 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfusion matrices and rough set data analysis
Feb 04, 2019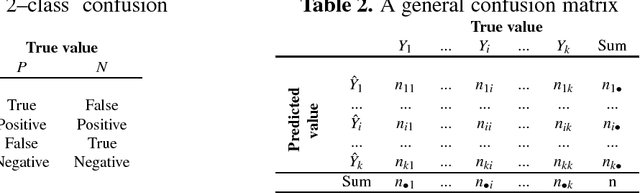

A widespread approach in machine learning to evaluate the quality of a classifier is to cross -- classify predicted and actual decision classes in a confusion matrix, also called error matrix. A classification tool which does not assume distributional parameters but only information contained in the data is based on the rough set data model which assumes that knowledge is given only up to a certain granularity. Using this assumption and the technique of confusion matrices, we define various indices and classifiers based on rough confusion matrices.
Approximation by filter functions
Jun 20, 2018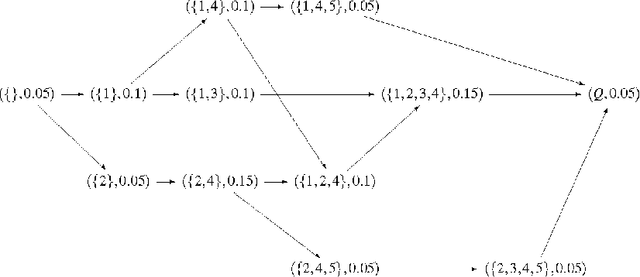
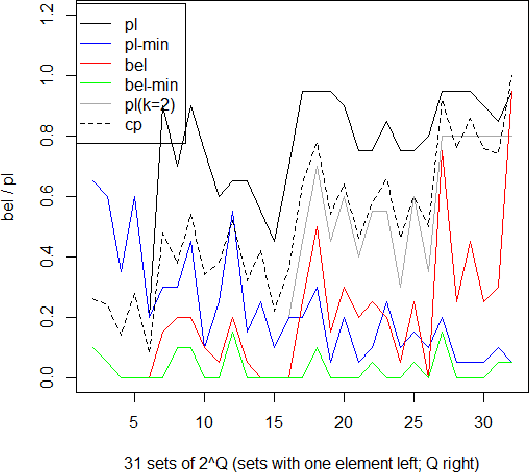
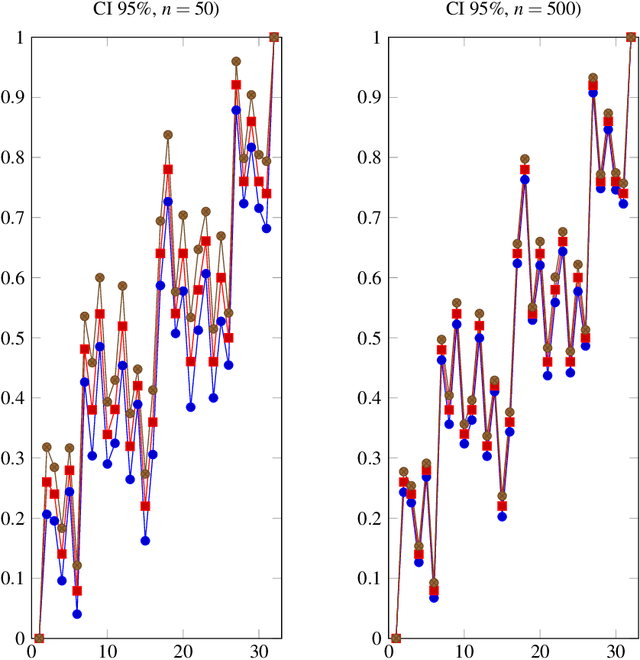
In this exploratory article, we draw attention to the common formal ground among various estimators such as the belief functions of evidence theory and their relatives, approximation quality of rough set theory, and contextual probability. The unifying concept will be a general filter function composed of a basic probability and a weighting which varies according to the problem at hand. To compare the various filter functions we conclude with a simulation study with an example from the area of item response theory.