 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefinition and properties to assess multi-agent environments as social intelligence tests
Aug 27, 2014
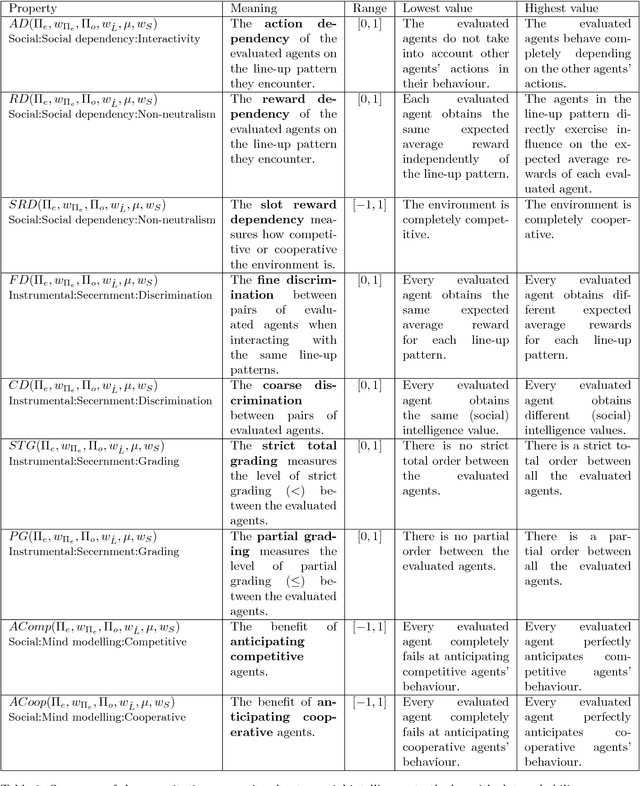


Social intelligence in natural and artificial systems is usually measured by the evaluation of associated traits or tasks that are deemed to represent some facets of social behaviour. The amalgamation of these traits is then used to configure the intuitive notion of social intelligence. Instead, in this paper we start from a parametrised definition of social intelligence as the expected performance in a set of environments with several agents, and we assess and derive tests from it. This definition makes several dependencies explicit: (1) the definition depends on the choice (and weight) of environments and agents, (2) the definition may include both competitive and cooperative behaviours depending on how agents and rewards are arranged into teams, (3) the definition mostly depends on the abilities of other agents, and (4) the actual difference between social intelligence and general intelligence (or other abilities) depends on these choices. As a result, we address the problem of converting this definition into a more precise one where some fundamental properties ensuring social behaviour (such as action and reward dependency and anticipation on competitive/cooperative behaviours) are met as well as some other more instrumental properties (such as secernment, boundedness, symmetry, validity, reliability, efficiency), which are convenient to convert the definition into a practical test. From the definition and the formalised properties, we take a look at several representative multi-agent environments, tests and games to see whether they meet these properties.
On the influence of intelligence in (social) intelligence testing environments
Feb 03, 2012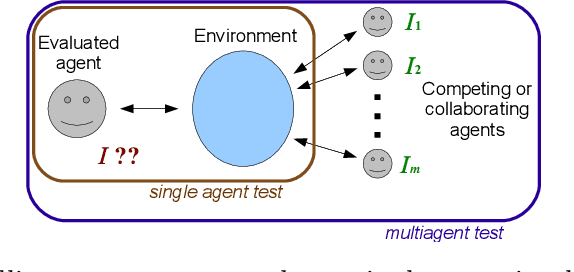
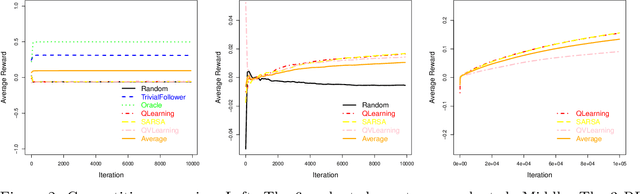
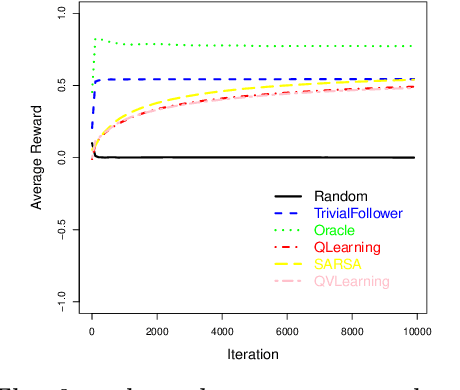
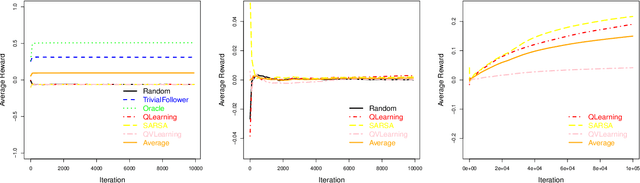
This paper analyses the influence of including agents of different degrees of intelligence in a multiagent system. The goal is to better understand how we can develop intelligence tests that can evaluate social intelligence. We analyse several reinforcement algorithms in several contexts of cooperation and competition. Our experimental setting is inspired by the recently developed Darwin-Wallace distribution.
Analysis of first prototype universal intelligence tests: evaluating and comparing AI algorithms and humans
Sep 23, 2011Today, available methods that assess AI systems are focused on using empirical techniques to measure the performance of algorithms in some specific tasks (e.g., playing chess, solving mazes or land a helicopter). However, these methods are not appropriate if we want to evaluate the general intelligence of AI and, even less, if we compare it with human intelligence. The ANYNT project has designed a new method of evaluation that tries to assess AI systems using well known computational notions and problems which are as general as possible. This new method serves to assess general intelligence (which allows us to learn how to solve any new kind of problem we face) and not only to evaluate performance on a set of specific tasks. This method not only focuses on measuring the intelligence of algorithms, but also to assess any intelligent system (human beings, animals, AI, aliens?,...), and letting us to place their results on the same scale and, therefore, to be able to compare them. This new approach will allow us (in the future) to evaluate and compare any kind of intelligent system known or even to build/find, be it artificial or biological. This master thesis aims at ensuring that this new method provides consistent results when evaluating AI algorithms, this is done through the design and implementation of prototypes of universal intelligence tests and their application to different intelligent systems (AI algorithms and humans beings). From the study we analyze whether the results obtained by two different intelligent systems are properly located on the same scale and we propose changes and refinements to these prototypes in order to, in the future, being able to achieve a truly universal intelligence test.
An architecture for the evaluation of intelligent systems
Feb 03, 2011One of the main research areas in Artificial Intelligence is the coding of agents (programs) which are able to learn by themselves in any situation. This means that agents must be useful for purposes other than those they were created for, as, for example, playing chess. In this way we try to get closer to the pristine goal of Artificial Intelligence. One of the problems to decide whether an agent is really intelligent or not is the measurement of its intelligence, since there is currently no way to measure it in a reliable way. The purpose of this project is to create an interpreter that allows for the execution of several environments, including those which are generated randomly, so that an agent (a person or a program) can interact with them. Once the interaction between the agent and the environment is over, the interpreter will measure the intelligence of the agent according to the actions, states and rewards the agent has undergone inside the environment during the test. As a result we will be able to measure agents' intelligence in any possible environment, and to make comparisons between several agents, in order to determine which of them is the most intelligent. In order to perform the tests, the interpreter must be able to randomly generate environments that are really useful to measure agents' intelligence, since not any randomly generated environment will serve that purpose.