 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssemblage: Automatic Binary Dataset Construction for Machine Learning
May 07, 2024



Binary code is pervasive, and binary analysis is a key task in reverse engineering, malware classification, and vulnerability discovery. Unfortunately, while there exist large corpuses of malicious binaries, obtaining high-quality corpuses of benign binaries for modern systems has proven challenging (e.g., due to licensing issues). Consequently, machine learning based pipelines for binary analysis utilize either costly commercial corpuses (e.g., VirusTotal) or open-source binaries (e.g., coreutils) available in limited quantities. To address these issues, we present Assemblage: an extensible cloud-based distributed system that crawls, configures, and builds Windows PE binaries to obtain high-quality binary corpuses suitable for training state-of-the-art models in binary analysis. We have run Assemblage on AWS over the past year, producing 890k Windows PE and 428k Linux ELF binaries across 29 configurations. Assemblage is designed to be both reproducible and extensible, enabling users to publish "recipes" for their datasets, and facilitating the extraction of a wide array of features. We evaluated Assemblage by using its data to train modern learning-based pipelines for compiler provenance and binary function similarity. Our results illustrate the practical need for robust corpuses of high-quality Windows PE binaries in training modern learning-based binary analyses. Assemblage can be downloaded from https://assemblage-dataset.net
Holographic Global Convolutional Networks for Long-Range Prediction Tasks in Malware Detection
Mar 23, 2024



Malware detection is an interesting and valuable domain to work in because it has significant real-world impact and unique machine-learning challenges. We investigate existing long-range techniques and benchmarks and find that they're not very suitable in this problem area. In this paper, we introduce Holographic Global Convolutional Networks (HGConv) that utilize the properties of Holographic Reduced Representations (HRR) to encode and decode features from sequence elements. Unlike other global convolutional methods, our method does not require any intricate kernel computation or crafted kernel design. HGConv kernels are defined as simple parameters learned through backpropagation. The proposed method has achieved new SOTA results on Microsoft Malware Classification Challenge, Drebin, and EMBER malware benchmarks. With log-linear complexity in sequence length, the empirical results demonstrate substantially faster run-time by HGConv compared to other methods achieving far more efficient scaling even with sequence length $\geq 100,000$.
Small Effect Sizes in Malware Detection? Make Harder Train/Test Splits!
Dec 25, 2023



Industry practitioners care about small improvements in malware detection accuracy because their models are deployed to hundreds of millions of machines, meaning a 0.1\% change can cause an overwhelming number of false positives. However, academic research is often restrained to public datasets on the order of ten thousand samples and is too small to detect improvements that may be relevant to industry. Working within these constraints, we devise an approach to generate a benchmark of configurable difficulty from a pool of available samples. This is done by leveraging malware family information from tools like AVClass to construct training/test splits that have different generalization rates, as measured by a secondary model. Our experiments will demonstrate that using a less accurate secondary model with disparate features is effective at producing benchmarks for a more sophisticated target model that is under evaluation. We also ablate against alternative designs to show the need for our approach.
Reproducibility in Multiple Instance Learning: A Case For Algorithmic Unit Tests
Oct 27, 2023Multiple Instance Learning (MIL) is a sub-domain of classification problems with positive and negative labels and a "bag" of inputs, where the label is positive if and only if a positive element is contained within the bag, and otherwise is negative. Training in this context requires associating the bag-wide label to instance-level information, and implicitly contains a causal assumption and asymmetry to the task (i.e., you can't swap the labels without changing the semantics). MIL problems occur in healthcare (one malignant cell indicates cancer), cyber security (one malicious executable makes an infected computer), and many other tasks. In this work, we examine five of the most prominent deep-MIL models and find that none of them respects the standard MIL assumption. They are able to learn anti-correlated instances, i.e., defaulting to "positive" labels until seeing a negative counter-example, which should not be possible for a correct MIL model. We suspect that enhancements and other works derived from these models will share the same issue. In any context in which these models are being used, this creates the potential for learning incorrect models, which creates risk of operational failure. We identify and demonstrate this problem via a proposed "algorithmic unit test", where we create synthetic datasets that can be solved by a MIL respecting model, and which clearly reveal learning that violates MIL assumptions. The five evaluated methods each fail one or more of these tests. This provides a model-agnostic way to identify violations of modeling assumptions, which we hope will be useful for future development and evaluation of MIL models.
Exploring the Sharpened Cosine Similarity
Jul 25, 2023



Convolutional layers have long served as the primary workhorse for image classification. Recently, an alternative to convolution was proposed using the Sharpened Cosine Similarity (SCS), which in theory may serve as a better feature detector. While multiple sources report promising results, there has not been to date a full-scale empirical analysis of neural network performance using these new layers. In our work, we explore SCS's parameter behavior and potential as a drop-in replacement for convolutions in multiple CNN architectures benchmarked on CIFAR-10. We find that while SCS may not yield significant increases in accuracy, it may learn more interpretable representations. We also find that, in some circumstances, SCS may confer a slight increase in adversarial robustness.
Recasting Self-Attention with Holographic Reduced Representations
May 31, 2023



In recent years, self-attention has become the dominant paradigm for sequence modeling in a variety of domains. However, in domains with very long sequence lengths the $\mathcal{O}(T^2)$ memory and $\mathcal{O}(T^2 H)$ compute costs can make using transformers infeasible. Motivated by problems in malware detection, where sequence lengths of $T \geq 100,000$ are a roadblock to deep learning, we re-cast self-attention using the neuro-symbolic approach of Holographic Reduced Representations (HRR). In doing so we perform the same high-level strategy of the standard self-attention: a set of queries matching against a set of keys, and returning a weighted response of the values for each key. Implemented as a ``Hrrformer'' we obtain several benefits including $\mathcal{O}(T H \log H)$ time complexity, $\mathcal{O}(T H)$ space complexity, and convergence in $10\times$ fewer epochs. Nevertheless, the Hrrformer achieves near state-of-the-art accuracy on LRA benchmarks and we are able to learn with just a single layer. Combined, these benefits make our Hrrformer the first viable Transformer for such long malware classification sequences and up to $280\times$ faster to train on the Long Range Arena benchmark. Code is available at \url{https://github.com/NeuromorphicComputationResearchProgram/Hrrformer}
A Coreset Learning Reality Check
Jan 15, 2023Subsampling algorithms are a natural approach to reduce data size before fitting models on massive datasets. In recent years, several works have proposed methods for subsampling rows from a data matrix while maintaining relevant information for classification. While these works are supported by theory and limited experiments, to date there has not been a comprehensive evaluation of these methods. In our work, we directly compare multiple methods for logistic regression drawn from the coreset and optimal subsampling literature and discover inconsistencies in their effectiveness. In many cases, methods do not outperform simple uniform subsampling.
Efficient Malware Analysis Using Metric Embeddings
Dec 05, 2022In this paper, we explore the use of metric learning to embed Windows PE files in a low-dimensional vector space for downstream use in a variety of applications, including malware detection, family classification, and malware attribute tagging. Specifically, we enrich labeling on malicious and benign PE files using computationally expensive, disassembly-based malicious capabilities. Using these capabilities, we derive several different types of metric embeddings utilizing an embedding neural network trained via contrastive loss, Spearman rank correlation, and combinations thereof. We then examine performance on a variety of transfer tasks performed on the EMBER and SOREL datasets, demonstrating that for several tasks, low-dimensional, computationally efficient metric embeddings maintain performance with little decay, which offers the potential to quickly retrain for a variety of transfer tasks at significantly reduced storage overhead. We conclude with an examination of practical considerations for the use of our proposed embedding approach, such as robustness to adversarial evasion and introduction of task-specific auxiliary objectives to improve performance on mission critical tasks.
Lempel-Ziv Networks
Nov 23, 2022Sequence processing has long been a central area of machine learning research. Recurrent neural nets have been successful in processing sequences for a number of tasks; however, they are known to be both ineffective and computationally expensive when applied to very long sequences. Compression-based methods have demonstrated more robustness when processing such sequences -- in particular, an approach pairing the Lempel-Ziv Jaccard Distance (LZJD) with the k-Nearest Neighbor algorithm has shown promise on long sequence problems (up to $T=200,000,000$ steps) involving malware classification. Unfortunately, use of LZJD is limited to discrete domains. To extend the benefits of LZJD to a continuous domain, we investigate the effectiveness of a deep-learning analog of the algorithm, the Lempel-Ziv Network. While we achieve successful proof of concept, we are unable to improve meaningfully on the performance of a standard LSTM across a variety of datasets and sequence processing tasks. In addition to presenting this negative result, our work highlights the problem of sub-par baseline tuning in newer research areas.
Deploying Convolutional Networks on Untrusted Platforms Using 2D Holographic Reduced Representations
Jun 13, 2022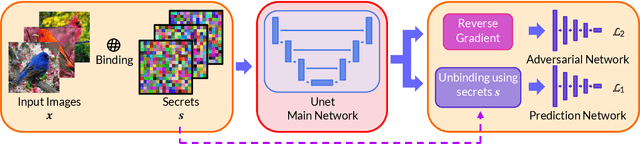
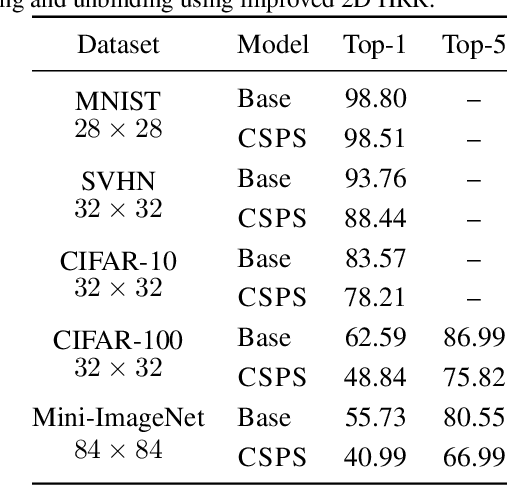
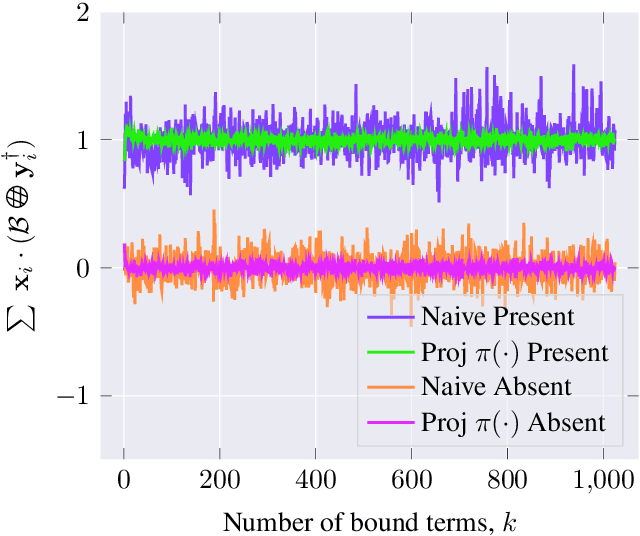

Due to the computational cost of running inference for a neural network, the need to deploy the inferential steps on a third party's compute environment or hardware is common. If the third party is not fully trusted, it is desirable to obfuscate the nature of the inputs and outputs, so that the third party can not easily determine what specific task is being performed. Provably secure protocols for leveraging an untrusted party exist but are too computational demanding to run in practice. We instead explore a different strategy of fast, heuristic security that we call Connectionist Symbolic Pseudo Secrets. By leveraging Holographic Reduced Representations (HRR), we create a neural network with a pseudo-encryption style defense that empirically shows robustness to attack, even under threat models that unrealistically favor the adversary.