 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPreQEL: Adaptive Mixed Precision Quantization For Edge LLMs
Mar 24, 2026Today, large language models have demonstrated their strengths in various tasks ranging from reasoning, code generation, and complex problem solving. However, this advancement comes with a high computational cost and memory requirements, making it challenging to deploy these models on edge devices to ensure real-time responses and data privacy. Quantization is one common approach to reducing memory use, but most methods apply it uniformly across all layers. This does not account for the fact that different layers may respond differently to reduced precision. Importantly, memory consumption and computational throughput are not necessarily aligned, further complicating deployment decisions. This paper proposes an adaptive mixed precision quantization mechanism that balances memory, latency, and accuracy in edge deployment under user-defined priorities. This is achieved by analyzing the layer-wise contribution and by inferring how different quantization types behave across the target hardware platform in order to assign the most suitable quantization type to each layer. This integration ensures that layer importance and the overall performance trade-offs are jointly respected in this design. Our work unlocks new configuration designs that uniform quantization cannot achieve, expanding the solution space to efficiently deploy the LLMs on resource-constrained devices.
RETENTION: Resource-Efficient Tree-Based Ensemble Model Acceleration with Content-Addressable Memory
Jun 06, 2025Although deep learning has demonstrated remarkable capabilities in learning from unstructured data, modern tree-based ensemble models remain superior in extracting relevant information and learning from structured datasets. While several efforts have been made to accelerate tree-based models, the inherent characteristics of the models pose significant challenges for conventional accelerators. Recent research leveraging content-addressable memory (CAM) offers a promising solution for accelerating tree-based models, yet existing designs suffer from excessive memory consumption and low utilization. This work addresses these challenges by introducing RETENTION, an end-to-end framework that significantly reduces CAM capacity requirement for tree-based model inference. We propose an iterative pruning algorithm with a novel pruning criterion tailored for bagging-based models (e.g., Random Forest), which minimizes model complexity while ensuring controlled accuracy degradation. Additionally, we present a tree mapping scheme that incorporates two innovative data placement strategies to alleviate the memory redundancy caused by the widespread use of don't care states in CAM. Experimental results show that implementing the tree mapping scheme alone achieves $1.46\times$ to $21.30 \times$ better space efficiency, while the full RETENTION framework yields $4.35\times$ to $207.12\times$ improvement with less than 3% accuracy loss. These results demonstrate that RETENTION is highly effective in reducing CAM capacity requirement, providing a resource-efficient direction for tree-based model acceleration.
ReLeaSER: A Reinforcement Learning Strategy for Optimizing Utilization Of Ephemeral Cloud Resources
Oct 16, 2020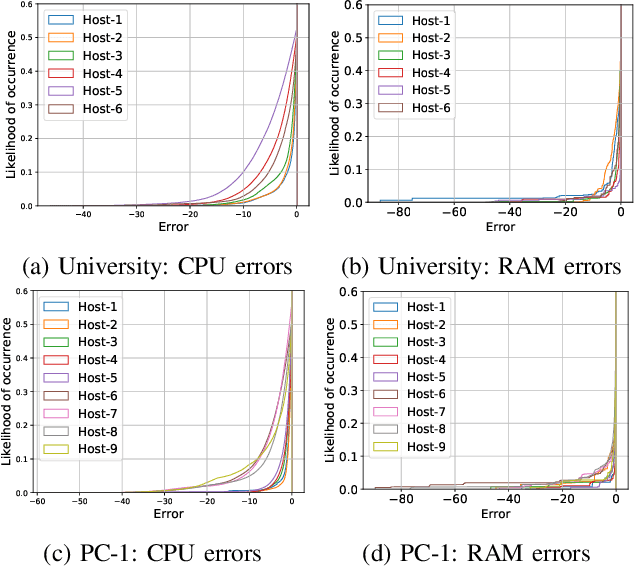
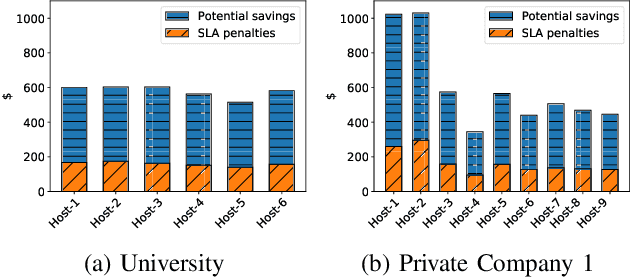
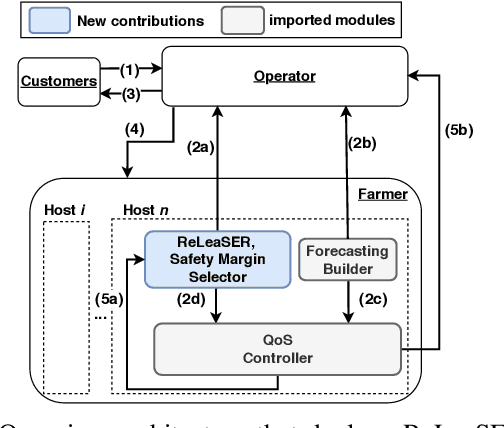
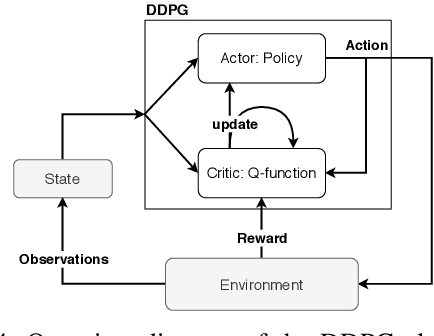
Cloud data center capacities are over-provisioned to handle demand peaks and hardware failures which leads to low resources' utilization. One way to improve resource utilization and thus reduce the total cost of ownership is to offer unused resources (referred to as ephemeral resources) at a lower price. However, reselling resources needs to meet the expectations of its customers in terms of Quality of Service. The goal is so to maximize the amount of reclaimed resources while avoiding SLA penalties. To achieve that, cloud providers have to estimate their future utilization to provide availability guarantees. The prediction should consider a safety margin for resources to react to unpredictable workloads. The challenge is to find the safety margin that provides the best trade-off between the amount of resources to reclaim and the risk of SLA violations. Most state-of-the-art solutions consider a fixed safety margin for all types of metrics (e.g., CPU, RAM). However, a unique fixed margin does not consider various workloads variations over time which may lead to SLA violations or/and poor utilization. In order to tackle these challenges, we propose ReLeaSER, a Reinforcement Learning strategy for optimizing the ephemeral resources' utilization in the cloud. ReLeaSER dynamically tunes the safety margin at the host-level for each resource metric. The strategy learns from past prediction errors (that caused SLA violations). Our solution reduces significantly the SLA violation penalties on average by 2.7x and up to 3.4x. It also improves considerably the CPs' potential savings by 27.6% on average and up to 43.6%.