 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Convolutional Networks for Automatically Generating Image Masks to Train Mask R-CNN
Mar 03, 2020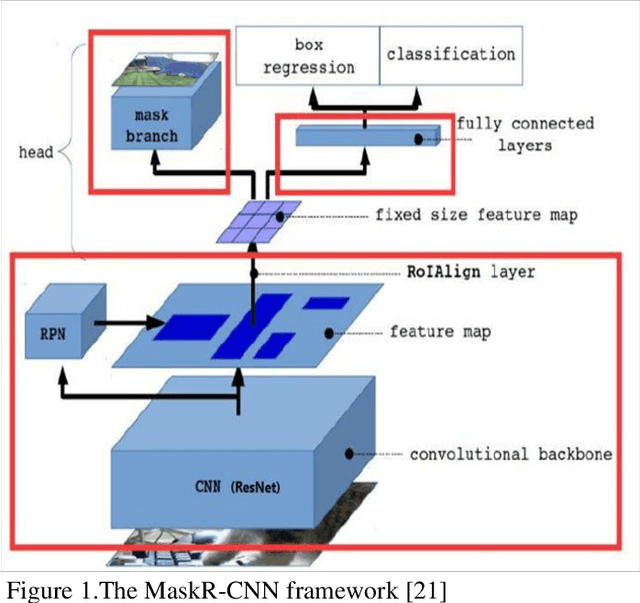
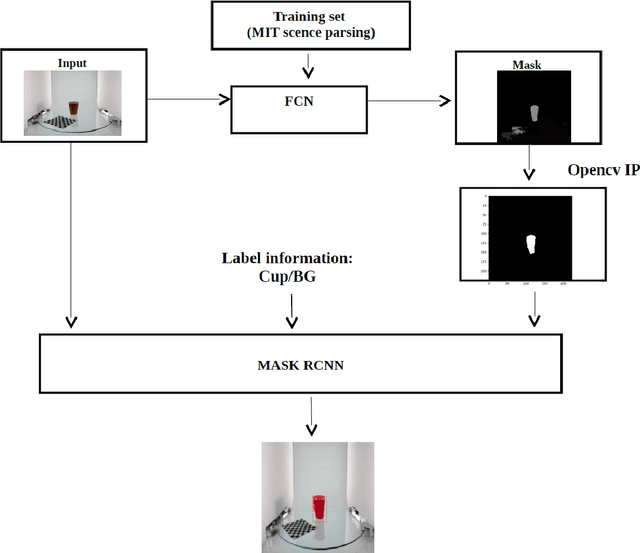


This paper proposes a novel automatically generating image masks method for the state-of-the-art Mask R-CNN deep learning method. The Mask R-CNN method achieves the best results in object detection until now, however, it is very time-consuming and laborious to get the object Masks for training, the proposed method is composed by a two-stage design, to automatically generating image masks, the first stage implements a fully convolutional networks (FCN) based segmentation network, the second stage network, a Mask R-CNN based object detection network, which is trained on the object image masks from FCN output, the original input image, and additional label information. Through experimentation, our proposed method can obtain the image masks automatically to train Mask R-CNN, and it can achieve very high classification accuracy with an over 90% mean of average precision (mAP) for segmentation
Efficient Egocentric Visual Perception Combining Eye-tracking, a Software Retina and Deep Learning
Sep 05, 2018
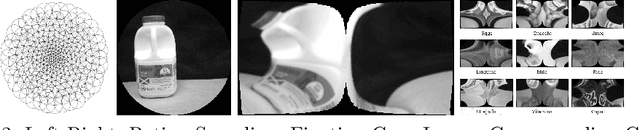

We present ongoing work to harness biological approaches to achieving highly efficient egocentric perception by combining the space-variant imaging architecture of the mammalian retina with Deep Learning methods. By pre-processing images collected by means of eye-tracking glasses to control the fixation locations of a software retina model, we demonstrate that we can reduce the input to a DCNN by a factor of 3, reduce the required number of training epochs and obtain over 98% classification rates when training and validating the system on a database of over 26,000 images of 9 object classes.