 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Look at the Effect of Sample Design on Generalization through the Lens of Spectral Analysis
Jun 08, 2019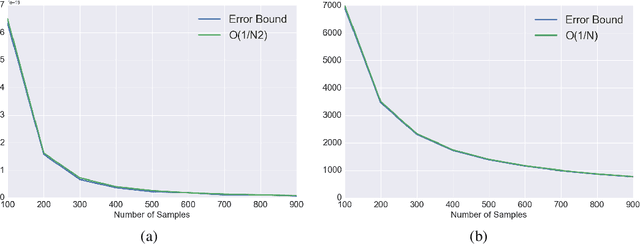
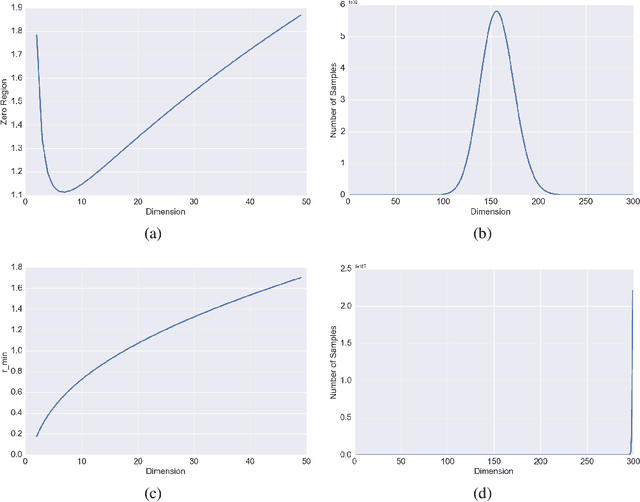
This paper provides a general framework to study the effect of sampling properties of training data on the generalization error of the learned machine learning (ML) models. Specifically, we propose a new spectral analysis of the generalization error, expressed in terms of the power spectra of the sampling pattern and the function involved. The framework is build in the Euclidean space using Fourier analysis and establishes a connection between some high dimensional geometric objects and optimal spectral form of different state-of-the-art sampling patterns. Subsequently, we estimate the expected error bounds and convergence rate of different state-of-the-art sampling patterns, as the number of samples and dimensions increase. We make several observations about generalization error which are valid irrespective of the approximation scheme (or learning architecture) and training (or optimization) algorithms. Our result also sheds light on ways to formulate design principles for constructing optimal sampling methods for particular problems.
Audio Source Separation via Multi-Scale Learning with Dilated Dense U-Nets
Apr 08, 2019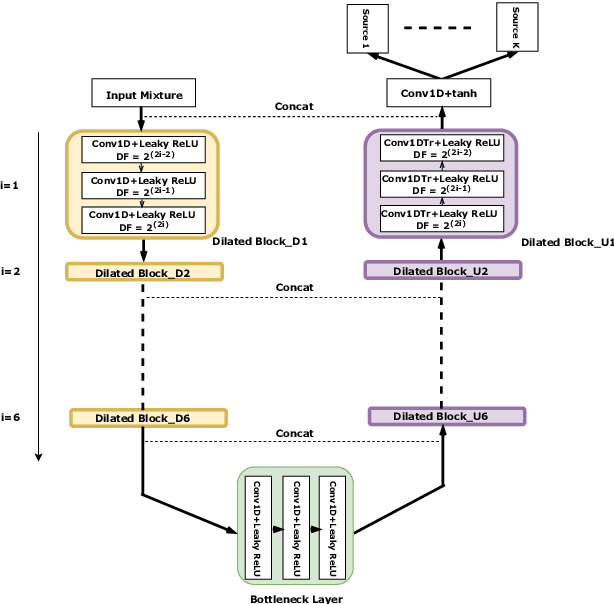
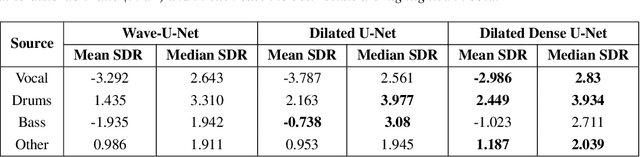
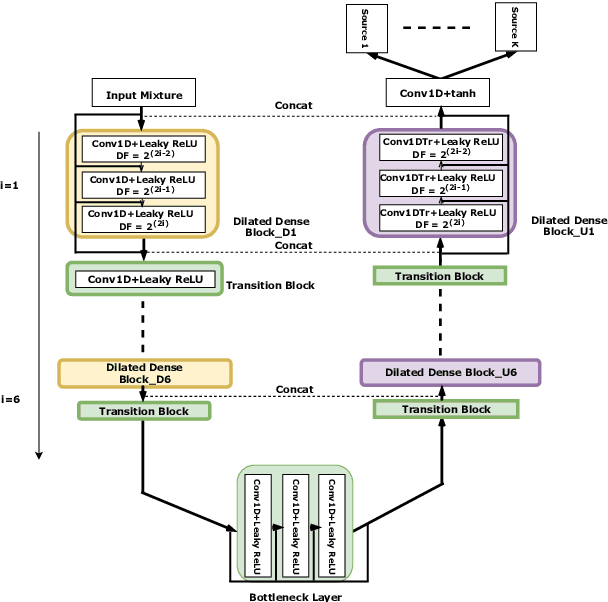
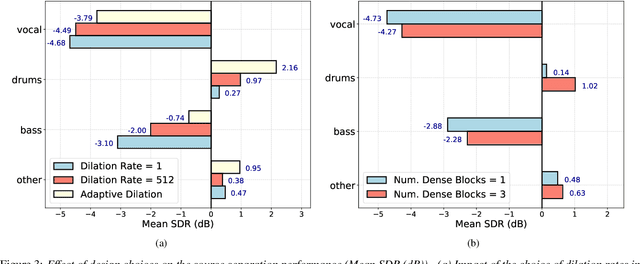
Modern audio source separation techniques rely on optimizing sequence model architectures such as, 1D-CNNs, on mixture recordings to generalize well to unseen mixtures. Specifically, recent focus is on time-domain based architectures such as Wave-U-Net which exploit temporal context by extracting multi-scale features. However, the optimality of the feature extraction process in these architectures has not been well investigated. In this paper, we examine and recommend critical architectural changes that forge an optimal multi-scale feature extraction process. To this end, we replace regular $1-$D convolutions with adaptive dilated convolutions that have innate capability of capturing increased context by using large temporal receptive fields. We also investigate the impact of dense connections on the extraction process that encourage feature reuse and better gradient flow. The dense connections between the downsampling and upsampling paths of a U-Net architecture capture multi-resolution information leading to improved temporal modelling. We evaluate the proposed approaches on the MUSDB test dataset. In addition to providing an improved performance over the state-of-the-art, we also provide insights on the impact of different architectural choices on complex data-driven solutions for source separation.
MimicGAN: Corruption-Mimicking for Blind Image Recovery & Adversarial Defense
Nov 20, 2018
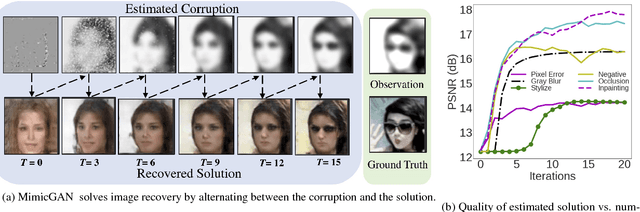

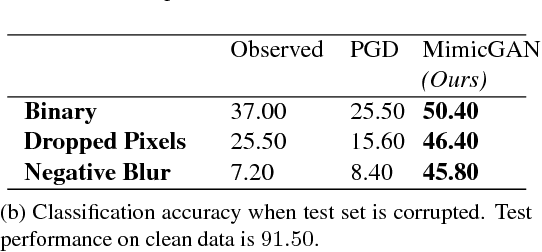
Solving inverse problems continues to be a central challenge in computer vision. Existing techniques either explicitly construct an inverse mapping using prior knowledge about the corruption, or learn the inverse directly using a large collection of examples. However, in practice, the nature of corruption may be unknown, and thus it is challenging to regularize the problem of inferring a plausible solution. On the other hand, collecting task-specific training data is tedious for known corruptions and impossible for unknown ones. We present MimicGAN, an unsupervised technique to solve general inverse problems based on image priors in the form of generative adversarial networks (GANs). Using a GAN prior, we show that one can reliably recover solutions to underdetermined inverse problems through a surrogate network that learns to mimic the corruption at test time. Our system successively estimates the corruption and the clean image without the need for supervisory training, while outperforming existing baselines in blind image recovery. We also demonstrate that MimicGAN improves upon recent GAN-based defenses against adversarial attacks and represents one of the strongest test-time defenses available today.
Multiple Subspace Alignment Improves Domain Adaptation
Nov 11, 2018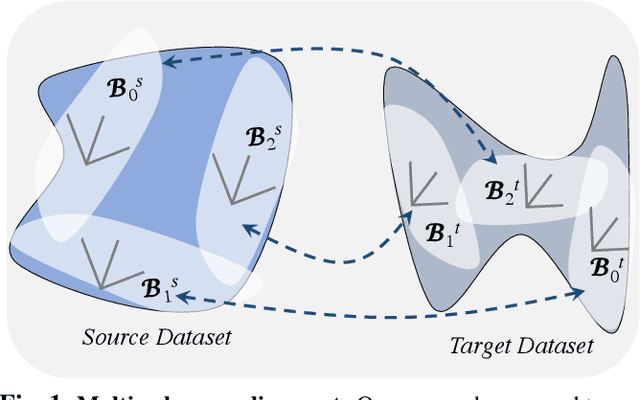
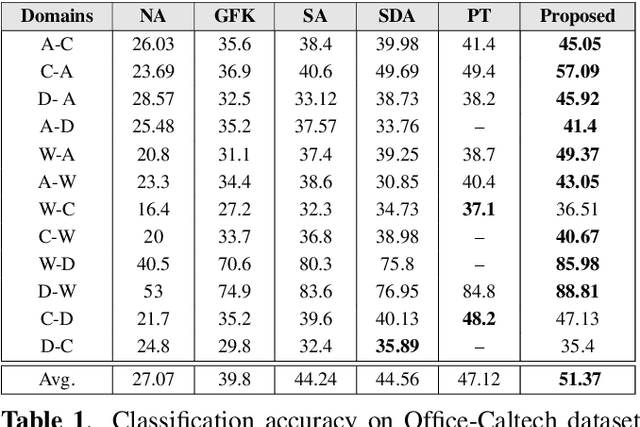
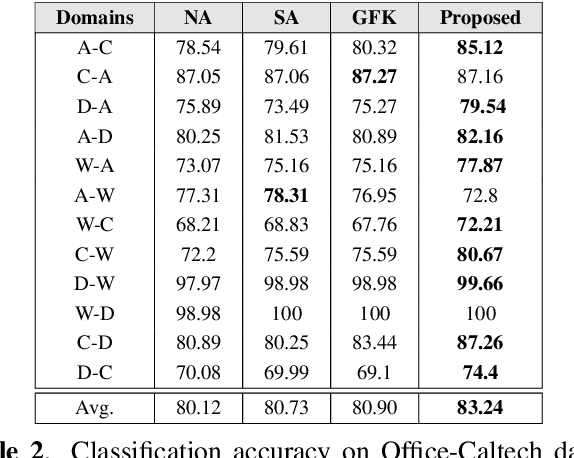

We present a novel unsupervised domain adaptation (DA) method for cross-domain visual recognition. Though subspace methods have found success in DA, their performance is often limited due to the assumption of approximating an entire dataset using a single low-dimensional subspace. Instead, we develop a method to effectively represent the source and target datasets via a collection of low-dimensional subspaces, and subsequently align them by exploiting the natural geometry of the space of subspaces, on the Grassmann manifold. We demonstrate the effectiveness of this approach, using empirical studies on two widely used benchmarks, with state of the art domain adaptation performance
Understanding Deep Neural Networks through Input Uncertainties
Nov 01, 2018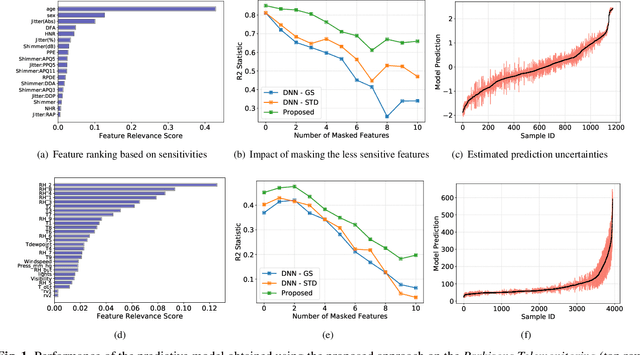
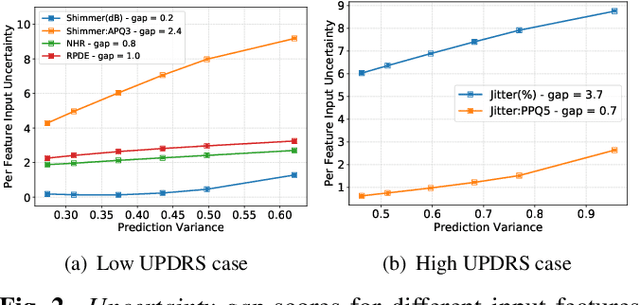
Techniques for understanding the functioning of complex machine learning models are becoming increasingly popular, not only to improve the validation process, but also to extract new insights about the data via exploratory analysis. Though a large class of such tools currently exists, most assume that predictions are point estimates and use a sensitivity analysis of these estimates to interpret the model. Using lightweight probabilistic networks we show how including prediction uncertainties in the sensitivity analysis leads to: (i) more robust and generalizable models; and (ii) a new approach for model interpretation through uncertainty decomposition. In particular, we introduce a new regularization that takes both the mean and variance of a prediction into account and demonstrate that the resulting networks provide improved generalization to unseen data. Furthermore, we propose a new technique to explain prediction uncertainties through uncertainties in the input domain, thus providing new ways to validate and interpret deep learning models.
Designing an Effective Metric Learning Pipeline for Speaker Diarization
Nov 01, 2018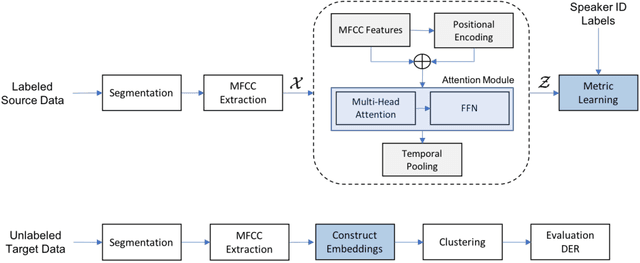
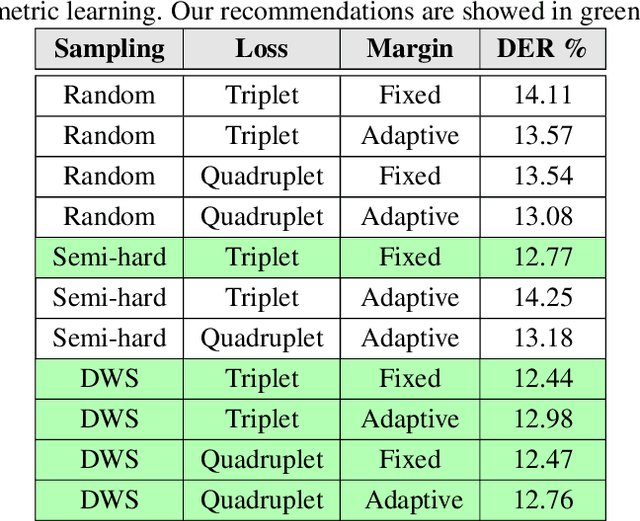
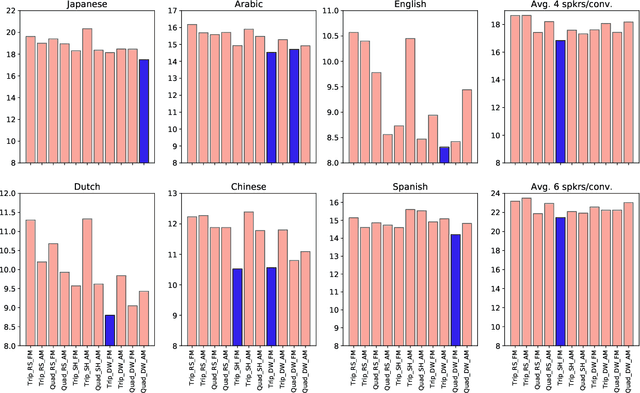
State-of-the-art speaker diarization systems utilize knowledge from external data, in the form of a pre-trained distance metric, to effectively determine relative speaker identities to unseen data. However, much of recent focus has been on choosing the appropriate feature extractor, ranging from pre-trained $i-$vectors to representations learned via different sequence modeling architectures (e.g. 1D-CNNs, LSTMs, attention models), while adopting off-the-shelf metric learning solutions. In this paper, we argue that, regardless of the feature extractor, it is crucial to carefully design a metric learning pipeline, namely the loss function, the sampling strategy and the discrimnative margin parameter, for building robust diarization systems. Furthermore, we propose to adopt a fine-grained validation process to obtain a comprehensive evaluation of the generalization power of metric learning pipelines. To this end, we measure diarization performance across different language speakers, and variations in the number of speakers in a recording. Using empirical studies, we provide interesting insights into the effectiveness of different design choices and make recommendations.
Improving Robustness of Attention Models on Graphs
Nov 01, 2018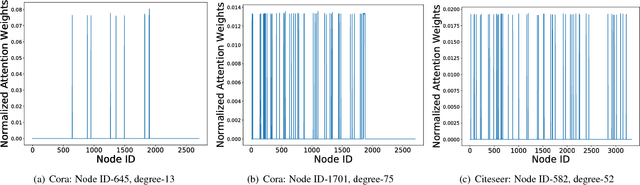
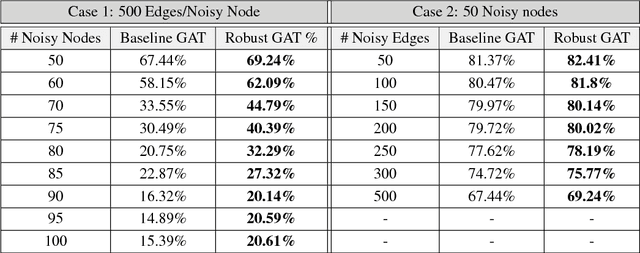
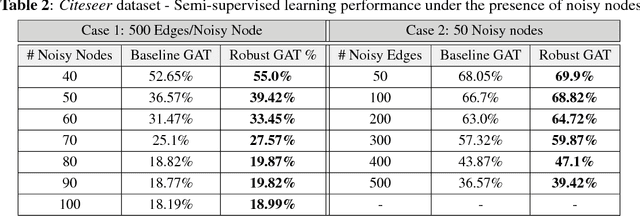
Machine learning models that can exploit the inherent structure in data have gained prominence. In particular, there is a surge in deep learning solutions for graph-structured data, due to its wide-spread applicability in several fields. Graph attention networks (GAT), a recent addition to the broad class of feature learning models in graphs, utilizes the attention mechanism to efficiently learn continuous vector representations for semi-supervised learning problems. In this paper, we perform a detailed analysis of GAT models, and present interesting insights into their behavior. In particular, we show that the models are vulnerable to adversaries (rogue nodes) and hence propose novel regularization strategies to improve the robustness of GAT models. Using benchmark datasets, we demonstrate performance improvements on semi-supervised learning, using the proposed robust variant of GAT.
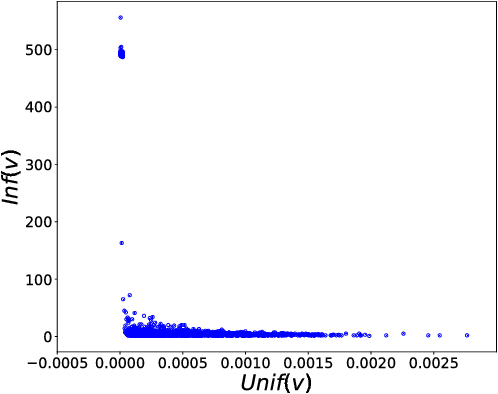
Unsupervised Dimension Selection using a Blue Noise Spectrum
Oct 31, 2018
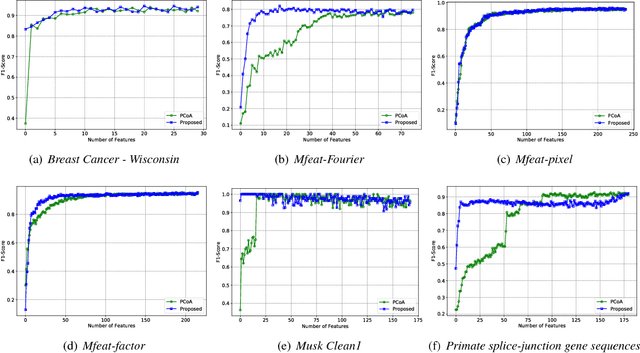
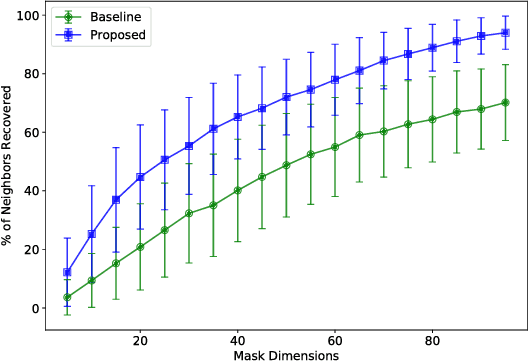
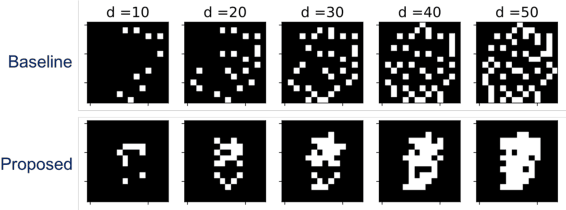
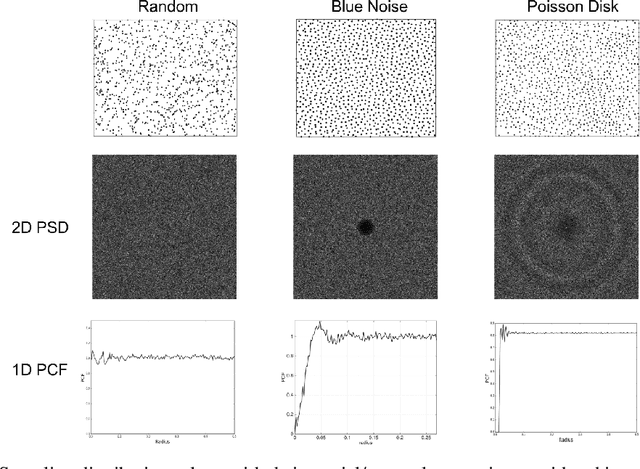
Unsupervised dimension selection is an important problem that seeks to reduce dimensionality of data, while preserving the most useful characteristics. While dimensionality reduction is commonly utilized to construct low-dimensional embeddings, they produce feature spaces that are hard to interpret. Further, in applications such as sensor design, one needs to perform reduction directly in the input domain, instead of constructing transformed spaces. Consequently, dimension selection (DS) aims to solve the combinatorial problem of identifying the top-$k$ dimensions, which is required for effective experiment design, reducing data while keeping it interpretable, and designing better sensing mechanisms. In this paper, we develop a novel approach for DS based on graph signal analysis to measure feature influence. By analyzing synthetic graph signals with a blue noise spectrum, we show that we can measure the importance of each dimension. Using experiments in supervised learning and image masking, we demonstrate the superiority of the proposed approach over existing techniques in capturing crucial characteristics of high dimensional spaces, using only a small subset of the original features.
Bootstrapping Graph Convolutional Neural Networks for Autism Spectrum Disorder Classification
Oct 30, 2018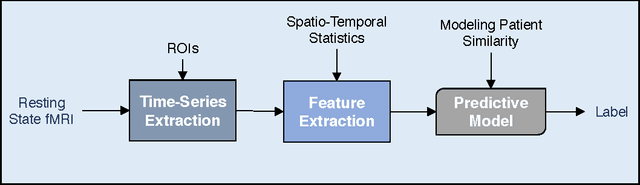
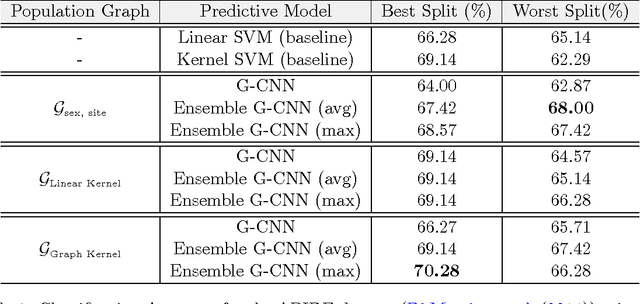
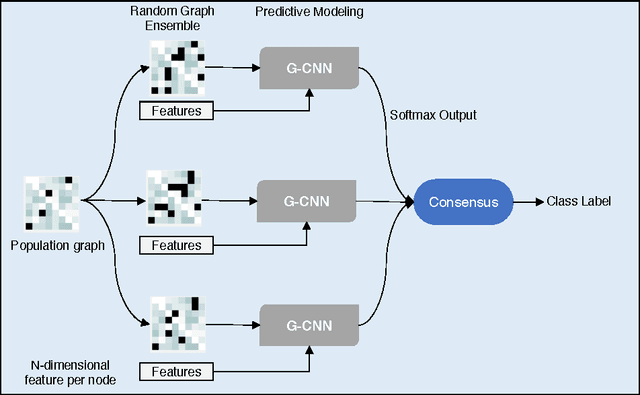
Using predictive models to identify patterns that can act as biomarkers for different neuropathoglogical conditions is becoming highly prevalent. In this paper, we consider the problem of Autism Spectrum Disorder (ASD) classification where previous work has shown that it can be beneficial to incorporate a wide variety of meta features, such as socio-cultural traits, into predictive modeling. A graph-based approach naturally suits these scenarios, where a contextual graph captures traits that characterize a population, while the specific brain activity patterns are utilized as a multivariate signal at the nodes. Graph neural networks have shown improvements in inferencing with graph-structured data. Though the underlying graph strongly dictates the overall performance, there exists no systematic way of choosing an appropriate graph in practice, thus making predictive models non-robust. To address this, we propose a bootstrapped version of graph convolutional neural networks (G-CNNs) that utilizes an ensemble of weakly trained G-CNNs, and reduce the sensitivity of models on the choice of graph construction. We demonstrate its effectiveness on the challenging Autism Brain Imaging Data Exchange (ABIDE) dataset and show that our approach improves upon recently proposed graph-based neural networks. We also show that our method remains more robust to noisy graphs.
Attention Models with Random Features for Multi-layered Graph Embeddings
Oct 02, 2018
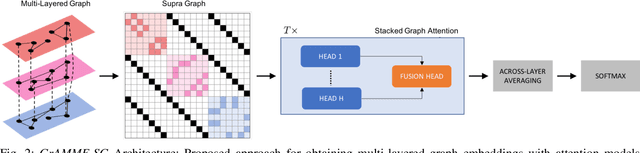
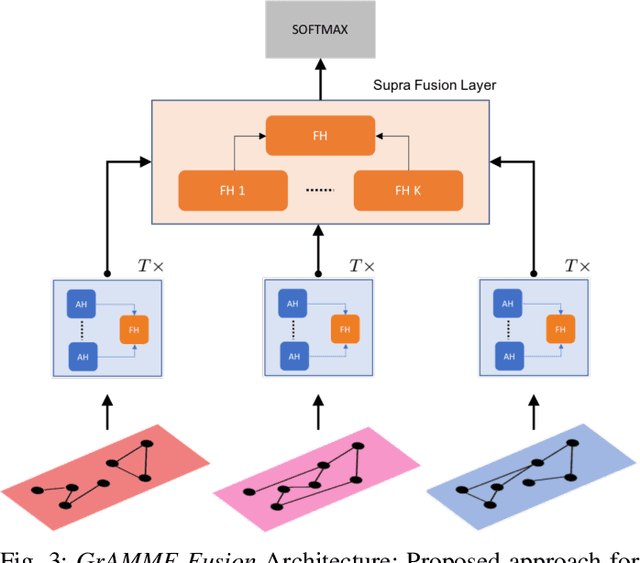
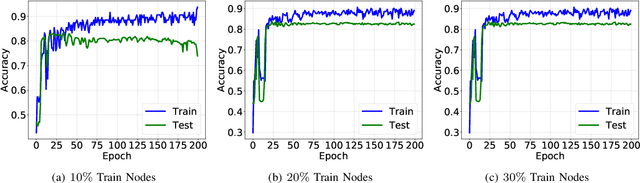
Modern data analysis pipelines are becoming increasingly complex due to the presence of multi-view information sources. While graphs are effective in modeling complex relationships, in many scenarios a single graph is rarely sufficient to succinctly represent all interactions, and hence multi-layered graphs have become popular. Though this leads to richer representations, extending solutions from the single-graph case is not straightforward. Consequently, there is a strong need for novel solutions to solve classical problems, such as node classification, in the multi-layered case. In this paper, we consider the problem of semi-supervised learning with multi-layered graphs. Though deep network embeddings, e.g. DeepWalk, are widely adopted for community discovery, we argue that feature learning with random node attributes, using graph neural networks, can be more effective. To this end, we propose to use attention models for effective feature learning, and develop two novel architectures, GrAMME-SG and GrAMME-Fusion, that exploit the inter-layer dependencies for building multi-layered graph embeddings. Using empirical studies on several benchmark datasets, we evaluate the proposed approaches and demonstrate significant performance improvements in comparison to state-of-the-art network embedding strategies. The results also show that using simple random features is an effective choice, even in cases where explicit node attributes are not available.