 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSem-NaVAE: Semantically-Guided Outdoor Mapless Navigation via Generative Trajectory Priors
Feb 01, 2026This work presents a mapless global navigation approach for outdoor applications. It combines the exploratory capacity of conditional variational autoencoders (CVAEs) to generate trajectories and the semantic segmentation capabilities of a lightweight visual language model (VLM) to select the trajectory to execute. Open-vocabulary segmentation is used to score and select the generated trajectories based on natural language, and a state-of-the-art local planner executes velocity commands. One of the key features of the proposed approach is its ability to generate a large variability of trajectories and to select them and navigate in real-time. The approach was validated through real-world outdoor navigation experiments, achieving superior performance compared to state-of-the-art methods. A video showing an experimental run of the system can be found in https://www.youtube.com/watch?v=i3R5ey5O2yk.
Data-driven control of hydraulic impact hammers under strict operational and control constraints
Jan 12, 2026This paper presents a data-driven methodology for the control of static hydraulic impact hammers, also known as rock breakers, which are commonly used in the mining industry. The task addressed in this work is that of controlling the rock-breaker so its end-effector reaches arbitrary target poses, which is required in normal operation to place the hammer on top of rocks that need to be fractured. The proposed approach considers several constraints, such as unobserved state variables due to limited sensing and the strict requirement of using a discrete control interface at the joint level. First, the proposed methodology addresses the problem of system identification to obtain an approximate dynamic model of the hydraulic arm. This is done via supervised learning, using only teleoperation data. The learned dynamic model is then exploited to obtain a controller capable of reaching target end-effector poses. For policy synthesis, both reinforcement learning (RL) and model predictive control (MPC) algorithms are utilized and contrasted. As a case study, we consider the automation of a Bobcat E10 mini-excavator arm with a hydraulic impact hammer attached as end-effector. Using this machine, both the system identification and policy synthesis stages are studied in simulation and in the real world. The best RL-based policy consistently reaches target end-effector poses with position errors below 12 cm and pitch angle errors below 0.08 rad in the real world. Considering that the impact hammer has a 4 cm diameter chisel, this level of precision is sufficient for breaking rocks. Notably, this is accomplished by relying only on approximately 68 min of teleoperation data to train and 8 min to evaluate the dynamic model, and without performing any adjustments for a successful policy Sim2Real transfer. A demonstration of policy execution in the real world can be found in https://youtu.be/e-7tDhZ4ZgA.
Sistema de navegación de cobertura para vehículos no holonómicos en ambientes de exterior
Dec 28, 2025In mobile robotics, coverage navigation refers to the deliberate movement of a robot with the purpose of covering a certain area or volume. Performing this task properly is fundamental for the execution of several activities, for instance, cleaning a facility with a robotic vacuum cleaner. In the mining industry, it is required to perform coverage in several unit processes related with material movement using industrial machinery, for example, in cleaning tasks, in dumps, and in the construction of tailings dam walls. The automation of these processes is fundamental to enhance the security associated with their execution. In this work, a coverage navigation system for a non-holonomic robot is presented. This work is intended to be a proof of concept for the potential automation of various unit processes that require coverage navigation like the ones mentioned before. The developed system includes the calculation of routes that allow a mobile platform to cover a specific area, and incorporates recovery behaviors in case that an unforeseen event occurs, such as the arising of dynamic or previously unmapped obstacles in the terrain to be covered, e.g., other machines or pedestrians passing through the area, being able to perform evasive maneuvers and post-recovery to ensure a complete coverage of the terrain. The system was tested in different simulated and real outdoor environments, obtaining results near 90% of coverage in the majority of experiments. The next step of development is to scale up the utilized robot to a mining machine/vehicle whose operation will be validated in a real environment. The result of one of the tests performed in the real world can be seen in the video available in https://youtu.be/gK7_3bK1P5g.
Human-Robot Navigation using Event-based Cameras and Reinforcement Learning
Jun 12, 2025



This work introduces a robot navigation controller that combines event cameras and other sensors with reinforcement learning to enable real-time human-centered navigation and obstacle avoidance. Unlike conventional image-based controllers, which operate at fixed rates and suffer from motion blur and latency, this approach leverages the asynchronous nature of event cameras to process visual information over flexible time intervals, enabling adaptive inference and control. The framework integrates event-based perception, additional range sensing, and policy optimization via Deep Deterministic Policy Gradient, with an initial imitation learning phase to improve sample efficiency. Promising results are achieved in simulated environments, demonstrating robust navigation, pedestrian following, and obstacle avoidance. A demo video is available at the project website.
* https://ibugueno.github.io/hr-navigation-using-event-cameras-and-rl/
Diffusion Self-Weighted Guidance for Offline Reinforcement Learning
May 23, 2025



Offline reinforcement learning (RL) recovers the optimal policy $\pi$ given historical observations of an agent. In practice, $\pi$ is modeled as a weighted version of the agent's behavior policy $\mu$, using a weight function $w$ working as a critic of the agent's behavior. Though recent approaches to offline RL based on diffusion models have exhibited promising results, the computation of the required scores is challenging due to their dependence on the unknown $w$. In this work, we alleviate this issue by constructing a diffusion over both the actions and the weights. With the proposed setting, the required scores are directly obtained from the diffusion model without learning extra networks. Our main conceptual contribution is a novel guidance method, where guidance (which is a function of $w$) comes from the same diffusion model, therefore, our proposal is termed Self-Weighted Guidance (SWG). We show that SWG generates samples from the desired distribution on toy examples and performs on par with state-of-the-art methods on D4RL's challenging environments, while maintaining a streamlined training pipeline. We further validate SWG through ablation studies on weight formulations and scalability.
Autonomous loading of ore piles with Load-Haul-Dump machines using Deep Reinforcement Learning
Sep 11, 2024



This work presents a deep reinforcement learning-based approach to train controllers for the autonomous loading of ore piles with a Load-Haul-Dump (LHD) machine. These controllers must perform a complete loading maneuver, filling the LHD's bucket with material while avoiding wheel drift, dumping material, or getting stuck in the pile. The training process is conducted entirely in simulation, using a simple environment that leverages the Fundamental Equation of Earth-Moving Mechanics so as to achieve a low computational cost. Two different types of policies are trained: one with a hybrid action space and another with a continuous action space. The RL-based policies are evaluated both in simulation and in the real world using a scaled LHD and a scaled muck pile, and their performance is compared to that of a heuristics-based controller and human teleoperation. Additional real-world experiments are performed to assess the robustness of the RL-based policies to measurement errors in the characterization of the piles. Overall, the RL-based controllers show good performance in the real world, achieving fill factors between 71-94%, and less wheel drift than the other baselines during the loading maneuvers. A video showing the training environment and the learned behavior in simulation, as well as some of the performed experiments in the real world, can be found in https://youtu.be/jOpA1rkwhDY.
YotoR-You Only Transform One Representation
May 30, 2024



This paper introduces YotoR (You Only Transform One Representation), a novel deep learning model for object detection that combines Swin Transformers and YoloR architectures. Transformers, a revolutionary technology in natural language processing, have also significantly impacted computer vision, offering the potential to enhance accuracy and computational efficiency. YotoR combines the robust Swin Transformer backbone with the YoloR neck and head. In our experiments, YotoR models TP5 and BP4 consistently outperform YoloR P6 and Swin Transformers in various evaluations, delivering improved object detection performance and faster inference speeds than Swin Transformer models. These results highlight the potential for further model combinations and improvements in real-time object detection with Transformers. The paper concludes by emphasizing the broader implications of YotoR, including its potential to enhance transformer-based models for image-related tasks.
Combining RL and IL using a dynamic, performance-based modulation over learning signals and its application to local planning
May 16, 2024



This paper proposes a method to combine reinforcement learning (RL) and imitation learning (IL) using a dynamic, performance-based modulation over learning signals. The proposed method combines RL and behavioral cloning (IL), or corrective feedback in the action space (interactive IL/IIL), by dynamically weighting the losses to be optimized, taking into account the backpropagated gradients used to update the policy and the agent's estimated performance. In this manner, RL and IL/IIL losses are combined by equalizing their impact on the policy's updates, while modulating said impact such that IL signals are prioritized at the beginning of the learning process, and as the agent's performance improves, the RL signals become progressively more relevant, allowing for a smooth transition from pure IL/IIL to pure RL. The proposed method is used to learn local planning policies for mobile robots, synthesizing IL/IIL signals online by means of a scripted policy. An extensive evaluation of the application of the proposed method to this task is performed in simulations, and it is empirically shown that it outperforms pure RL in terms of sample efficiency (achieving the same level of performance in the training environment utilizing approximately 4 times less experiences), while consistently producing local planning policies with better performance metrics (achieving an average success rate of 0.959 in an evaluation environment, outperforming pure RL by 12.5% and pure IL by 13.9%). Furthermore, the obtained local planning policies are successfully deployed in the real world without performing any major fine tuning. The proposed method can extend existing RL algorithms, and is applicable to other problems for which generating IL/IIL signals online is feasible. A video summarizing some of the real world experiments that were conducted can be found in https://youtu.be/mZlaXn9WGzw.
Learning to Play Soccer From Scratch: Sample-Efficient Emergent Coordination through Curriculum-Learning and Competition
Mar 09, 2021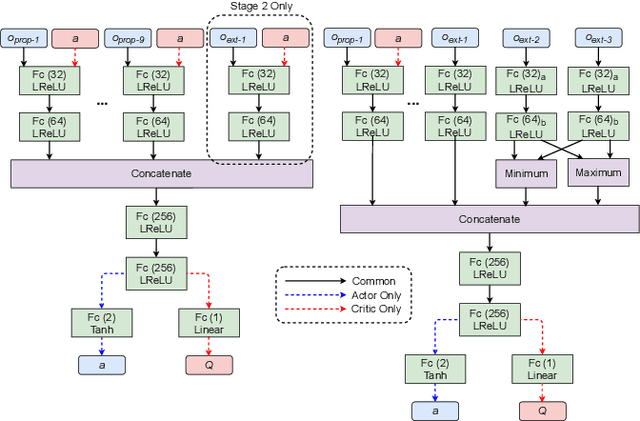
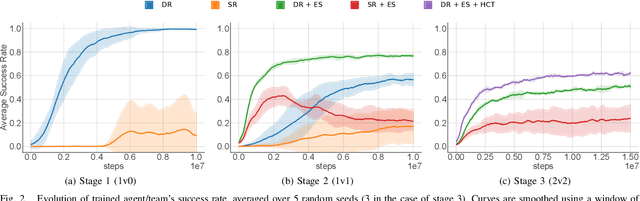
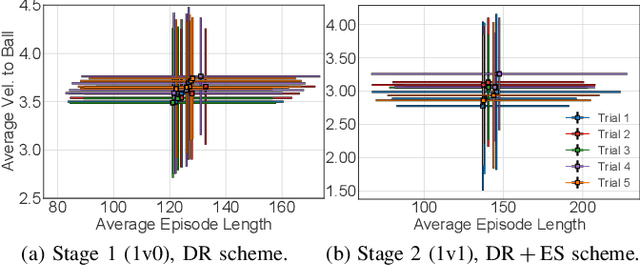
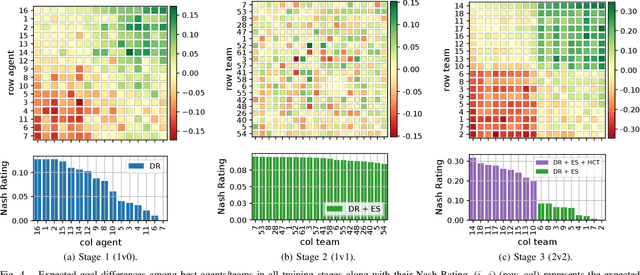
This work proposes a scheme that allows learning complex multi-agent behaviors in a sample efficient manner, applied to 2v2 soccer. The problem is formulated as a Markov game, and solved using deep reinforcement learning. We propose a basic multi-agent extension of TD3 for learning the policy of each player, in a decentralized manner. To ease learning, the task of 2v2 soccer is divided in three stages: 1v0, 1v1 and 2v2. The process of learning in multi-agent stages (1v1 and 2v2) uses agents trained on a previous stage as fixed opponents. In addition, we propose using experience sharing, a method that shares experience from a fixed opponent, trained in a previous stage, for training the agent currently learning, and a form of frame-skipping, to raise performance significantly. Our results show that high quality soccer play can be obtained with our approach in just under 40M interactions. A summarized video of the resulting game play can be found in https://youtu.be/f25l1j1U9RM.
Continuous Control for High-Dimensional State Spaces: An Interactive Learning Approach
Aug 14, 2019

Deep Reinforcement Learning (DRL) has become a powerful methodology to solve complex decision-making problems. However, DRL has several limitations when used in real-world problems (e.g., robotics applications). For instance, long training times are required and cannot be accelerated in contrast to simulated environments, and reward functions may be hard to specify/model and/or to compute. Moreover, the transfer of policies learned in a simulator to the real-world has limitations (reality gap). On the other hand, machine learning methods that rely on the transfer of human knowledge to an agent have shown to be time efficient for obtaining well performing policies and do not require a reward function. In this context, we analyze the use of human corrective feedback during task execution to learn policies with high-dimensional state spaces, by using the D-COACH framework, and we propose new variants of this framework. D-COACH is a Deep Learning based extension of COACH (COrrective Advice Communicated by Humans), where humans are able to shape policies through corrective advice. The enhanced version of D-COACH, which is proposed in this paper, largely reduces the time and effort of a human for training a policy. Experimental results validate the efficiency of the D-COACH framework in three different problems (simulated and with real robots), and show that its enhanced version reduces the human training effort considerably, and makes it feasible to learn policies within periods of time in which a DRL agent do not reach any improvement.