 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectrum Data Poisoning with Adversarial Deep Learning
Jan 26, 2019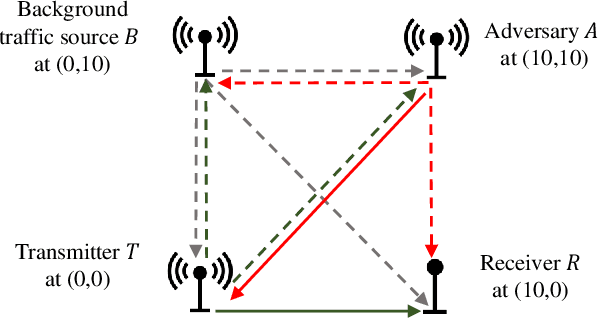
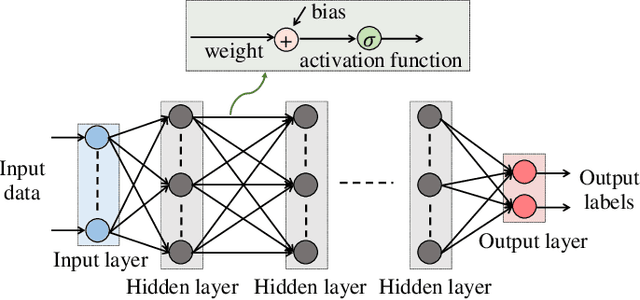

Machine learning has been widely applied in wireless communications. However, the security aspects of machine learning in wireless applications have not been well understood yet. We consider the case that a cognitive transmitter senses the spectrum and transmits on idle channels determined by a machine learning algorithm. We present an adversarial machine learning approach to launch a spectrum data poisoning attack by inferring the transmitter's behavior and attempting to falsify the spectrum sensing data over the air. For that purpose, the adversary transmits for a short period of time when the channel is idle to manipulate the input for the decision mechanism of the transmitter. The cognitive engine at the transmitter is a deep neural network model that predicts idle channels with minimum sensing error for data transmissions. The transmitter collects spectrum sensing data and uses it as the input to its machine learning algorithm. In the meantime, the adversary builds a cognitive engine using another deep neural network model to predict when the transmitter will have a successful transmission based on its spectrum sensing data. The adversary then performs the over-the-air spectrum data poisoning attack, which aims to change the channel occupancy status from idle to busy when the transmitter is sensing, so that the transmitter is fooled into making incorrect transmit decisions. This attack is more energy efficient and harder to detect compared to jamming of data transmissions. We show that this attack is very effective and reduces the throughput of the transmitter substantially.
Generative Adversarial Networks for Black-Box API Attacks with Limited Training Data
Jan 25, 2019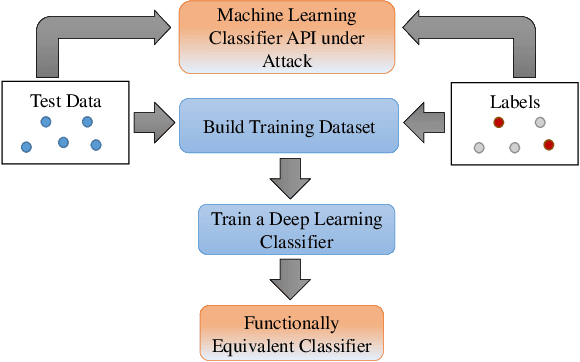
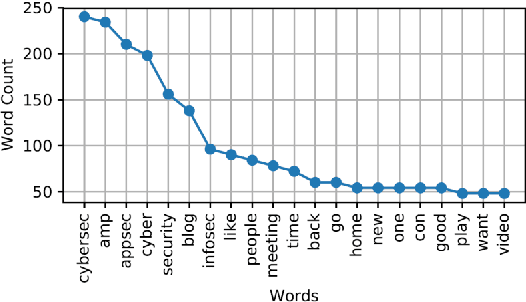
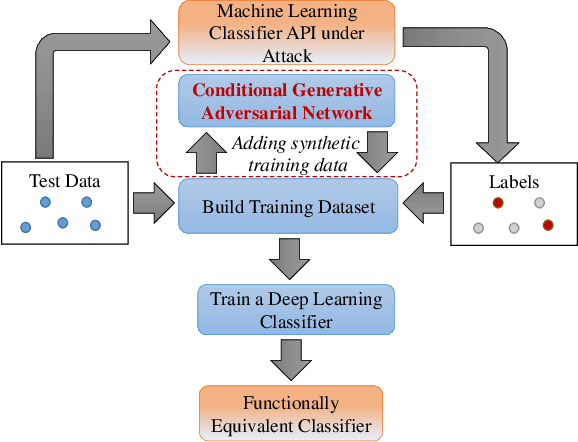
As online systems based on machine learning are offered to public or paid subscribers via application programming interfaces (APIs), they become vulnerable to frequent exploits and attacks. This paper studies adversarial machine learning in the practical case when there are rate limitations on API calls. The adversary launches an exploratory (inference) attack by querying the API of an online machine learning system (in particular, a classifier) with input data samples, collecting returned labels to build up the training data, and training an adversarial classifier that is functionally equivalent and statistically close to the target classifier. The exploratory attack with limited training data is shown to fail to reliably infer the target classifier of a real text classifier API that is available online to the public. In return, a generative adversarial network (GAN) based on deep learning is built to generate synthetic training data from a limited number of real training data samples, thereby extending the training data and improving the performance of the inferred classifier. The exploratory attack provides the basis to launch the causative attack (that aims to poison the training process) and evasion attack (that aims to fool the classifier into making wrong decisions) by selecting training and test data samples, respectively, based on the confidence scores obtained from the inferred classifier. These stealth attacks with small footprint (using a small number of API calls) make adversarial machine learning practical under the realistic case with limited training data available to the adversary.
Active Deep Learning Attacks under Strict Rate Limitations for Online API Calls
Nov 05, 2018
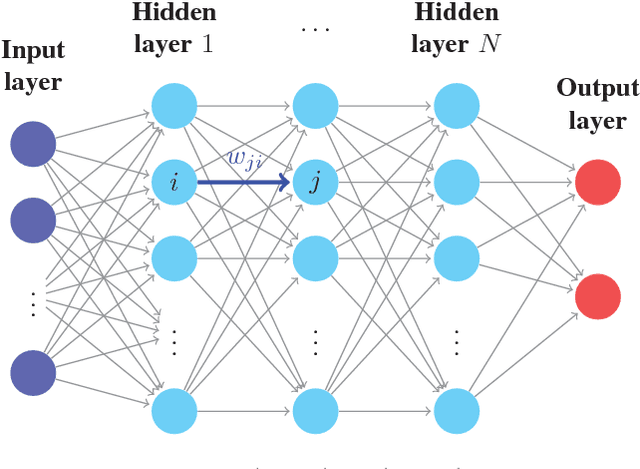


Machine learning has been applied to a broad range of applications and some of them are available online as application programming interfaces (APIs) with either free (trial) or paid subscriptions. In this paper, we study adversarial machine learning in the form of back-box attacks on online classifier APIs. We start with a deep learning based exploratory (inference) attack, which aims to build a classifier that can provide similar classification results (labels) as the target classifier. To minimize the difference between the labels returned by the inferred classifier and the target classifier, we show that the deep learning based exploratory attack requires a large number of labeled training data samples. These labels can be collected by calling the online API, but usually there is some strict rate limitation on the number of allowed API calls. To mitigate the impact of limited training data, we develop an active learning approach that first builds a classifier based on a small number of API calls and uses this classifier to select samples to further collect their labels. Then, a new classifier is built using more training data samples. This updating process can be repeated multiple times. We show that this active learning approach can build an adversarial classifier with a small statistical difference from the target classifier using only a limited number of training data samples. We further consider evasion and causative (poisoning) attacks based on the inferred classifier that is built by the exploratory attack. Evasion attack determines samples that the target classifier is likely to misclassify, whereas causative attack provides erroneous training data samples to reduce the reliability of the re-trained classifier. The success of these attacks show that adversarial machine learning emerges as a feasible threat in the realistic case with limited training data.