 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Computation and Explainable AI: A Roadmap to Transparent Intelligent Systems
Jun 12, 2024



AI methods are finding an increasing number of applications, but their often black-box nature has raised concerns about accountability and trust. The field of explainable artificial intelligence (XAI) has emerged in response to the need for human understanding of AI models. Evolutionary computation (EC), as a family of powerful optimization and learning tools, has significant potential to contribute to XAI. In this paper, we provide an introduction to XAI and review various techniques in current use for explaining machine learning (ML) models. We then focus on how EC can be used in XAI, and review some XAI approaches which incorporate EC techniques. Additionally, we discuss the application of XAI principles within EC itself, examining how these principles can shed some light on the behavior and outcomes of EC algorithms in general, on the (automatic) configuration of these algorithms, and on the underlying problem landscapes that these algorithms optimize. Finally, we discuss some open challenges in XAI and opportunities for future research in this field using EC. Our aim is to demonstrate that EC is well-suited for addressing current problems in explainability and to encourage further exploration of these methods to contribute to the development of more transparent and trustworthy ML models and EC algorithms.
Benchmark time series data sets for PyTorch -- the torchtime package
Aug 01, 2022The development of models for Electronic Health Record data is an area of active research featuring a small number of public benchmark data sets. Researchers typically write custom data processing code but this hinders reproducibility and can introduce errors. The Python package torchtime provides reproducible implementations of commonly used PhysioNet and UEA & UCR time series classification repository data sets for PyTorch. Features are provided for working with irregularly sampled and partially observed time series of unequal length. It aims to simplify access to PhysioNet data and enable fair comparisons of models in this exciting area of research.
Explainable Machine Learning-driven Strategy for Automated Trading Pattern Extraction
Apr 13, 2021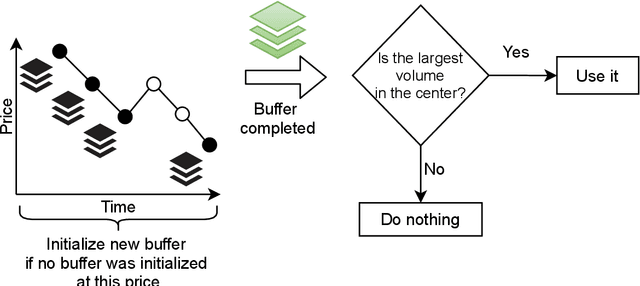

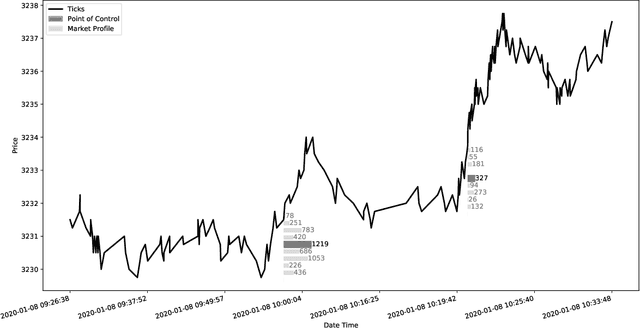
Financial markets are a source of non-stationary multidimensional time series which has been drawing attention for decades. Each financial instrument has its specific changing over time properties, making their analysis a complex task. Improvement of understanding and development of methods for financial time series analysis is essential for successful operation on financial markets. In this study we propose a volume-based data pre-processing method for making financial time series more suitable for machine learning pipelines. We use a statistical approach for assessing the performance of the method. Namely, we formally state the hypotheses, set up associated classification tasks, compute effect sizes with confidence intervals, and run statistical tests to validate the hypotheses. We additionally assess the trading performance of the proposed method on historical data and compare it to a previously published approach. Our analysis shows that the proposed volume-based method allows successful classification of the financial time series patterns, and also leads to better classification performance than a price action-based method, excelling specifically on more liquid financial instruments. Finally, we propose an approach for obtaining feature interactions directly from tree-based models on example of CatBoost estimator, as well as formally assess the relatedness of the proposed approach and SHAP feature interactions with a positive outcome.
Multi-classifier prediction of knee osteoarthritis progression from incomplete imbalanced longitudinal data
Sep 30, 2019
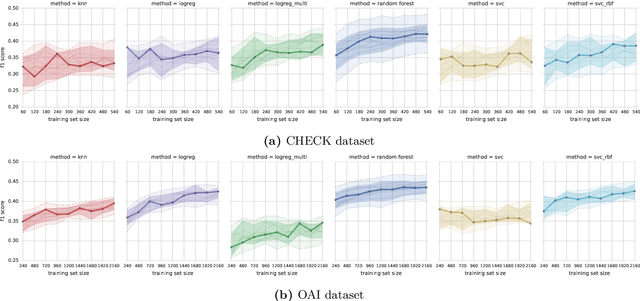

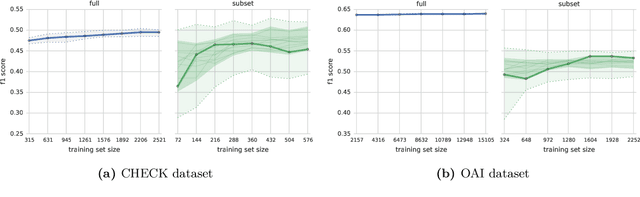
Conventional inclusion criteria used in osteoarthritis clinical trials are not very effective in selecting patients who would benefit the most from a therapy under test. Typically these criteria select majority of patients who show no or limited disease progression during a short evaluation window of the study. As a consequence, less insight on the relative effect of the treatment can be gained from the collected data, and the efforts and resources invested in running the study are not paying off. This could be avoided, if selection criteria were more predictive of the future disease progression. In this article, we formulated the patient selection problem as a multi-class classification task, with classes based on clinically relevant measures of progression (over a time scale typical for clinical trials). Using data from two long-term knee osteoarthritis studies OAI and CHECK, we tested multiple algorithms and learning process configurations (including multi-classifier approaches, cost-sensitive learning, and feature selection), to identify the best performing machine learning models. We examined the behaviour of the best models, with respect to prediction errors and the impact of used features, to confirm their clinical relevance. We found that the model-based selection outperforms the conventional inclusion criteria, reducing by 20-25% the number of patients who show no progression and making the representation of the patient categories more even. This result indicates that our machine learning approach could lead to efficiency improvements in clinical trial design.