 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Evidence-Based Nudges in Biomedical Literature with Large Language Models
Feb 10, 2026We present a scalable, AI-powered system that identifies and extracts evidence-based behavioral nudges from unstructured biomedical literature. Nudges are subtle, non-coercive interventions that influence behavior without limiting choice, showing strong impact on health outcomes like medication adherence. However, identifying these interventions from PubMed's 8 million+ articles is a bottleneck. Our system uses a novel multi-stage pipeline: first, hybrid filtering (keywords, TF-IDF, cosine similarity, and a "nudge-term bonus") reduces the corpus to about 81,000 candidates. Second, we use OpenScholar (quantized LLaMA 3.1 8B) to classify papers and extract structured fields like nudge type and target behavior in a single pass, validated against a JSON schema. We evaluated four configurations on a labeled test set (N=197). The best setup (Title/Abstract/Intro) achieved a 67.0% F1 score and 72.0% recall, ideal for discovery. A high-precision variant using self-consistency (7 randomized passes) achieved 100% precision with 12% recall, demonstrating a tunable trade-off for high-trust use cases. This system is being integrated into Agile Nudge+, a real-world platform, to ground LLM-generated interventions in peer-reviewed evidence. This work demonstrates interpretable, domain-specific retrieval pipelines for evidence synthesis and personalized healthcare.
Semi-supervised Learning for Dense Object Detection in Retail Scenes
Jul 05, 2021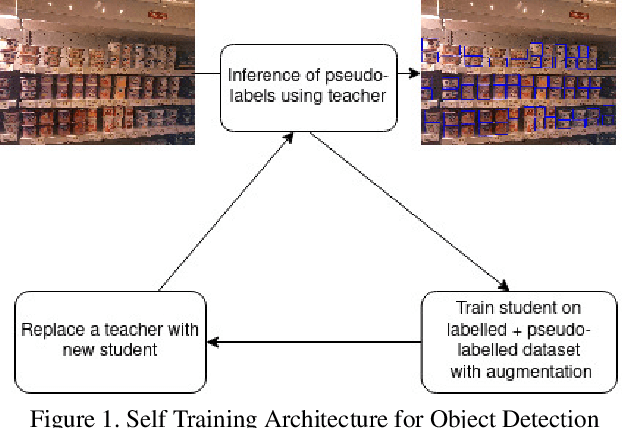
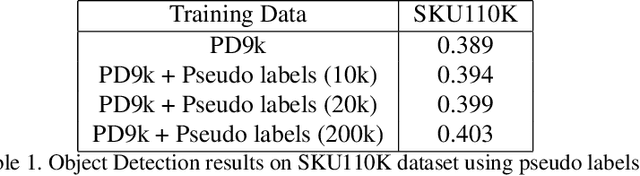
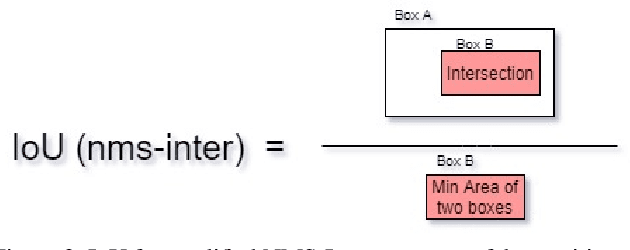
Retail scenes usually contain densely packed high number of objects in each image. Standard object detection techniques use fully supervised training methodology. This is highly costly as annotating a large dense retail object detection dataset involves an order of magnitude more effort compared to standard datasets. Hence, we propose semi-supervised learning to effectively use the large amount of unlabeled data available in the retail domain. We adapt a popular self supervised method called noisy student initially proposed for object classification to the task of dense object detection. We show that using unlabeled data with the noisy student training methodology, we can improve the state of the art on precise detection of objects in densely packed retail scenes. We also show that performance of the model increases as you increase the amount of unlabeled data.