 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal horizons in forecasting: a performance-learnability trade-off
Jun 04, 2025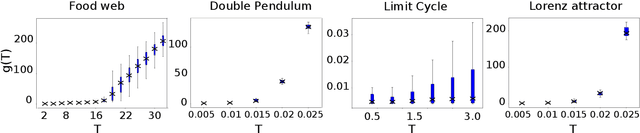
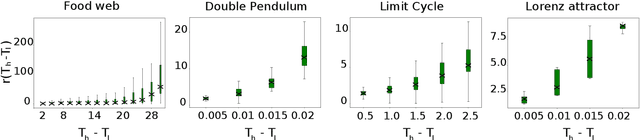
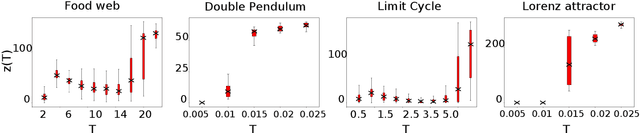
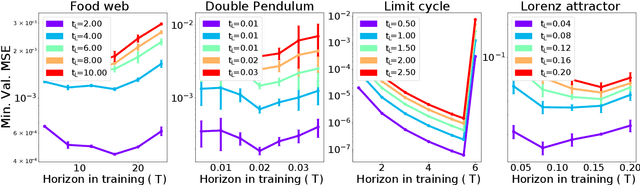
When training autoregressive models for dynamical systems, a critical question arises: how far into the future should the model be trained to predict? Too short a horizon may miss long-term trends, while too long a horizon can impede convergence due to accumulating prediction errors. In this work, we formalize this trade-off by analyzing how the geometry of the loss landscape depends on the training horizon. We prove that for chaotic systems, the loss landscape's roughness grows exponentially with the training horizon, while for limit cycles, it grows linearly, making long-horizon training inherently challenging. However, we also show that models trained on long horizons generalize well to short-term forecasts, whereas those trained on short horizons suffer exponentially (resp. linearly) worse long-term predictions in chaotic (resp. periodic) systems. We validate our theory through numerical experiments and discuss practical implications for selecting training horizons. Our results provide a principled foundation for hyperparameter optimization in autoregressive forecasting models.
Governing dual-use technologies: Case studies of international security agreements and lessons for AI governance
Sep 04, 2024



International AI governance agreements and institutions may play an important role in reducing global security risks from advanced AI. To inform the design of such agreements and institutions, we conducted case studies of historical and contemporary international security agreements. We focused specifically on those arrangements around dual-use technologies, examining agreements in nuclear security, chemical weapons, biosecurity, and export controls. For each agreement, we examined four key areas: (a) purpose, (b) core powers, (c) governance structure, and (d) instances of non-compliance. From these case studies, we extracted lessons for the design of international AI agreements and governance institutions. We discuss the importance of robust verification methods, strategies for balancing power between nations, mechanisms for adapting to rapid technological change, approaches to managing trade-offs between transparency and security, incentives for participation, and effective enforcement mechanisms.
Verification methods for international AI agreements
Aug 28, 2024



What techniques can be used to verify compliance with international agreements about advanced AI development? In this paper, we examine 10 verification methods that could detect two types of potential violations: unauthorized AI training (e.g., training runs above a certain FLOP threshold) and unauthorized data centers. We divide the verification methods into three categories: (a) national technical means (methods requiring minimal or no access from suspected non-compliant nations), (b) access-dependent methods (methods that require approval from the nation suspected of unauthorized activities), and (c) hardware-dependent methods (methods that require rules around advanced hardware). For each verification method, we provide a description, historical precedents, and possible evasion techniques. We conclude by offering recommendations for future work related to the verification and enforcement of international AI governance agreements.