 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Parsing with Minimal Features Using Bi-Directional LSTM
Jun 21, 2016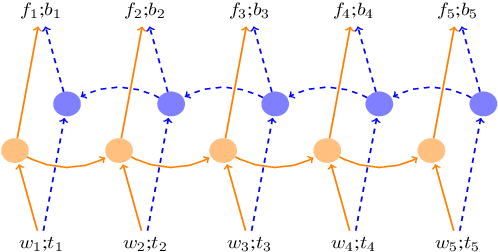

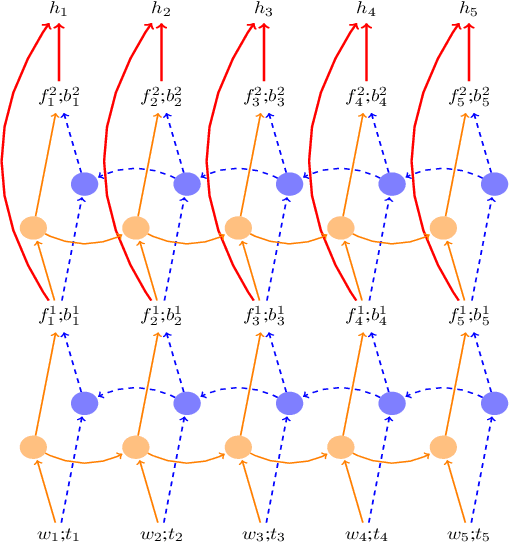
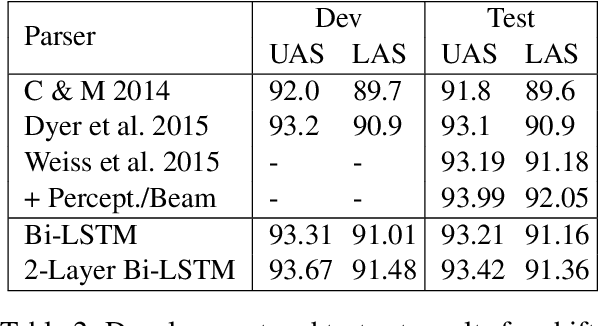
Recently, neural network approaches for parsing have largely automated the combination of individual features, but still rely on (often a larger number of) atomic features created from human linguistic intuition, and potentially omitting important global context. To further reduce feature engineering to the bare minimum, we use bi-directional LSTM sentence representations to model a parser state with only three sentence positions, which automatically identifies important aspects of the entire sentence. This model achieves state-of-the-art results among greedy dependency parsers for English. We also introduce a novel transition system for constituency parsing which does not require binarization, and together with the above architecture, achieves state-of-the-art results among greedy parsers for both English and Chinese.
Good, Better, Best: Choosing Word Embedding Context
Nov 19, 2015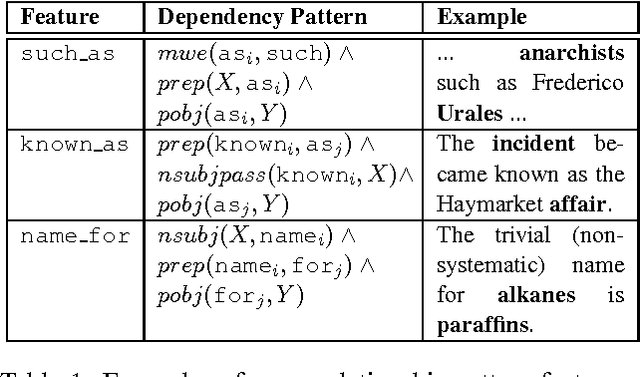
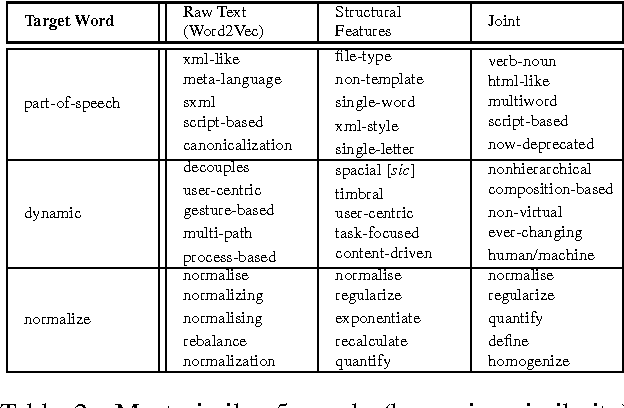
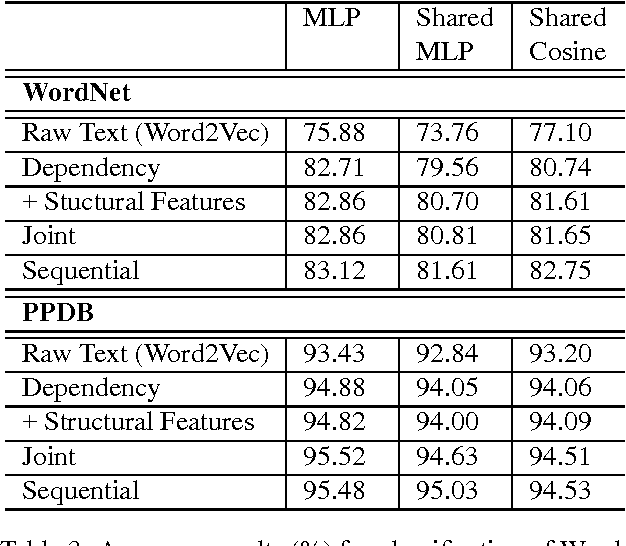
We propose two methods of learning vector representations of words and phrases that each combine sentence context with structural features extracted from dependency trees. Using several variations of neural network classifier, we show that these combined methods lead to improved performance when used as input features for supervised term-matching.