthews outdoor illumination model. This model is trained such that it a) reconstructs the appearance of the sky, and b) renders the appearance of objects lit by this illumination. We use this network to label a large-scale dataset of LDR panoramas with lighting parameters and use them to train our single image outdoor lighting estimation network. We demonstrate, via extensive experiments, that both our panorama and single image networks outperform the state of the art, and unlike prior work, are able to handle weather conditions ranging from fully sunny to overcast skies.
Fast Spatially-Varying Indoor Lighting Estimation
Jun 10, 2019
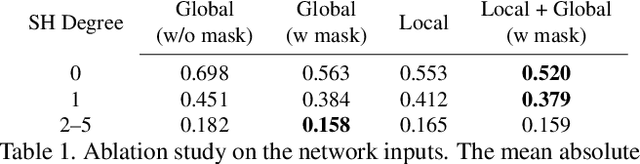
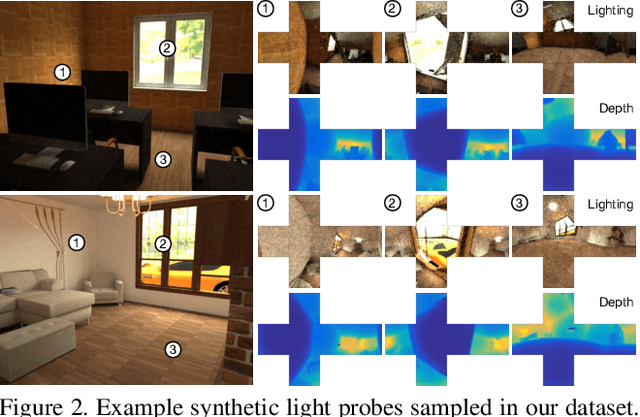
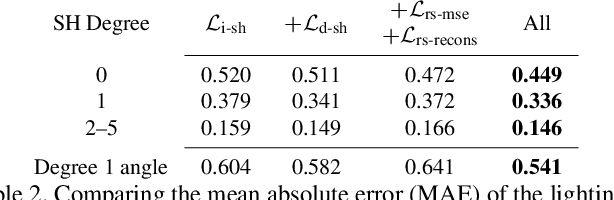
We propose a real-time method to estimate spatiallyvarying indoor lighting from a single RGB image. Given an image and a 2D location in that image, our CNN estimates a 5th order spherical harmonic representation of the lighting at the given location in less than 20ms on a laptop mobile graphics card. While existing approaches estimate a single, global lighting representation or require depth as input, our method reasons about local lighting without requiring any geometry information. We demonstrate, through quantitative experiments including a user study, that our results achieve lower lighting estimation errors and are preferred by users over the state-of-the-art. Our approach can be used directly for augmented reality applications, where a virtual object is relit realistically at any position in the scene in real-time.
* CVPR19
Structural Decompositions for End-to-End Relighting
Jun 07, 2019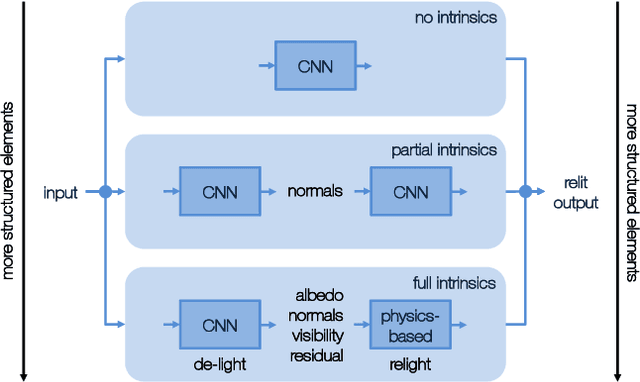
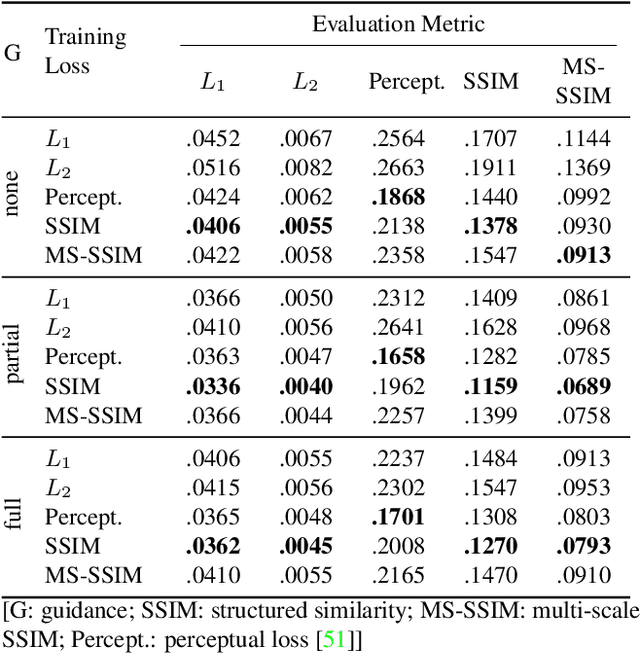

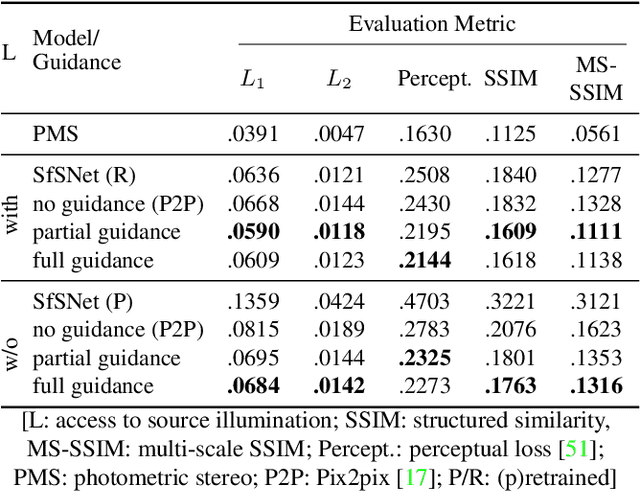
Relighting is an essential step in artificially transferring an object from one image into another environment. For example, a believable teleconference in Augmented Reality requires a portrait recorded in the source environment to be displayed and relit consistent with the light configuration of the destination scene. In this paper, we investigate architectures for learning to both de-light and relight an image of a human face end-to-end. The architectures vary in how much they enforce physically-based image formation and rendering constraints. The most structured model decomposes the input image into intrinsic components according to a diffuse physics-based image formation model and augments the render to relight including non-diffuse effects. An intermediate model uses fewer intrinsic constraints and the least structured model makes no assumptions on the image formation. To train our models and evaluate the approach, we collected portraits of 21 subjects with various expressions and poses, each in a sequence of 32 individual light sources in a controlled light stage setup. Our method leads to precise and believable relighting results in challenging illumination conditions and poses, including when the subject is facing away from the camera. We compare our method to state-of-the-art relighting approaches and illustrate its superiority in a series of quantitative and qualitative experiments.
Deep Sky Modeling for Single Image Outdoor Lighting Estimation
May 10, 2019



We propose a data-driven learned sky model, which we use for outdoor lighting estimation from a single image. As no large-scale dataset of images and their corresponding ground truth illumination is readily available, we use complementary datasets to train our approach, combining the vast diversity of illumination conditions of SUN360 with the radiometrically calibrated and physically accurate Laval HDR sky database. Our key contribution is to provide a holistic view of both lighting modeling and estimation, solving both problems end-to-end. From a test image, our method can directly estimate an HDR environment map of the lighting without relying on analytical lighting models. We demonstrate the versatility and expressivity of our learned sky model and show that it can be used to recover plausible illumination, leading to visually pleasant virtual object insertions. To further evaluate our method, we capture a dataset of HDR 360{\deg} panoramas and show through extensive validation that we significantly outperform previous state-of-the-art.
Deep Photovoltaic Nowcasting
Oct 15, 2018Predicting the short-term power output of a photovoltaic panel is an important task for the efficient management of smart grids. Short-term forecasting at the minute scale, also known as nowcasting, can benefit from sky images captured by regular cameras and installed close to the solar panel. However, estimating the weather conditions from these images---sun intensity, cloud appearance and movement, etc.---is a very challenging task that the community has yet to solve with traditional computer vision techniques. In this work, we propose to learn the relationship between sky appearance and the future photovoltaic power output using deep learning. We train several variants of convolutional neural networks which take historical photovoltaic power values and sky images as input and estimate photovoltaic power in a very short term future. In particular, we compare three different architectures based on: a multi-layer perceptron (MLP), a convolutional neural network (CNN), and a long short term memory (LSTM) module. We evaluate our approach quantitatively on a dataset of photovoltaic power values and corresponding images gathered in Kyoto, Japan. Our experiments reveal that the MLP network, already used similarly in previous work, achieves an RMSE skill score of 7% over the commonly-used persistence baseline on the 1-minute future photovoltaic power prediction task. Our CNN-based network improves upon this with a 12% skill score. In contrast, our LSTM-based model, which can learn the temporal dependencies in the data, achieves a 21% RMSE skill score, thus outperforming all other approaches.