 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest-of-Both-Worlds Multi-Dueling Bandits: Unified Algorithms for Stochastic and Adversarial Preferences under Condorcet and Borda Objectives
Mar 19, 2026Multi-dueling bandits, where a learner selects $m \geq 2$ arms per round and observes only the winner, arise naturally in many applications including ranking and recommendation systems, yet a fundamental question has remained open: can a single algorithm perform optimally in both stochastic and adversarial environments, without knowing which regime it faces? We answer this affirmatively, providing the first best-of-both-worlds algorithms for multi-dueling bandits under both Condorcet and Borda objectives. For the Condorcet setting, we propose \texttt{MetaDueling}, a black-box reduction that converts any dueling bandit algorithm into a multi-dueling bandit algorithm by transforming multi-way winner feedback into an unbiased pairwise signal. Instantiating our reduction with \texttt{Versatile-DB} yields the first best-of-both-worlds algorithm for multi-dueling bandits: it achieves $O(\sqrt{KT})$ pseudo-regret against adversarial preferences and the instance-optimal $O\!\left(\sum_{i \neq a^\star} \frac{\log T}{Δ_i}\right)$ pseudo-regret under stochastic preferences, both simultaneously and without prior knowledge of the regime. For the Borda setting, we propose \AlgBorda, a stochastic-and-adversarial algorithm that achieves $O\left(K^2 \log KT + K \log^2 T + \sum_{i: Δ_i^{\mathrm{B}} > 0} \frac{K\log KT}{(Δ_i^{\mathrm{B}})^2}\right)$ regret in stochastic environments and $O\left(K \sqrt{T \log KT} + K^{1/3} T^{2/3} (\log K)^{1/3}\right)$ regret against adversaries, again without prior knowledge of the regime. We complement our upper bounds with matching lower bounds for the Condorcet setting. For the Borda setting, our upper bounds are near-optimal with respect to the lower bounds (within a factor of $K$) and match the best-known results in the literature.
In-memory Implementation of On-chip Trainable and Scalable ANN for AI/ML Applications
May 19, 2020



Traditional von Neumann architecture based processors become inefficient in terms of energy and throughput as they involve separate processing and memory units, also known as~\textit{memory wall}. The memory wall problem is further exacerbated when massive parallelism and frequent data movement are required between processing and memory units for real-time implementation of artificial neural network (ANN) that enables many intelligent applications. One of the most promising approach to address the memory wall problem is to carry out computations inside the memory core itself that enhances the memory bandwidth and energy efficiency for extensive computations. This paper presents an in-memory computing architecture for ANN enabling artificial intelligence (AI) and machine learning (ML) applications. The proposed architecture utilizes deep in-memory architecture based on standard six transistor (6T) static random access memory (SRAM) core for the implementation of a multi-layered perceptron. Our novel on-chip training and inference in-memory architecture reduces energy cost and enhances throughput by simultaneously accessing the multiple rows of SRAM array per precharge cycle and eliminating the frequent access of data. The proposed architecture realizes backpropagation which is the keystone during the network training using newly proposed different building blocks such as weight updation, analog multiplication, error calculation, signed analog to digital conversion, and other necessary signal control units. The proposed architecture was trained and tested on the IRIS dataset which exhibits $\approx46\times$ more energy efficient per MAC (multiply and accumulate) operation compared to earlier classifiers.
Ultra-Low Energy and High Speed LIF Neuron using Silicon Bipolar Impact Ionization MOSFET for Spiking Neural Networks
Sep 02, 2019


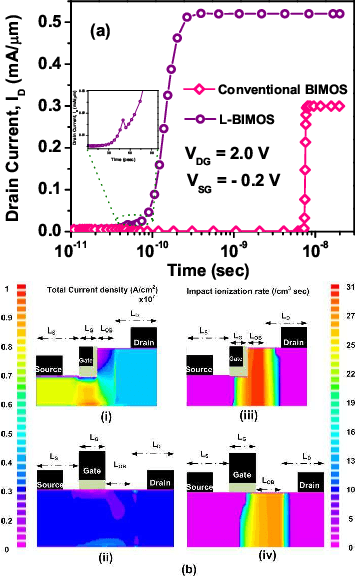
Silicon bipolar impact ionization MOSFET offers the potential for realization of leaky integrated fire (LIF) neuron due to the presence of parasitic BJT in the floating body. In this work, we have proposed an L shaped gate bipolar impact ionization MOS (L-BIMOS), with reduced breakdown voltage ($V_{B}$ = 1.68 V) and demonstrated the functioning of LIF neuron based on positive feedback mechanism of parasitic BJT. Using 2-D TCAD simulations, we manifest that the proposed L-BIMOS exhibits a low threshold voltage (0.2 V) for firing a spike, and the minimum energy required to fire a single spike for L-BIMOS is calculated to be 0.18 pJ, which makes proposed device $194\times$ more energy efficient than PD-SOI MOSFET silicon neuron (MOSFET silicon neuron) and $5\times10^{3}$ times more energy efficient than analog/digital circuit based conventional neuron. Furthermore, the proposed L-BIMOS silicon neuron exhibits spiking frequency in the GHz range, when the drain is biased at $V_{DG}$ = 2.0 V.