 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Keyframe Layouts for Visual Known-Item Search in Homogeneous Collections
Oct 05, 2025Multimodal deep-learning models power interactive video retrieval by ranking keyframes in response to textual queries. Despite these advances, users must still browse ranked candidates manually to locate a target. Keyframe arrangement within the search grid highly affects browsing effectiveness and user efficiency, yet remains underexplored. We report a study with 49 participants evaluating seven keyframe layouts for the Visual Known-Item Search task. Beyond efficiency and accuracy, we relate browsing phenomena, such as overlooks, to layout characteristics. Our results show that a video-grouped layout is the most efficient, while a four-column, rank-preserving grid achieves the highest accuracy. Sorted grids reveal potentials and trade-offs, enabling rapid scanning of uninteresting regions but down-ranking relevant targets to less prominent positions, delaying first arrival times and increasing overlooks. These findings motivate hybrid designs that preserve positions of top-ranked items while sorting or grouping the remainder, and offer guidance for searching in grids beyond video retrieval.
Experimental Evaluation of Static Image Sub-Region-Based Search Models Using CLIP
Jun 07, 2025



Advances in multimodal text-image models have enabled effective text-based querying in extensive image collections. While these models show convincing performance for everyday life scenes, querying in highly homogeneous, specialized domains remains challenging. The primary problem is that users can often provide only vague textual descriptions as they lack expert knowledge to discriminate between homogenous entities. This work investigates whether adding location-based prompts to complement these vague text queries can enhance retrieval performance. Specifically, we collected a dataset of 741 human annotations, each containing short and long textual descriptions and bounding boxes indicating regions of interest in challenging underwater scenes. Using these annotations, we evaluate the performance of CLIP when queried on various static sub-regions of images compared to the full image. Our results show that both a simple 3-by-3 partitioning and a 5-grid overlap significantly improve retrieval effectiveness and remain robust to perturbations of the annotation box.
TransNet V2: An effective deep network architecture for fast shot transition detection
Aug 11, 2020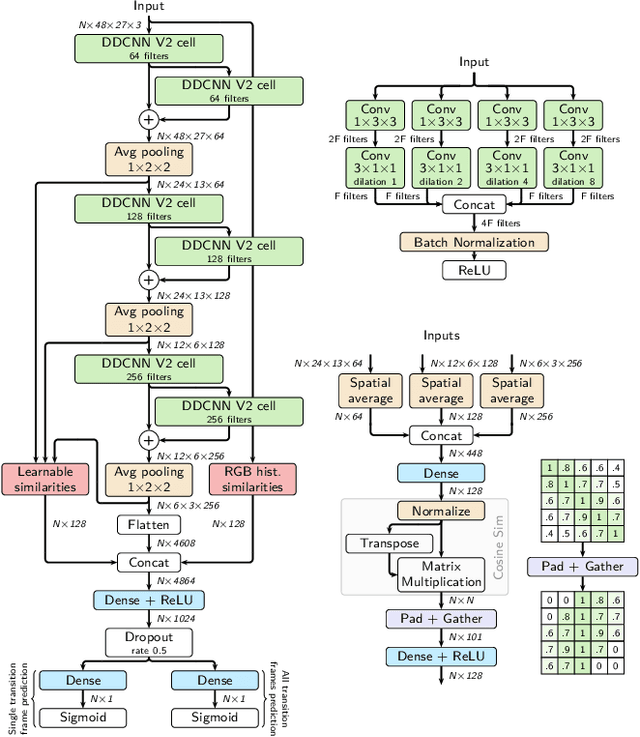
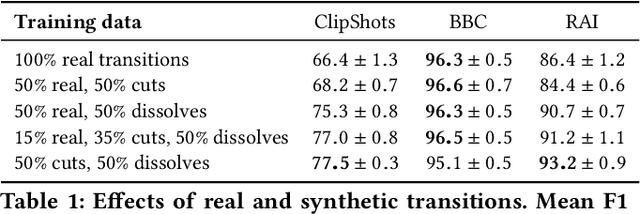


Although automatic shot transition detection approaches are already investigated for more than two decades, an effective universal human-level model was not proposed yet. Even for common shot transitions like hard cuts or simple gradual changes, the potential diversity of analyzed video contents may still lead to both false hits and false dismissals. Recently, deep learning-based approaches significantly improved the accuracy of shot transition detection using 3D convolutional architectures and artificially created training data. Nevertheless, one hundred percent accuracy is still an unreachable ideal. In this paper, we share the current version of our deep network TransNet V2 that reaches state-of-the-art performance on respected benchmarks. A trained instance of the model is provided so it can be instantly utilized by the community for a highly efficient analysis of large video archives. Furthermore, the network architecture, as well as our experience with the training process, are detailed, including simple code snippets for convenient usage of the proposed model and visualization of results.
TransNet: A deep network for fast detection of common shot transitions
Jun 08, 2019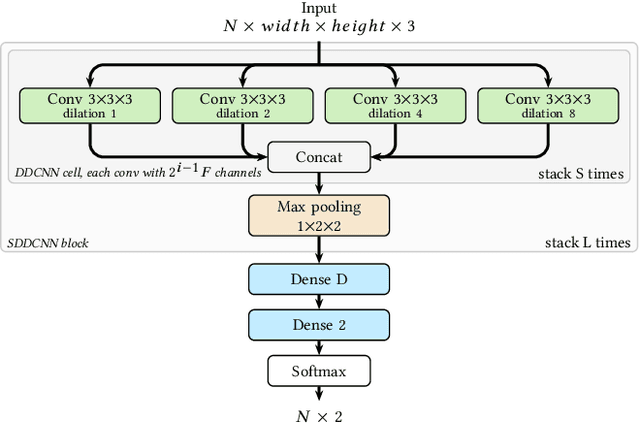
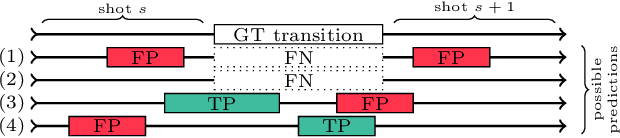
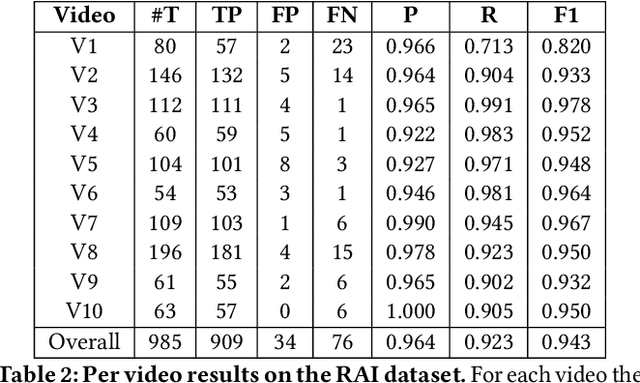

Shot boundary detection (SBD) is an important first step in many video processing applications. This paper presents a simple modular convolutional neural network architecture that achieves state-of-the-art results on the RAI dataset with well above real-time inference speed even on a single mediocre GPU. The network employs dilated convolutions and operates just on small resized frames. The training process employed randomly generated transitions using selected shots from the TRECVID IACC.3 dataset. The code and a selected trained network will be available at https://github.com/soCzech/TransNet.