 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Alignment Protocol: Making Sense of the Unlabeled Data in New Domains
May 27, 2025



Semi-Supervised Federated Learning (SSFL) is gaining popularity over conventional Federated Learning in many real-world applications. Due to the practical limitation of limited labeled data on the client side, SSFL considers that participating clients train with unlabeled data, and only the central server has the necessary resources to access limited labeled data, making it an ideal fit for real-world applications (e.g., healthcare). However, traditional SSFL assumes that the data distributions in the training phase and testing phase are the same. In practice, however, domain shifts frequently occur, making it essential for SSFL to incorporate generalization capabilities and enhance their practicality. The core challenge is improving model generalization to new, unseen domains while the client participate in SSFL. However, the decentralized setup of SSFL and unsupervised client training necessitates innovation to achieve improved generalization across domains. To achieve this, we propose a novel framework called the Unified Alignment Protocol (UAP), which consists of an alternating two-stage training process. The first stage involves training the server model to learn and align the features with a parametric distribution, which is subsequently communicated to clients without additional communication overhead. The second stage proposes a novel training algorithm that utilizes the server feature distribution to align client features accordingly. Our extensive experiments on standard domain generalization benchmark datasets across multiple model architectures reveal that proposed UAP successfully achieves SOTA generalization performance in SSFL setting.
Learning to Linearize Deep Neural Networks for Secure and Efficient Private Inference
Jan 23, 2023



The large number of ReLU non-linearity operations in existing deep neural networks makes them ill-suited for latency-efficient private inference (PI). Existing techniques to reduce ReLU operations often involve manual effort and sacrifice significant accuracy. In this paper, we first present a novel measure of non-linearity layers' ReLU sensitivity, enabling mitigation of the time-consuming manual efforts in identifying the same. Based on this sensitivity, we then present SENet, a three-stage training method that for a given ReLU budget, automatically assigns per-layer ReLU counts, decides the ReLU locations for each layer's activation map, and trains a model with significantly fewer ReLUs to potentially yield latency and communication efficient PI. Experimental evaluations with multiple models on various datasets show SENet's superior performance both in terms of reduced ReLUs and improved classification accuracy compared to existing alternatives. In particular, SENet can yield models that require up to ~2x fewer ReLUs while yielding similar accuracy. For a similar ReLU budget SENet can yield models with ~2.32% improved classification accuracy, evaluated on CIFAR-100.
Regular Expressions for Fast-response COVID-19 Text Classification
Feb 19, 2021
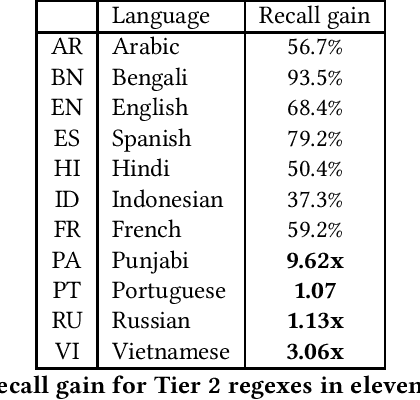
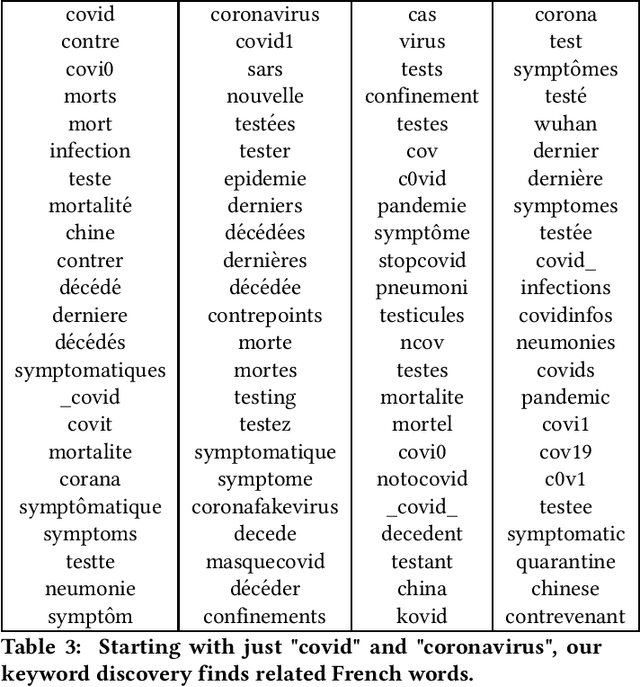

Text classifiers are at the core of many NLP applications and use a variety of algorithmic approaches and software. This paper describes how Facebook determines if a given piece of text - anything from a hashtag to a post - belongs to a narrow topic such as COVID-19. To fully define a topic and evaluate classifier performance we employ human-guided iterations of keyword discovery, but do not require labeled data. For COVID-19, we build two sets of regular expressions: (1) for 66 languages, with 99% precision and recall >50%, (2) for the 11 most common languages, with precision >90% and recall >90%. Regular expressions enable low-latency queries from multiple platforms. Response to challenges like COVID-19 is fast and so are revisions. Comparisons to a DNN classifier show explainable results, higher precision and recall, and less overfitting. Our learnings can be applied to other narrow-topic classifiers.