 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagentic-UI: Towards Human-in-the-loop Agentic Systems
Jul 30, 2025AI agents powered by large language models are increasingly capable of autonomously completing complex, multi-step tasks using external tools. Yet, they still fall short of human-level performance in most domains including computer use, software development, and research. Their growing autonomy and ability to interact with the outside world, also introduces safety and security risks including potentially misaligned actions and adversarial manipulation. We argue that human-in-the-loop agentic systems offer a promising path forward, combining human oversight and control with AI efficiency to unlock productivity from imperfect systems. We introduce Magentic-UI, an open-source web interface for developing and studying human-agent interaction. Built on a flexible multi-agent architecture, Magentic-UI supports web browsing, code execution, and file manipulation, and can be extended with diverse tools via Model Context Protocol (MCP). Moreover, Magentic-UI presents six interaction mechanisms for enabling effective, low-cost human involvement: co-planning, co-tasking, multi-tasking, action guards, and long-term memory. We evaluate Magentic-UI across four dimensions: autonomous task completion on agentic benchmarks, simulated user testing of its interaction capabilities, qualitative studies with real users, and targeted safety assessments. Our findings highlight Magentic-UI's potential to advance safe and efficient human-agent collaboration.
Interactive Debugging and Steering of Multi-Agent AI Systems
Mar 03, 2025Fully autonomous teams of LLM-powered AI agents are emerging that collaborate to perform complex tasks for users. What challenges do developers face when trying to build and debug these AI agent teams? In formative interviews with five AI agent developers, we identify core challenges: difficulty reviewing long agent conversations to localize errors, lack of support in current tools for interactive debugging, and the need for tool support to iterate on agent configuration. Based on these needs, we developed an interactive multi-agent debugging tool, AGDebugger, with a UI for browsing and sending messages, the ability to edit and reset prior agent messages, and an overview visualization for navigating complex message histories. In a two-part user study with 14 participants, we identify common user strategies for steering agents and highlight the importance of interactive message resets for debugging. Our studies deepen understanding of interfaces for debugging increasingly important agentic workflows.
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Nov 07, 2024



Modern AI agents, driven by advances in large foundation models, promise to enhance our productivity and transform our lives by augmenting our knowledge and capabilities. To achieve this vision, AI agents must effectively plan, perform multi-step reasoning and actions, respond to novel observations, and recover from errors, to successfully complete complex tasks across a wide range of scenarios. In this work, we introduce Magentic-One, a high-performing open-source agentic system for solving such tasks. Magentic-One uses a multi-agent architecture where a lead agent, the Orchestrator, plans, tracks progress, and re-plans to recover from errors. Throughout task execution, the Orchestrator directs other specialized agents to perform tasks as needed, such as operating a web browser, navigating local files, or writing and executing Python code. We show that Magentic-One achieves statistically competitive performance to the state-of-the-art on three diverse and challenging agentic benchmarks: GAIA, AssistantBench, and WebArena. Magentic-One achieves these results without modification to core agent capabilities or to how they collaborate, demonstrating progress towards generalist agentic systems. Moreover, Magentic-One's modular design allows agents to be added or removed from the team without additional prompt tuning or training, easing development and making it extensible to future scenarios. We provide an open-source implementation of Magentic-One, and we include AutoGenBench, a standalone tool for agentic evaluation. AutoGenBench provides built-in controls for repetition and isolation to run agentic benchmarks in a rigorous and contained manner -- which is important when agents' actions have side-effects. Magentic-One, AutoGenBench and detailed empirical performance evaluations of Magentic-One, including ablations and error analysis are available at https://aka.ms/magentic-one
Resonance: Replacing Software Constants with Context-Aware Models in Real-time Communication
Nov 23, 2020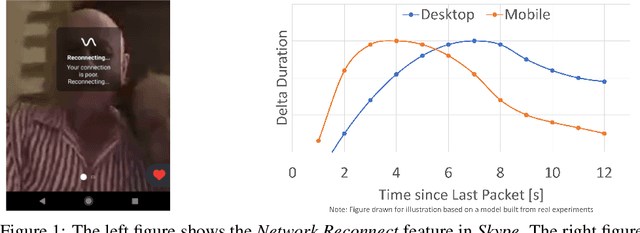


Large software systems tune hundreds of 'constants' to optimize their runtime performance. These values are commonly derived through intuition, lab tests, or A/B tests. A 'one-size-fits-all' approach is often sub-optimal as the best value depends on runtime context. In this paper, we provide an experimental approach to replace constants with learned contextual functions for Skype - a widely used real-time communication (RTC) application. We present Resonance, a system based on contextual bandits (CB). We describe experiences from three real-world experiments: applying it to the audio, video, and transport components in Skype. We surface a unique and practical challenge of performing machine learning (ML) inference in large software systems written using encapsulation principles. Finally, we open-source FeatureBroker, a library to reduce the friction in adopting ML models in such development environments