 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeapp.build: A Production Framework for Scaling Agentic Prompt-to-App Generation with Environment Scaffolding
Sep 03, 2025



We present app.build (https://github.com/appdotbuild/agent/), an open-source framework that improves LLM-based application generation through systematic validation and structured environments. Our approach combines multi-layered validation pipelines, stack-specific orchestration, and model-agnostic architecture, implemented across three reference stacks. Through evaluation on 30 generation tasks, we demonstrate that comprehensive validation achieves 73.3% viability rate with 30% reaching perfect quality scores, while open-weights models achieve 80.8% of closed-model performance when provided structured environments. The open-source framework has been adopted by the community, with over 3,000 applications generated to date. This work demonstrates that scaling reliable AI agents requires scaling environments, not just models -- providing empirical insights and complete reference implementations for production-oriented agent systems.
Transfer of Structural Knowledge from Synthetic Languages
May 21, 2025This work explores transfer learning from several synthetic languages to English. We investigate the structure of the embeddings in the fine-tuned models, the information they contain, and the capabilities of the fine-tuned models on simple linguistic tasks. We also introduce a new synthetic language that leads to better transfer to English than the languages used in previous research. Finally, we introduce Tiny-Cloze Benchmark - a new synthetic benchmark for natural language understanding that is more informative for less powerful models. We use Tiny-Cloze Benchmark to evaluate fine-tuned models in several domains demonstrating that fine-tuning on a new synthetic language allows for better performance on a variety of tasks.
Style-transfer and Paraphrase: Looking for a Sensible Semantic Similarity Metric
Apr 10, 2020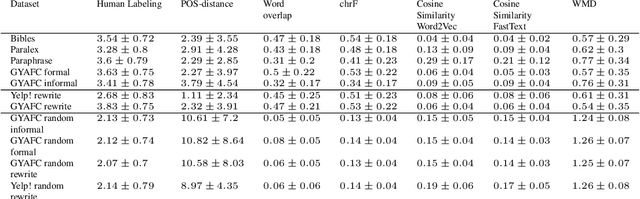
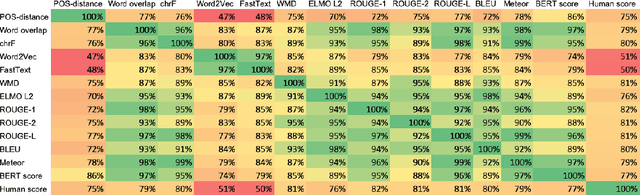
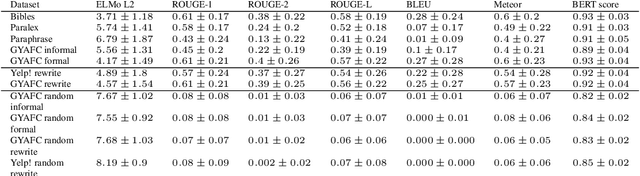
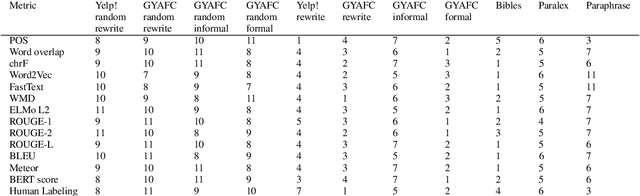
The rapid development of such natural language processing tasks as style transfer, paraphrase, and machine translation often calls for the use of semantic preservation metrics. In recent years a lot of methods to control the semantic similarity of two short texts were developed. This paper provides a comprehensive analysis for more than a dozen of such methods. Using a new dataset of fourteen thousand sentence pairs human-labeled according to their semantic similarity, we demonstrate that none of the metrics widely used in the literature is close enough to human judgment to be used on its own in these tasks. The recently proposed Word Mover's Distance (WMD), along with bilingual evaluation understudy (BLEU) and part-of-speech (POS) distance, seem to form a reasonable complex solution to measure semantic preservation in reformulated texts. We encourage the research community to use the ensemble of these metrics until a better solution is found.