 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyLLM: Efficient Diffusion LLM Inference via Saliency-based Token Selection and Partial Attention
Mar 09, 2026Masked Diffusion Language Models (MDLMs) enable parallel token decoding, providing a promising alternative to the sequential nature of autoregressive generation. However, their iterative denoising process remains computationally expensive because it repeatedly processes the entire sequence at every step. We observe that across these diffusion steps, most token representations remain stable; only a small subset, which we term salient tokens, contributes meaningfully to the next update. Leveraging this temporal sparsity, we present DyLLM, a training-free inference framework that accelerates decoding by selectively computing only these salient tokens. DyLLM identifies saliency by measuring the cosine similarity of attention contexts between adjacent denoising steps. It recomputes feed-forward and attention operations only for salient tokens while reusing cached activations for the remainder. Across diverse reasoning and code-generation benchmarks, DyLLM achieves up to 9.6x higher throughput while largely preserving the baseline accuracy of state-of-the-art models like LLaDA and Dream.
From Tokens to Layers: Redefining Stall-Free Scheduling for LLM Serving with Layered Prefill
Oct 09, 2025Large Language Model (LLM) inference in production must meet stringent service-level objectives for both time-to-first-token (TTFT) and time-between-token (TBT) while maximizing throughput under fixed compute, memory, and interconnect budgets. Modern serving systems adopt stall-free scheduling techniques such as chunked prefill, which splits long prompt processing along the token dimension and interleaves prefill with ongoing decode iterations. While effective at stabilizing TBT, chunked prefill incurs substantial overhead in Mixture-of-Experts (MoE) models: redundant expert weight loads increase memory traffic by up to 39% and inflate energy consumption. We propose layered prefill, a new scheduling paradigm that treats transformer layer groups as the primary scheduling unit. By vertically partitioning the model into contiguous layer groups and interleaving prefill and decode across the groups, layered prefill sustains stall-free decoding while eliminating chunk-induced MoE weight reloads. It reduces off-chip bandwidth demand, lowering TTFT by up to 70%, End-to-End latency by 41% and per-token energy by up to 22%. Evaluations show that layered prefill consistently improves the TTFT--TBT Pareto frontier over chunked prefill, reducing expert-load traffic and energy cost while maintaining stall-free decoding. Overall, shifting the scheduling axis from tokens to layers unlocks a new operating regime for high-efficiency, energy-aware LLM serving in co-located environments.
NeuJeans: Private Neural Network Inference with Joint Optimization of Convolution and Bootstrapping
Dec 07, 2023Fully homomorphic encryption (FHE) is a promising cryptographic primitive for realizing private neural network inference (PI) services by allowing a client to fully offload the inference task to a cloud server while keeping the client data oblivious to the server. This work proposes NeuJeans, an FHE-based solution for the PI of deep convolutional neural networks (CNNs). NeuJeans tackles the critical problem of the enormous computational cost for the FHE evaluation of convolutional layers (conv2d), mainly due to the high cost of data reordering and bootstrapping. We first propose an encoding method introducing nested structures inside encoded vectors for FHE, which enables us to develop efficient conv2d algorithms with reduced data reordering costs. However, the new encoding method also introduces additional computations for conversion between encoding methods, which could negate its advantages. We discover that fusing conv2d with bootstrapping eliminates such computations while reducing the cost of bootstrapping. Then, we devise optimized execution flows for various types of conv2d and apply them to end-to-end implementation of CNNs. NeuJeans accelerates the performance of conv2d by up to 5.68 times compared to state-of-the-art FHE-based PI work and performs the PI of a CNN at the scale of ImageNet (ResNet18) within a mere few seconds
HyPHEN: A Hybrid Packing Method and Optimizations for Homomorphic Encryption-Based Neural Networks
Feb 05, 2023Convolutional neural network (CNN) inference using fully homomorphic encryption (FHE) is a promising private inference (PI) solution due to the capability of FHE that enables offloading the whole computation process to the server while protecting the privacy of sensitive user data. However, prior FHEbased CNN (HCNN) implementations are far from being practical due to the high computational and memory overheads of FHE. To overcome this limitation, we present HyPHEN, a deep HCNN construction that features an efficient FHE convolution algorithm, data packing methods (hybrid packing and image slicing), and FHE-specific optimizations. Such enhancements enable HyPHEN to substantially reduce the memory footprint and the number of expensive homomorphic operations, such as ciphertext rotation and bootstrapping. As a result, HyPHEN brings the latency of HCNN CIFAR-10 inference down to a practical level at 1.40s (ResNet20) and demonstrates HCNN ImageNet inference for the first time at 16.87s (ResNet18).
AESPA: Accuracy Preserving Low-degree Polynomial Activation for Fast Private Inference
Jan 18, 2022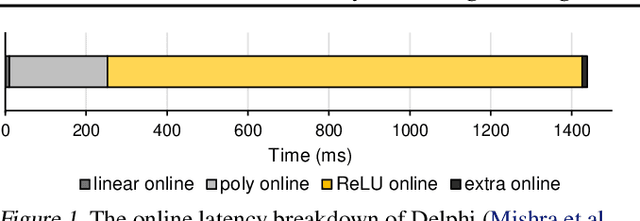
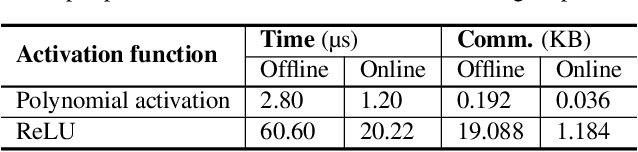
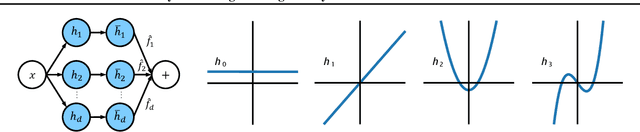
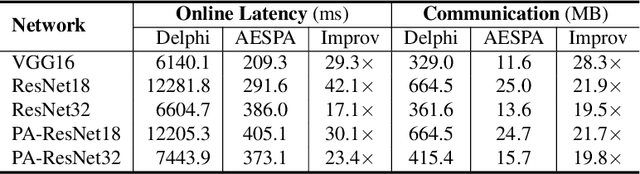
Hybrid private inference (PI) protocol, which synergistically utilizes both multi-party computation (MPC) and homomorphic encryption, is one of the most prominent techniques for PI. However, even the state-of-the-art PI protocols are bottlenecked by the non-linear layers, especially the activation functions. Although a standard non-linear activation function can generate higher model accuracy, it must be processed via a costly garbled-circuit MPC primitive. A polynomial activation can be processed via Beaver's multiplication triples MPC primitive but has been incurring severe accuracy drops so far. In this paper, we propose an accuracy preserving low-degree polynomial activation function (AESPA) that exploits the Hermite expansion of the ReLU and basis-wise normalization. We apply AESPA to popular ML models, such as VGGNet, ResNet, and pre-activation ResNet, to show an inference accuracy comparable to those of the standard models with ReLU activation, achieving superior accuracy over prior low-degree polynomial studies. When applied to the all-RELU baseline on the state-of-the-art Delphi PI protocol, AESPA shows up to 42.1x and 28.3x lower online latency and communication cost.