 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Matching Graph Neural Networks to Defend Against Poisoning Attacks
Sep 30, 2020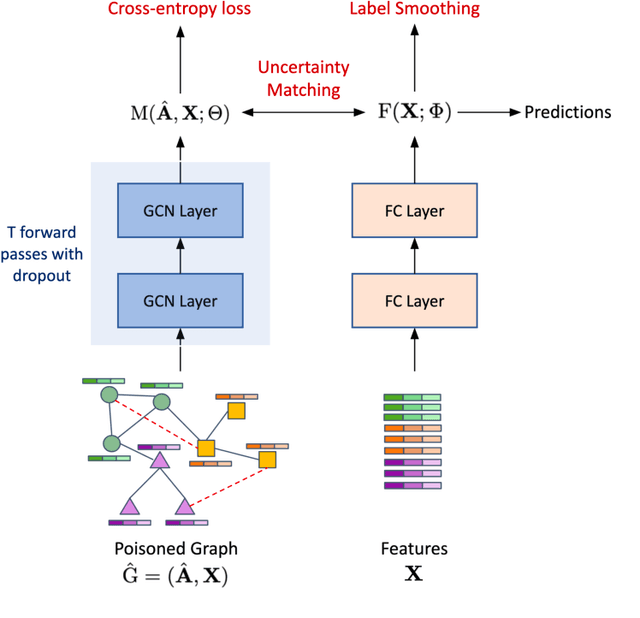

Graph Neural Networks (GNNs), a generalization of neural networks to graph-structured data, are often implemented using message passes between entities of a graph. While GNNs are effective for node classification, link prediction and graph classification, they are vulnerable to adversarial attacks, i.e., a small perturbation to the structure can lead to a non-trivial performance degradation. In this work, we propose Uncertainty Matching GNN (UM-GNN), that is aimed at improving the robustness of GNN models, particularly against poisoning attacks to the graph structure, by leveraging epistemic uncertainties from the message passing framework. More specifically, we propose to build a surrogate predictor that does not directly access the graph structure, but systematically extracts reliable knowledge from a standard GNN through a novel uncertainty-matching strategy. Interestingly, this uncoupling makes UM-GNN immune to evasion attacks by design, and achieves significantly improved robustness against poisoning attacks. Using empirical studies with standard benchmarks and a suite of global and target attacks, we demonstrate the effectiveness of UM-GNN, when compared to existing baselines including the state-of-the-art robust GCN.
Accurate and Robust Feature Importance Estimation under Distribution Shifts
Sep 30, 2020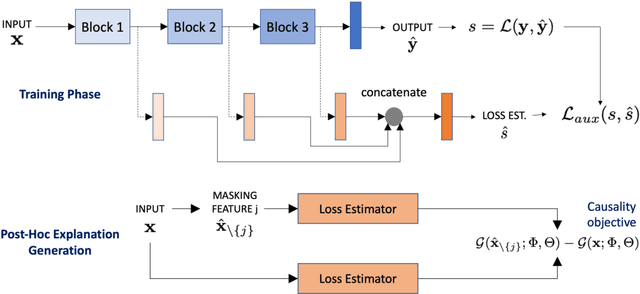
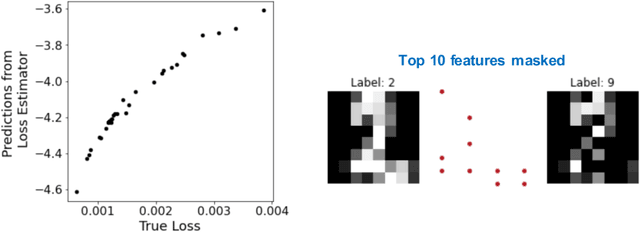
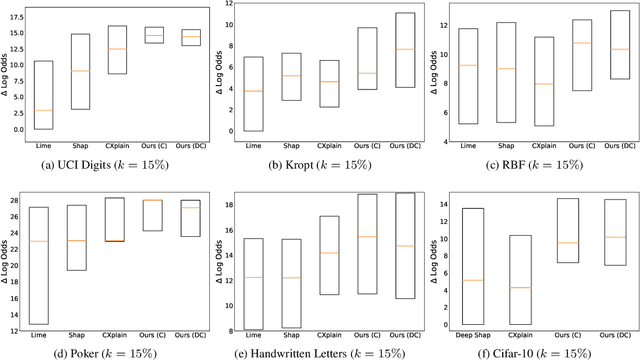
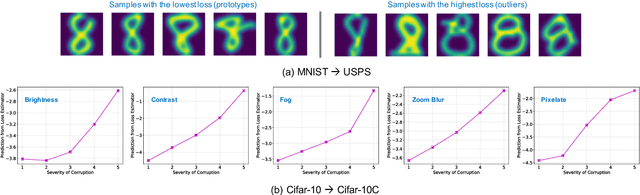
With increasing reliance on the outcomes of black-box models in critical applications, post-hoc explainability tools that do not require access to the model internals are often used to enable humans understand and trust these models. In particular, we focus on the class of methods that can reveal the influence of input features on the predicted outputs. Despite their wide-spread adoption, existing methods are known to suffer from one or more of the following challenges: computational complexities, large uncertainties and most importantly, inability to handle real-world domain shifts. In this paper, we propose PRoFILE, a novel feature importance estimation method that addresses all these challenges. Through the use of a loss estimator jointly trained with the predictive model and a causal objective, PRoFILE can accurately estimate the feature importance scores even under complex distribution shifts, without any additional re-training. To this end, we also develop learning strategies for training the loss estimator, namely contrastive and dropout calibration, and find that it can effectively detect distribution shifts. Using empirical studies on several benchmark image and non-image data, we show significant improvements over state-of-the-art approaches, both in terms of fidelity and robustness.
Ask-n-Learn: Active Learning via Reliable Gradient Representations for Image Classification
Sep 30, 2020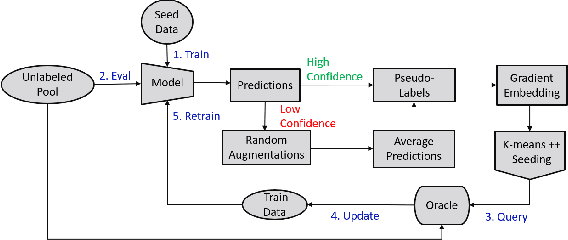
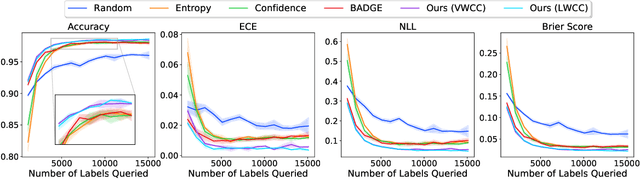
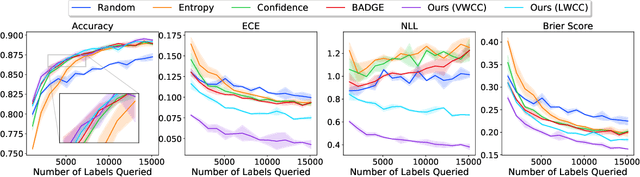
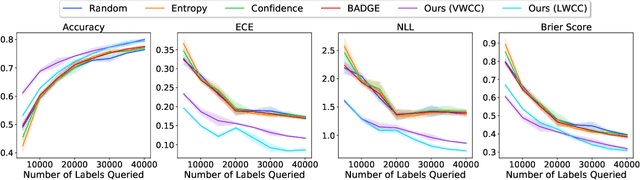
Deep predictive models rely on human supervision in the form of labeled training data. Obtaining large amounts of annotated training data can be expensive and time consuming, and this becomes a critical bottleneck while building such models in practice. In such scenarios, active learning (AL) strategies are used to achieve faster convergence in terms of labeling efforts. Existing active learning employ a variety of heuristics based on uncertainty and diversity to select query samples. Despite their wide-spread use, in practice, their performance is limited by a number of factors including non-calibrated uncertainties, insufficient trade-off between data exploration and exploitation, presence of confirmation bias etc. In order to address these challenges, we propose Ask-n-Learn, an active learning approach based on gradient embeddings obtained using the pesudo-labels estimated in each iteration of the algorithm. More importantly, we advocate the use of prediction calibration to obtain reliable gradient embeddings, and propose a data augmentation strategy to alleviate the effects of confirmation bias during pseudo-labeling. Through empirical studies on benchmark image classification tasks (CIFAR-10, SVHN, Fashion-MNIST, MNIST), we demonstrate significant improvements over state-of-the-art baselines, including the recently proposed BADGE algorithm.
Unsupervised Audio Source Separation using Generative Priors
May 28, 2020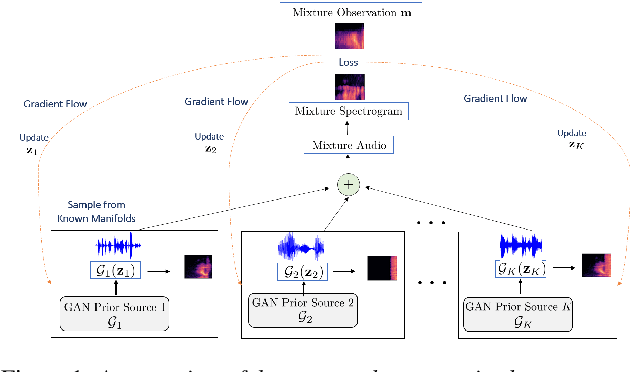
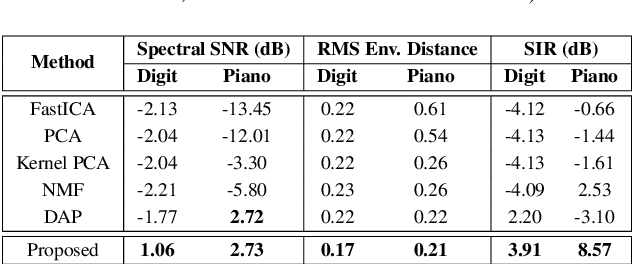
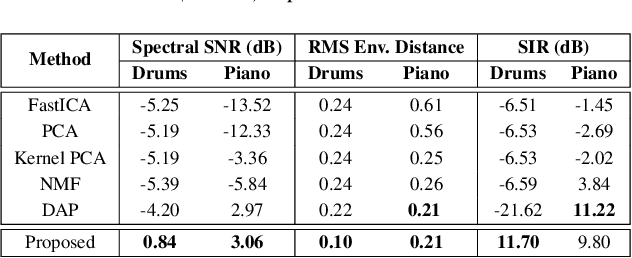
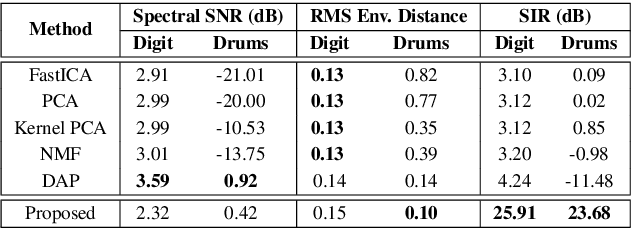
State-of-the-art under-determined audio source separation systems rely on supervised end-end training of carefully tailored neural network architectures operating either in the time or the spectral domain. However, these methods are severely challenged in terms of requiring access to expensive source level labeled data and being specific to a given set of sources and the mixing process, which demands complete re-training when those assumptions change. This strongly emphasizes the need for unsupervised methods that can leverage the recent advances in data-driven modeling, and compensate for the lack of labeled data through meaningful priors. To this end, we propose a novel approach for audio source separation based on generative priors trained on individual sources. Through the use of projected gradient descent optimization, our approach simultaneously searches in the source-specific latent spaces to effectively recover the constituent sources. Though the generative priors can be defined in the time domain directly, e.g. WaveGAN, we find that using spectral domain loss functions for our optimization leads to good-quality source estimates. Our empirical studies on standard spoken digit and instrument datasets clearly demonstrate the effectiveness of our approach over classical as well as state-of-the-art unsupervised baselines.
Designing Accurate Emulators for Scientific Processes using Calibration-Driven Deep Models
May 05, 2020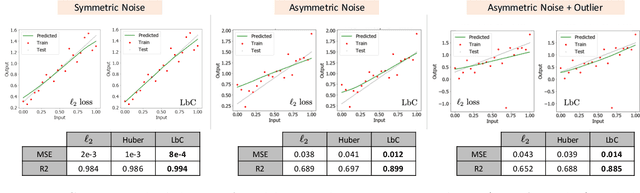
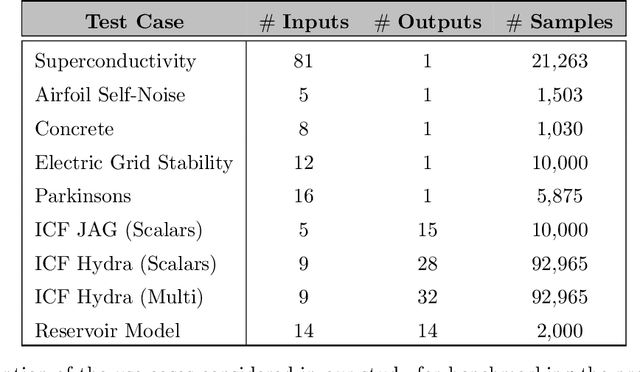
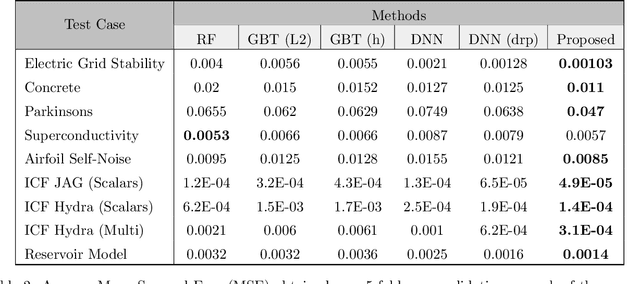
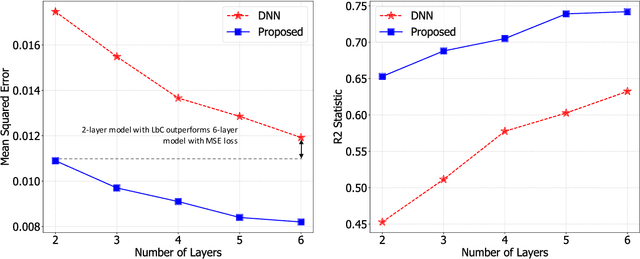
Predictive models that accurately emulate complex scientific processes can achieve exponential speed-ups over numerical simulators or experiments, and at the same time provide surrogates for improving the subsequent analysis. Consequently, there is a recent surge in utilizing modern machine learning (ML) methods, such as deep neural networks, to build data-driven emulators. While the majority of existing efforts has focused on tailoring off-the-shelf ML solutions to better suit the scientific problem at hand, we study an often overlooked, yet important, problem of choosing loss functions to measure the discrepancy between observed data and the predictions from a model. Due to lack of better priors on the expected residual structure, in practice, simple choices such as the mean squared error and the mean absolute error are made. However, the inherent symmetric noise assumption made by these loss functions makes them inappropriate in cases where the data is heterogeneous or when the noise distribution is asymmetric. We propose Learn-by-Calibrating (LbC), a novel deep learning approach based on interval calibration for designing emulators in scientific applications, that are effective even with heterogeneous data and are robust to outliers. Using a large suite of use-cases, we show that LbC provides significant improvements in generalization error over widely-adopted loss function choices, achieves high-quality emulators even in small data regimes and more importantly, recovers the inherent noise structure without any explicit priors.
Self-Training with Improved Regularization for Few-Shot Chest X-Ray Classification
May 03, 2020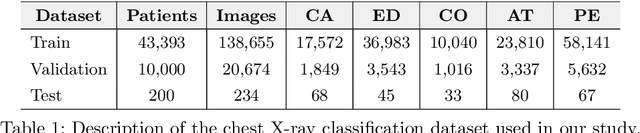
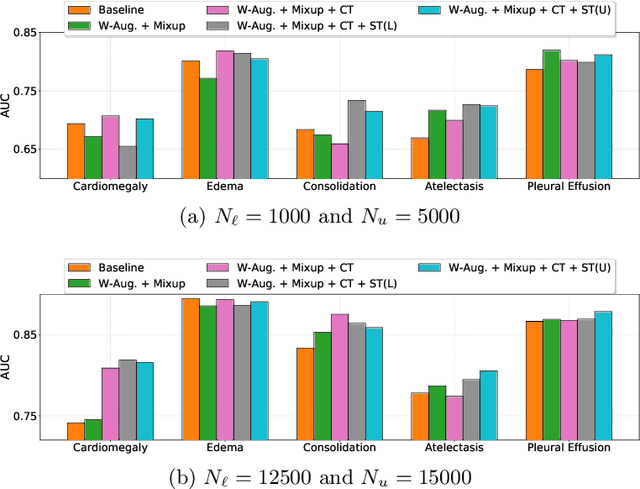
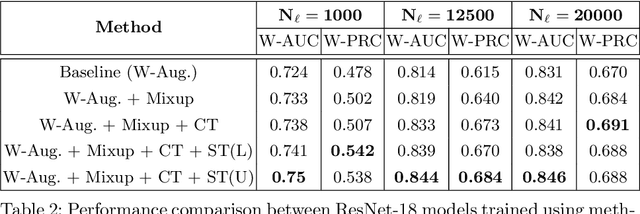
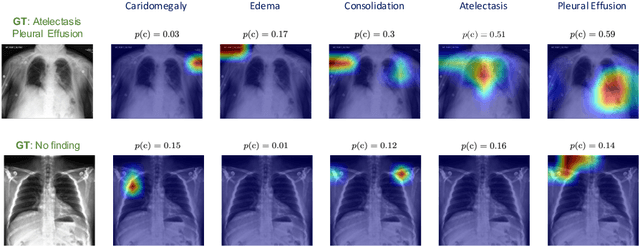
Automated diagnostic assistants in healthcare necessitate accurate AI models that can be trained with limited labeled data, can cope with severe class imbalances and can support simultaneous prediction of multiple disease conditions. To this end, we present a novel few-shot learning approach that utilizes a number of key components to enable robust modeling in such challenging scenarios. Using an important use-case in chest X-ray classification, we provide several key insights on the effective use of data augmentation, self-training via distillation and confidence tempering for few-shot learning in medical imaging. Our results show that using only ~10% of the labeled data, we can build predictive models that match the performance of classifiers trained in a large-scale data setting.
Calibrating Healthcare AI: Towards Reliable and Interpretable Deep Predictive Models
Apr 27, 2020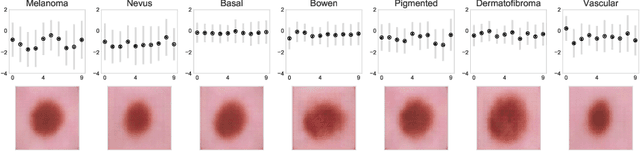
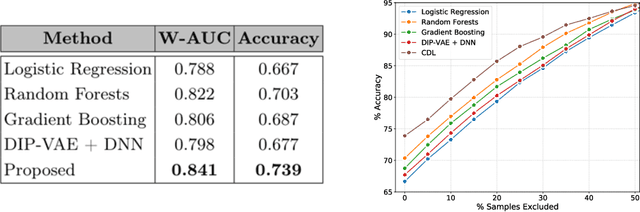
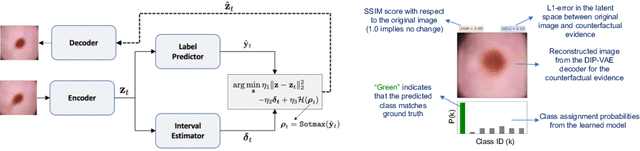
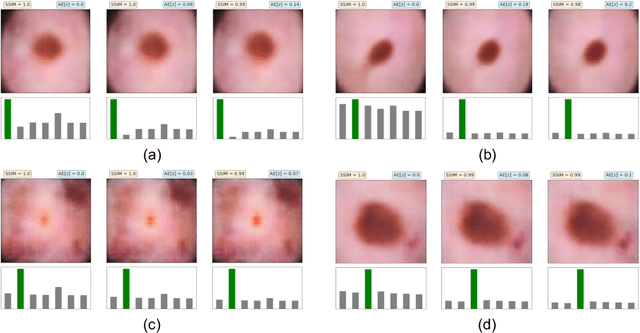
The wide-spread adoption of representation learning technologies in clinical decision making strongly emphasizes the need for characterizing model reliability and enabling rigorous introspection of model behavior. While the former need is often addressed by incorporating uncertainty quantification strategies, the latter challenge is addressed using a broad class of interpretability techniques. In this paper, we argue that these two objectives are not necessarily disparate and propose to utilize prediction calibration to meet both objectives. More specifically, our approach is comprised of a calibration-driven learning method, which is also used to design an interpretability technique based on counterfactual reasoning. Furthermore, we introduce \textit{reliability plots}, a holistic evaluation mechanism for model reliability. Using a lesion classification problem with dermoscopy images, we demonstrate the effectiveness of our approach and infer interesting insights about the model behavior.
Calibrate and Prune: Improving Reliability of Lottery Tickets Through Prediction Calibration
Feb 11, 2020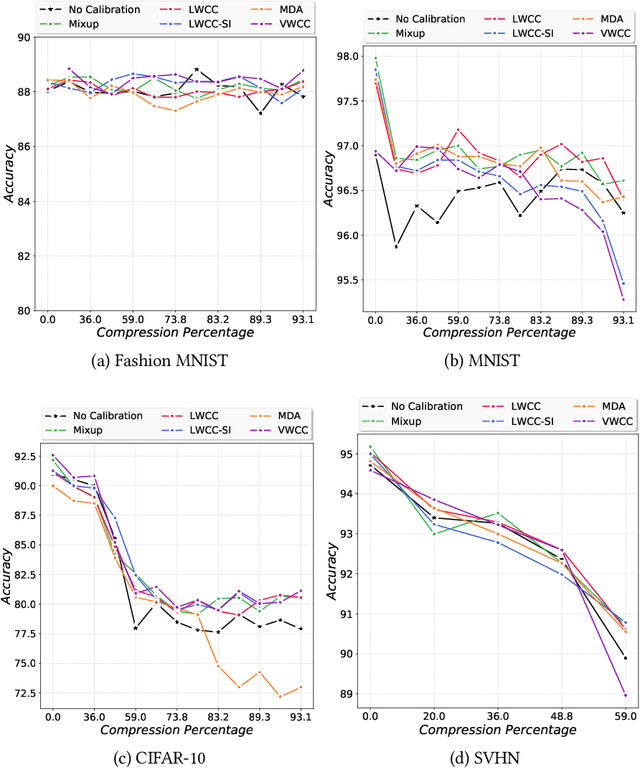
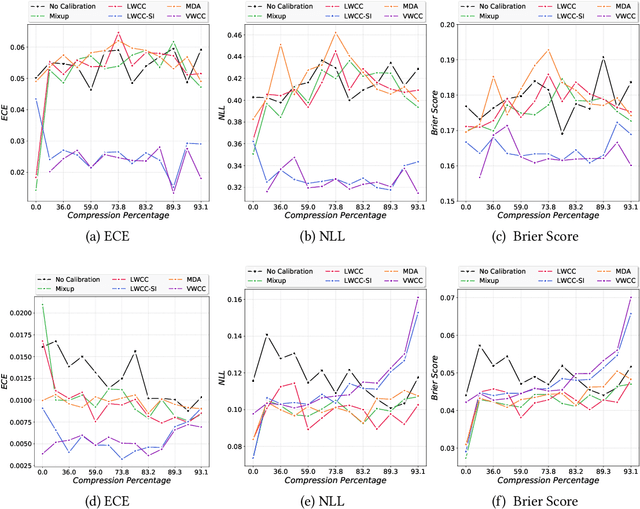
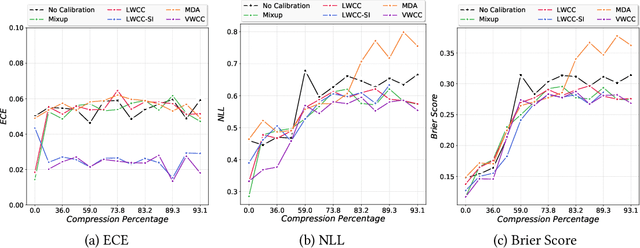
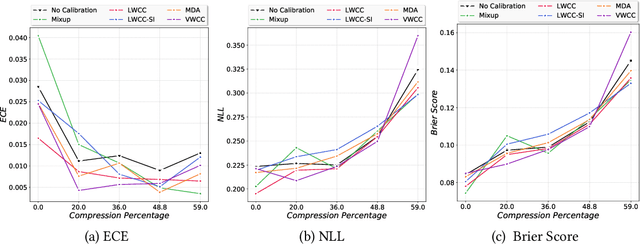
The hypothesis that sub-network initializations (lottery) exist within the initializations of over-parameterized networks, which when trained in isolation produce highly generalizable models, has led to crucial insights into network initialization and has enabled computationally efficient inferencing. In order to realize the full potential of these pruning strategies, particularly when utilized in transfer learning scenarios, it is necessary to understand the behavior of winning tickets when they might overfit to the dataset characteristics. In supervised and semi-supervised learning, prediction calibration is a commonly adopted strategy to handle such inductive biases in models. In this paper, we study the impact of incorporating calibration strategies during model training on the quality of the resulting lottery tickets, using several evaluation metrics. More specifically, we incorporate a suite of calibration strategies to different combinations of architectures and datasets, and evaluate the fidelity of sub-networks retrained based on winning tickets. Furthermore, we report the generalization performance of tickets across distributional shifts, when the inductive biases are explicitly controlled using calibration mechanisms. Finally, we provide key insights and recommendations for obtaining reliable lottery tickets, which we demonstrate to achieve improved generalization.
MimicGAN: Robust Projection onto Image Manifolds with Corruption Mimicking
Feb 07, 2020
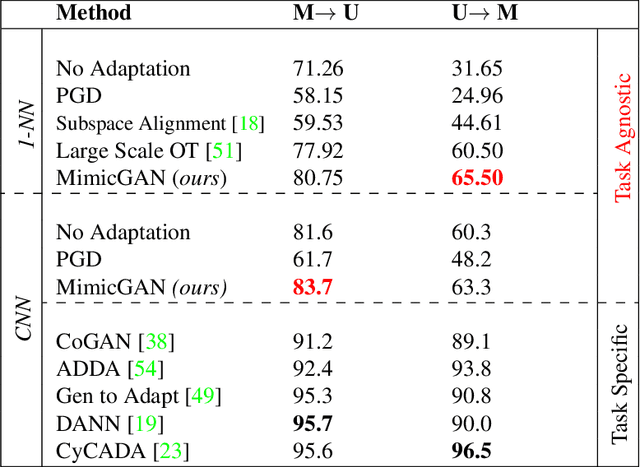
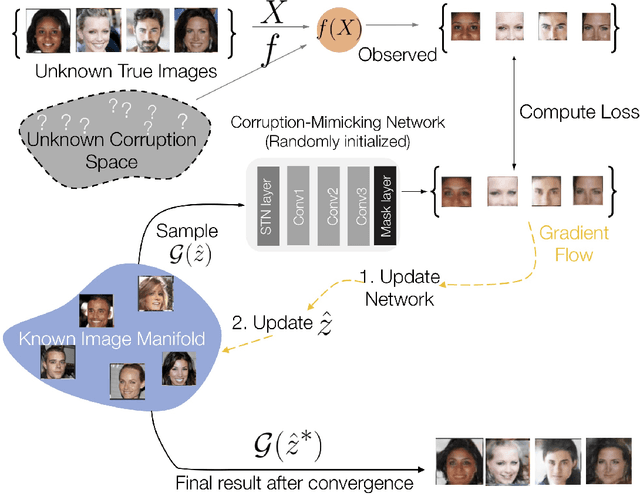
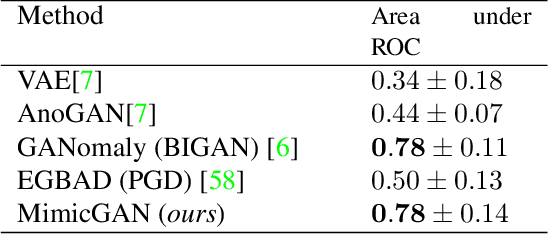
In the past few years, Generative Adversarial Networks (GANs) have dramatically advanced our ability to represent and parameterize high-dimensional, non-linear image manifolds. As a result, they have been widely adopted across a variety of applications, ranging from challenging inverse problems like image completion, to problems such as anomaly detection and adversarial defense. A recurring theme in many of these applications is the notion of projecting an image observation onto the manifold that is inferred by the generator. In this context, Projected Gradient Descent (PGD) has been the most popular approach, which essentially optimizes for a latent vector that minimizes the discrepancy between a generated image and the given observation. However, PGD is a brittle optimization technique that fails to identify the right projection (or latent vector) when the observation is corrupted, or perturbed even by a small amount. Such corruptions are common in the real world, for example images in the wild come with unknown crops, rotations, missing pixels, or other kinds of non-linear distributional shifts which break current encoding methods, rendering downstream applications unusable. To address this, we propose corruption mimicking -- a new robust projection technique, that utilizes a surrogate network to approximate the unknown corruption directly at test time, without the need for additional supervision or data augmentation. The proposed method is significantly more robust than PGD and other competing methods under a wide variety of corruptions, thereby enabling a more effective use of GANs in real-world applications. More importantly, we show that our approach produces state-of-the-art performance in several GAN-based applications -- anomaly detection, domain adaptation, and adversarial defense, that benefit from an accurate projection.
Improved Surrogates in Inertial Confinement Fusion with Manifold and Cycle Consistencies
Dec 17, 2019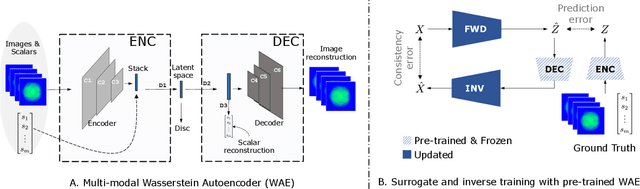

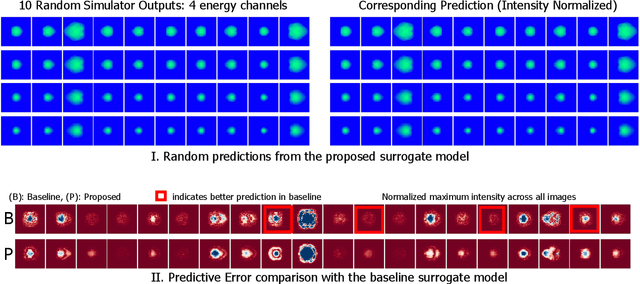
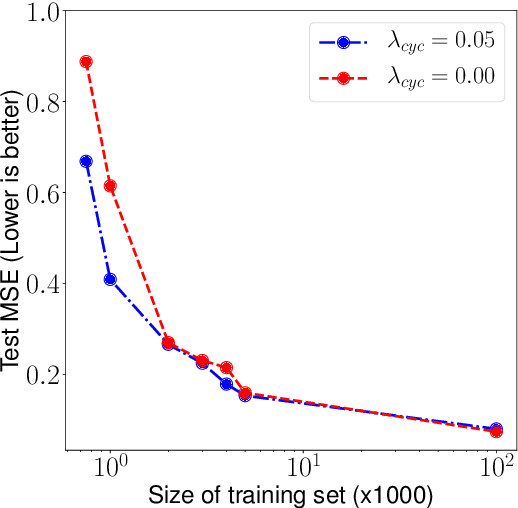
Neural networks have become very popular in surrogate modeling because of their ability to characterize arbitrary, high dimensional functions in a data driven fashion. This paper advocates for the training of surrogates that are consistent with the physical manifold -- i.e., predictions are always physically meaningful, and are cyclically consistent -- i.e., when the predictions of the surrogate, when passed through an independently trained inverse model give back the original input parameters. We find that these two consistencies lead to surrogates that are superior in terms of predictive performance, more resilient to sampling artifacts, and tend to be more data efficient. Using Inertial Confinement Fusion (ICF) as a test bed problem, we model a 1D semi-analytic numerical simulator and demonstrate the effectiveness of our approach. Code and data are available at https://github.com/rushilanirudh/macc/