 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerging in a Bottle: Differentiable Adaptive Merging (DAM) and the Path from Averaging to Automation
Oct 10, 2024



By merging models, AI systems can combine the distinct strengths of separate language models, achieving a balance between multiple capabilities without requiring substantial retraining. However, the integration process can be intricate due to differences in training methods and fine-tuning, typically necessitating specialized knowledge and repeated refinement. This paper explores model merging techniques across a spectrum of complexity, examining where automated methods like evolutionary strategies stand compared to hyperparameter-driven approaches such as DARE, TIES-Merging and simpler methods like Model Soups. In addition, we introduce Differentiable Adaptive Merging (DAM), an efficient, adaptive merging approach as an alternative to evolutionary merging that optimizes model integration through scaling coefficients, minimizing computational demands. Our findings reveal that even simple averaging methods, like Model Soups, perform competitively when model similarity is high, underscoring each technique's unique strengths and limitations. We open-sourced DAM, including the implementation code and experiment pipeline, on GitHub: https://github.com/arcee-ai/DAM.
Domain Adaptation of Llama3-70B-Instruct through Continual Pre-Training and Model Merging: A Comprehensive Evaluation
Jun 21, 2024



We conducted extensive experiments on domain adaptation of the Meta-Llama-3-70B-Instruct model on SEC data, exploring its performance on both general and domain-specific benchmarks. Our focus included continual pre-training (CPT) and model merging, aiming to enhance the model's domain-specific capabilities while mitigating catastrophic forgetting. Through this study, we evaluated the impact of integrating financial regulatory data into a robust language model and examined the effectiveness of our model merging techniques in preserving and improving the model's instructive abilities. The model is accessible at hugging face: https://huggingface.co/arcee-ai/Llama-3-SEC-Base, arcee-ai/Llama-3-SEC-Base. This is an intermediate checkpoint of our final model, which has seen 20B tokens so far. The full model is still in the process of training. This is a preprint technical report with thorough evaluations to understand the entire process.
Arcee's MergeKit: A Toolkit for Merging Large Language Models
Mar 21, 2024The rapid expansion of the open-source language model landscape presents an opportunity to merge the competencies of these model checkpoints by combining their parameters. Advances in transfer learning, the process of fine-tuning pretrained models for specific tasks, has resulted in the development of vast amounts of task-specific models, typically specialized in individual tasks and unable to utilize each other's strengths. Model merging facilitates the creation of multitask models without the need for additional training, offering a promising avenue for enhancing model performance and versatility. By preserving the intrinsic capabilities of the original models, model merging addresses complex challenges in AI - including the difficulties of catastrophic forgetting and multitask learning. To support this expanding area of research, we introduce MergeKit, a comprehensive, open-source library designed to facilitate the application of model merging strategies. MergeKit offers an extensible framework to efficiently merge models on any hardware, providing utility to researchers and practitioners. To date, thousands of models have been merged by the open-source community, leading to the creation of some of the worlds most powerful open-source model checkpoints, as assessed by the Open LLM Leaderboard. The library is accessible at https://github.com/arcee-ai/MergeKit.
Roboflow 100: A Rich, Multi-Domain Object Detection Benchmark
Nov 30, 2022



The evaluation of object detection models is usually performed by optimizing a single metric, e.g. mAP, on a fixed set of datasets, e.g. Microsoft COCO and Pascal VOC. Due to image retrieval and annotation costs, these datasets consist largely of images found on the web and do not represent many real-life domains that are being modelled in practice, e.g. satellite, microscopic and gaming, making it difficult to assert the degree of generalization learned by the model. We introduce the Roboflow-100 (RF100) consisting of 100 datasets, 7 imagery domains, 224,714 images, and 805 class labels with over 11,170 labelling hours. We derived RF100 from over 90,000 public datasets, 60 million public images that are actively being assembled and labelled by computer vision practitioners in the open on the web application Roboflow Universe. By releasing RF100, we aim to provide a semantically diverse, multi-domain benchmark of datasets to help researchers test their model's generalizability with real-life data. RF100 download and benchmark replication are available on GitHub.
LSOIE: A Large-Scale Dataset for Supervised Open Information Extraction
Jan 27, 2021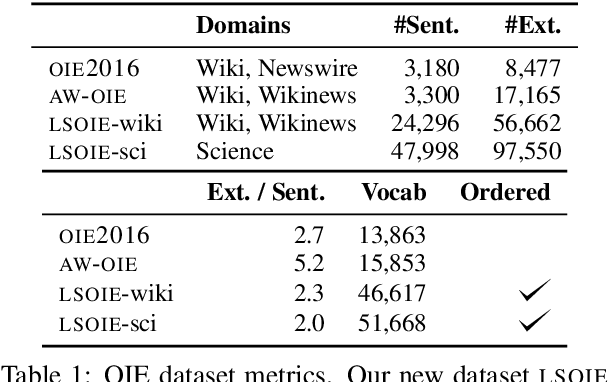
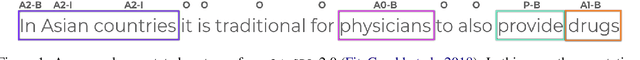
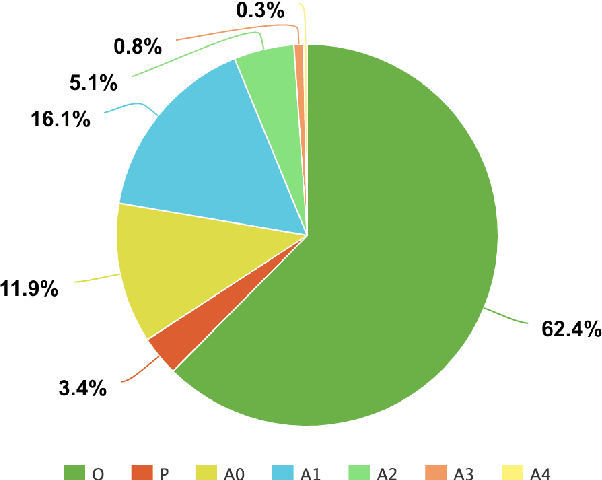

Open Information Extraction (OIE) systems seek to compress the factual propositions of a sentence into a series of n-ary tuples. These tuples are useful for downstream tasks in natural language processing like knowledge base creation, textual entailment, and natural language understanding. However, current OIE datasets are limited in both size and diversity. We introduce a new dataset by converting the QA-SRL 2.0 dataset to a large-scale OIE dataset (LSOIE). Our LSOIE dataset is 20 times larger than the next largest human-annotated OIE dataset. We construct and evaluate several benchmark OIE models on LSOIE, providing baselines for future improvements on the task. Our LSOIE data, models, and code are made publicly available