 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Immunity in In-Context Tabular Learning: An Empirical Robustness Analysis of TabPFN's Attention Mechanisms
Apr 06, 2026Tabular foundation models (TFMs) such as TabPFN (Tabular Prior-Data Fitted Network) are designed to generalize across heterogeneous tabular datasets through in-context learning (ICL). They perform prediction in a single forward pass conditioned on labeled examples without dataset-specific parameter updates. This paradigm is particularly attractive in industrial domains (e.g., finance and healthcare) where tabular prediction is pervasive. Retraining a bespoke model for each new table can be costly or infeasible in these settings, while data quality issues such as irrelevant predictors, correlated feature groups, and label noise are common. In this paper, we provide strong empirical evidence that TabPFN is highly robust under these sub-optimal conditions. We study TabPFN and its attention mechanisms for binary classification problems with controlled synthetic perturbations that vary: (i) dataset width by injecting random uncorrelated features and by introducing nonlinearly correlated features, (ii) dataset size by increasing the number of training rows, and (iii) label quality by increasing the fraction of mislabeled targets. Beyond predictive performance, we analyze internal signals including attention concentration and attention-based feature ranking metrics. Across these parametric tests, TabPFN is remarkably resilient: ROC-AUC remains high, attention stays structured and sharp, and informative features are highly ranked by attention-based metrics. Qualitative visualizations with attention heatmaps, feature-token embeddings, and SHAP plots further support a consistent pattern across layers in which TabPFN increasingly concentrates on useful features while separating their signals from noise. Together, these findings suggest that TabPFN is a robust TFM capable of maintaining both predictive performance and coherent internal behavior under various scenarios of data imperfections.
Large Language Models for Conducting Advanced Text Analytics Information Systems Research
Dec 27, 2023



The exponential growth of digital content has generated massive textual datasets, necessitating advanced analytical approaches. Large Language Models (LLMs) have emerged as tools capable of processing and extracting insights from massive unstructured textual datasets. However, how to leverage LLMs for text-based Information Systems (IS) research is currently unclear. To assist IS research in understanding how to operationalize LLMs, we propose a Text Analytics for Information Systems Research (TAISR) framework. Our proposed framework provides detailed recommendations grounded in IS and LLM literature on how to conduct meaningful text-based IS research. We conducted three case studies in business intelligence using our TAISR framework to demonstrate its application across several IS research contexts. We also outline potential challenges and limitations in adopting LLMs for IS. By offering a systematic approach and evidence of its utility, our TAISR framework contributes to future IS research streams looking to incorporate powerful LLMs for text analytics.
Binary Black-box Evasion Attacks Against Deep Learning-based Static Malware Detectors with Adversarial Byte-Level Language Model
Dec 14, 2020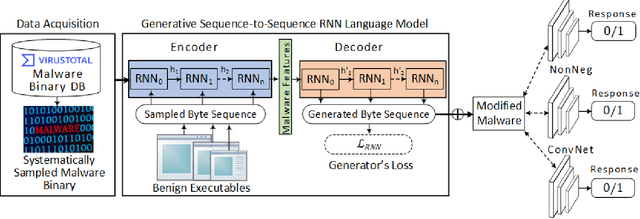
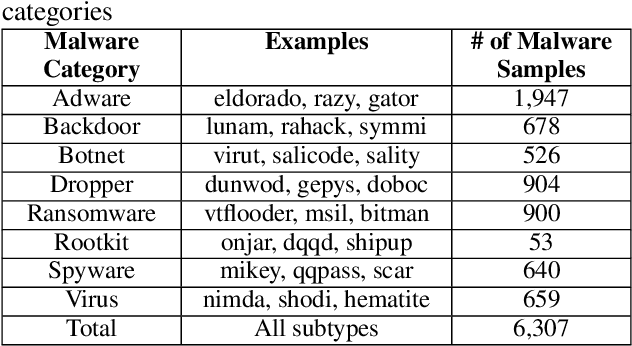
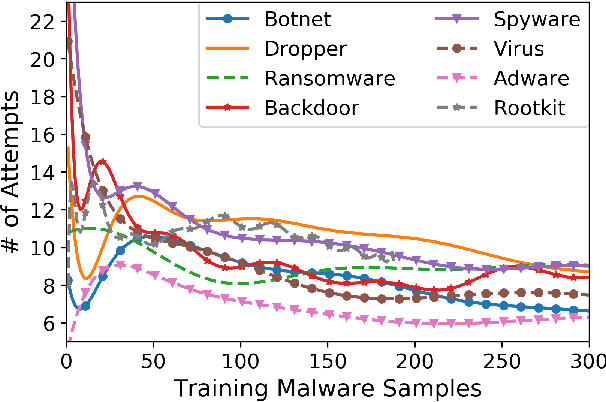
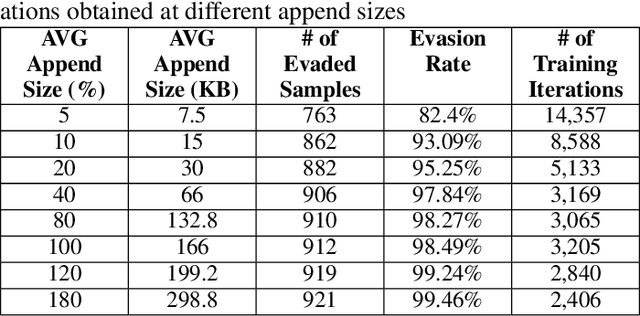
Anti-malware engines are the first line of defense against malicious software. While widely used, feature engineering-based anti-malware engines are vulnerable to unseen (zero-day) attacks. Recently, deep learning-based static anti-malware detectors have achieved success in identifying unseen attacks without requiring feature engineering and dynamic analysis. However, these detectors are susceptible to malware variants with slight perturbations, known as adversarial examples. Generating effective adversarial examples is useful to reveal the vulnerabilities of such systems. Current methods for launching such attacks require accessing either the specifications of the targeted anti-malware model, the confidence score of the anti-malware response, or dynamic malware analysis, which are either unrealistic or expensive. We propose MalRNN, a novel deep learning-based approach to automatically generate evasive malware variants without any of these restrictions. Our approach features an adversarial example generation process, which learns a language model via a generative sequence-to-sequence recurrent neural network to augment malware binaries. MalRNN effectively evades three recent deep learning-based malware detectors and outperforms current benchmark methods. Findings from applying our MalRNN on a real dataset with eight malware categories are discussed.
* Accepted in 35th AAAI Conference on Artificial Intelligence, Workshop on Robust, Secure, and Efficient Machine Learning (RSEML)