 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal horizons in forecasting: a performance-learnability trade-off
Paper and Code
Jun 04, 2025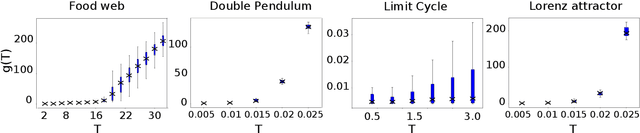
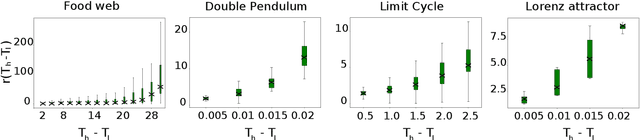
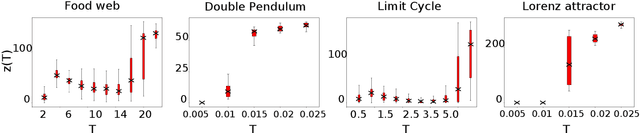
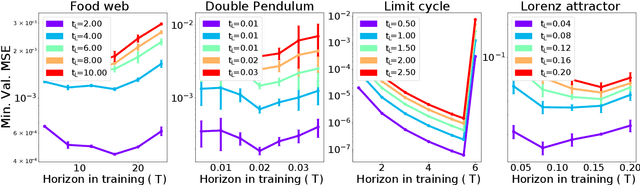
When training autoregressive models for dynamical systems, a critical question arises: how far into the future should the model be trained to predict? Too short a horizon may miss long-term trends, while too long a horizon can impede convergence due to accumulating prediction errors. In this work, we formalize this trade-off by analyzing how the geometry of the loss landscape depends on the training horizon. We prove that for chaotic systems, the loss landscape's roughness grows exponentially with the training horizon, while for limit cycles, it grows linearly, making long-horizon training inherently challenging. However, we also show that models trained on long horizons generalize well to short-term forecasts, whereas those trained on short horizons suffer exponentially (resp. linearly) worse long-term predictions in chaotic (resp. periodic) systems. We validate our theory through numerical experiments and discuss practical implications for selecting training horizons. Our results provide a principled foundation for hyperparameter optimization in autoregressive forecasting models.