 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFix your classifier: the marginal value of training the last weight layer
Mar 20, 2018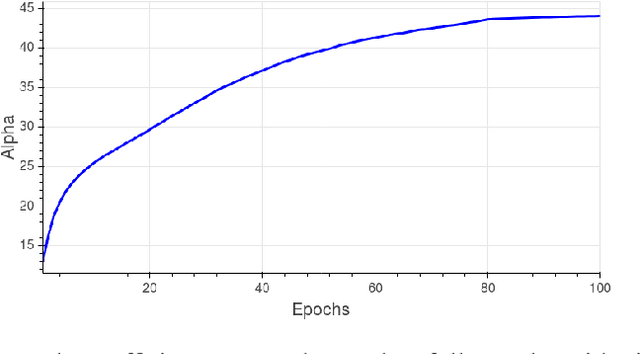


Neural networks are commonly used as models for classification for a wide variety of tasks. Typically, a learned affine transformation is placed at the end of such models, yielding a per-class value used for classification. This classifier can have a vast number of parameters, which grows linearly with the number of possible classes, thus requiring increasingly more resources. In this work we argue that this classifier can be fixed, up to a global scale constant, with little or no loss of accuracy for most tasks, allowing memory and computational benefits. Moreover, we show that by initializing the classifier with a Hadamard matrix we can speed up inference as well. We discuss the implications for current understanding of neural network models.
* https://openreview.net/forum?id=S1Dh8Tg0-
Train longer, generalize better: closing the generalization gap in large batch training of neural networks
Jan 01, 2018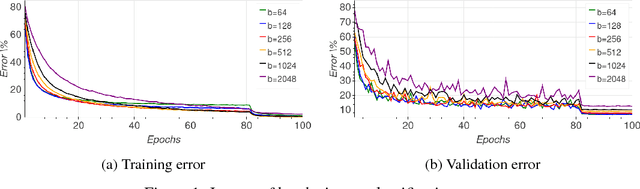
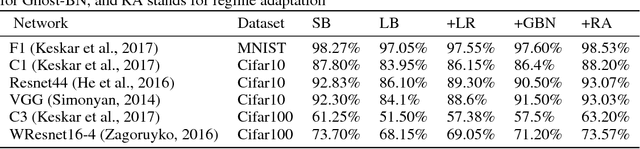
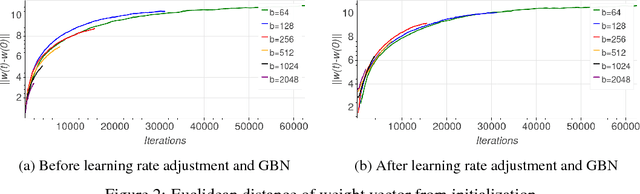

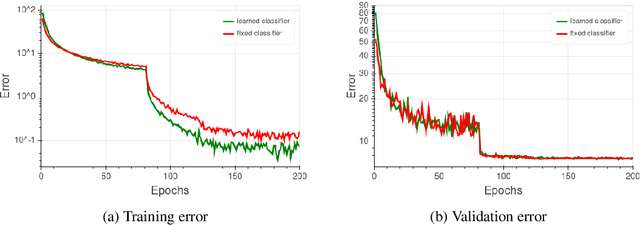
Background: Deep learning models are typically trained using stochastic gradient descent or one of its variants. These methods update the weights using their gradient, estimated from a small fraction of the training data. It has been observed that when using large batch sizes there is a persistent degradation in generalization performance - known as the "generalization gap" phenomena. Identifying the origin of this gap and closing it had remained an open problem. Contributions: We examine the initial high learning rate training phase. We find that the weight distance from its initialization grows logarithmically with the number of weight updates. We therefore propose a "random walk on random landscape" statistical model which is known to exhibit similar "ultra-slow" diffusion behavior. Following this hypothesis we conducted experiments to show empirically that the "generalization gap" stems from the relatively small number of updates rather than the batch size, and can be completely eliminated by adapting the training regime used. We further investigate different techniques to train models in the large-batch regime and present a novel algorithm named "Ghost Batch Normalization" which enables significant decrease in the generalization gap without increasing the number of updates. To validate our findings we conduct several additional experiments on MNIST, CIFAR-10, CIFAR-100 and ImageNet. Finally, we reassess common practices and beliefs concerning training of deep models and suggest they may not be optimal to achieve good generalization.
Playing SNES in the Retro Learning Environment
Feb 07, 2017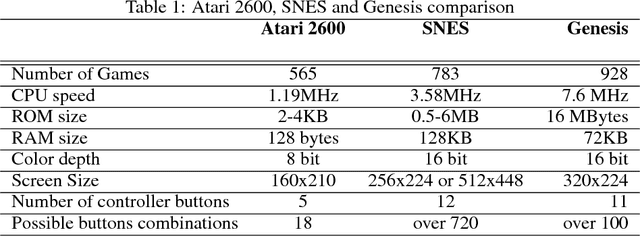


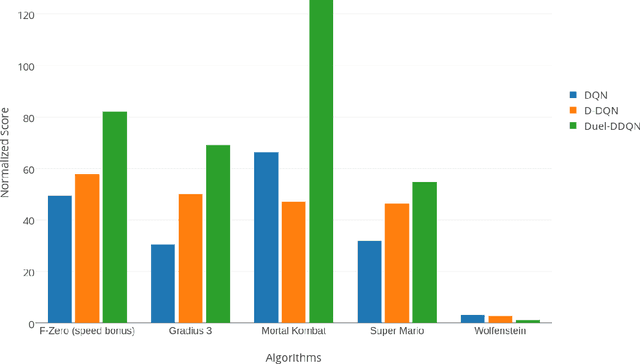
Mastering a video game requires skill, tactics and strategy. While these attributes may be acquired naturally by human players, teaching them to a computer program is a far more challenging task. In recent years, extensive research was carried out in the field of reinforcement learning and numerous algorithms were introduced, aiming to learn how to perform human tasks such as playing video games. As a result, the Arcade Learning Environment (ALE) (Bellemare et al., 2013) has become a commonly used benchmark environment allowing algorithms to train on various Atari 2600 games. In many games the state-of-the-art algorithms outperform humans. In this paper we introduce a new learning environment, the Retro Learning Environment --- RLE, that can run games on the Super Nintendo Entertainment System (SNES), Sega Genesis and several other gaming consoles. The environment is expandable, allowing for more video games and consoles to be easily added to the environment, while maintaining the same interface as ALE. Moreover, RLE is compatible with Python and Torch. SNES games pose a significant challenge to current algorithms due to their higher level of complexity and versatility.
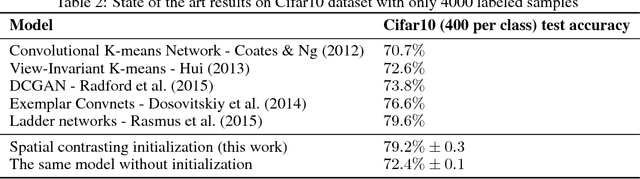
Spatial contrasting for deep unsupervised learning
Nov 21, 2016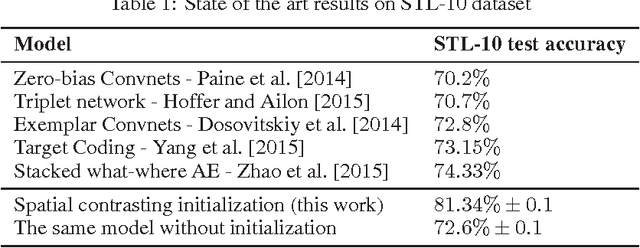
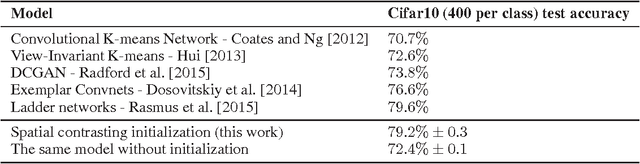
Convolutional networks have marked their place over the last few years as the best performing model for various visual tasks. They are, however, most suited for supervised learning from large amounts of labeled data. Previous attempts have been made to use unlabeled data to improve model performance by applying unsupervised techniques. These attempts require different architectures and training methods. In this work we present a novel approach for unsupervised training of Convolutional networks that is based on contrasting between spatial regions within images. This criterion can be employed within conventional neural networks and trained using standard techniques such as SGD and back-propagation, thus complementing supervised methods.
Deep unsupervised learning through spatial contrasting
Oct 02, 2016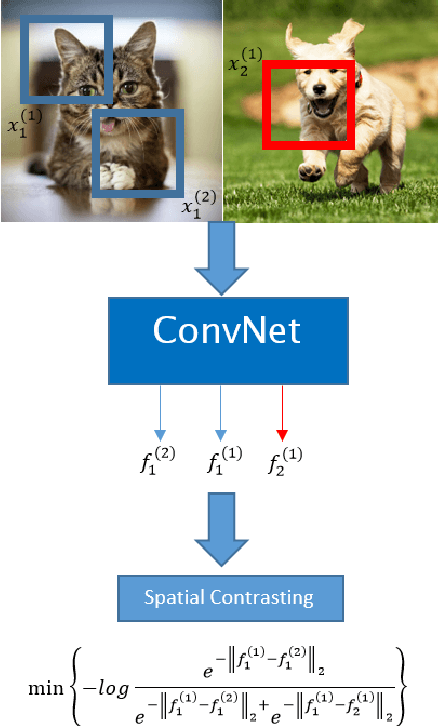
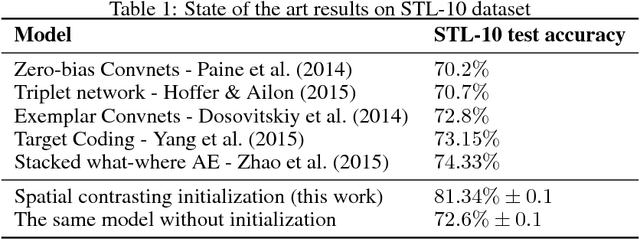

Convolutional networks have marked their place over the last few years as the best performing model for various visual tasks. They are, however, most suited for supervised learning from large amounts of labeled data. Previous attempts have been made to use unlabeled data to improve model performance by applying unsupervised techniques. These attempts require different architectures and training methods. In this work we present a novel approach for unsupervised training of Convolutional networks that is based on contrasting between spatial regions within images. This criterion can be employed within conventional neural networks and trained using standard techniques such as SGD and back-propagation, thus complementing supervised methods.
Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations
Sep 22, 2016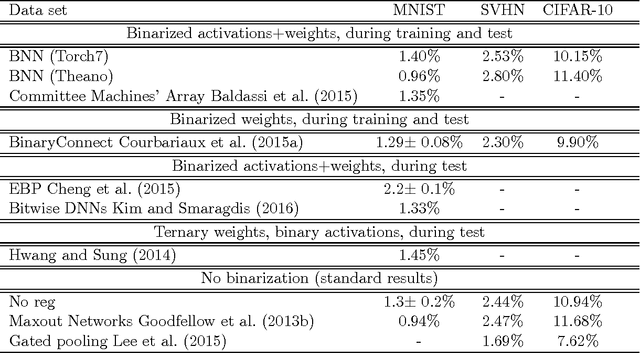
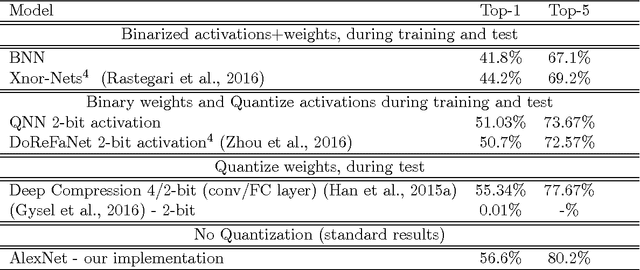
We introduce a method to train Quantized Neural Networks (QNNs) --- neural networks with extremely low precision (e.g., 1-bit) weights and activations, at run-time. At train-time the quantized weights and activations are used for computing the parameter gradients. During the forward pass, QNNs drastically reduce memory size and accesses, and replace most arithmetic operations with bit-wise operations. As a result, power consumption is expected to be drastically reduced. We trained QNNs over the MNIST, CIFAR-10, SVHN and ImageNet datasets. The resulting QNNs achieve prediction accuracy comparable to their 32-bit counterparts. For example, our quantized version of AlexNet with 1-bit weights and 2-bit activations achieves $51\%$ top-1 accuracy. Moreover, we quantize the parameter gradients to 6-bits as well which enables gradients computation using only bit-wise operation. Quantized recurrent neural networks were tested over the Penn Treebank dataset, and achieved comparable accuracy as their 32-bit counterparts using only 4-bits. Last but not least, we programmed a binary matrix multiplication GPU kernel with which it is possible to run our MNIST QNN 7 times faster than with an unoptimized GPU kernel, without suffering any loss in classification accuracy. The QNN code is available online.
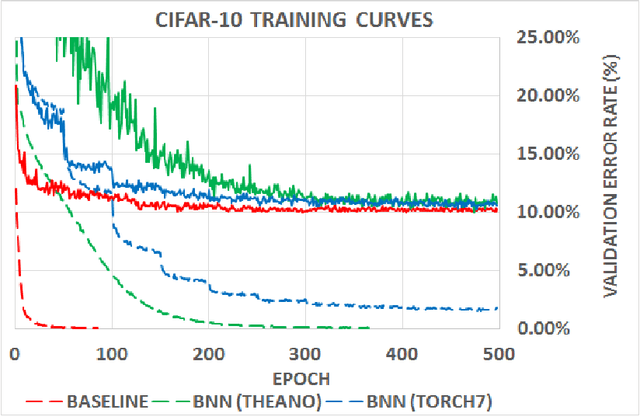
Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1
Mar 17, 2016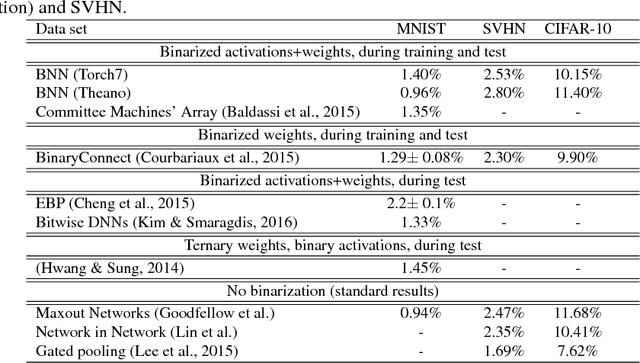
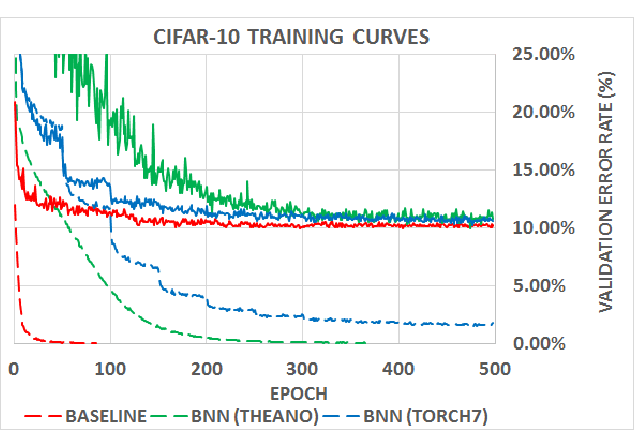

We introduce a method to train Binarized Neural Networks (BNNs) - neural networks with binary weights and activations at run-time. At training-time the binary weights and activations are used for computing the parameters gradients. During the forward pass, BNNs drastically reduce memory size and accesses, and replace most arithmetic operations with bit-wise operations, which is expected to substantially improve power-efficiency. To validate the effectiveness of BNNs we conduct two sets of experiments on the Torch7 and Theano frameworks. On both, BNNs achieved nearly state-of-the-art results over the MNIST, CIFAR-10 and SVHN datasets. Last but not least, we wrote a binary matrix multiplication GPU kernel with which it is possible to run our MNIST BNN 7 times faster than with an unoptimized GPU kernel, without suffering any loss in classification accuracy. The code for training and running our BNNs is available on-line.
Binarized Neural Networks
Mar 10, 2016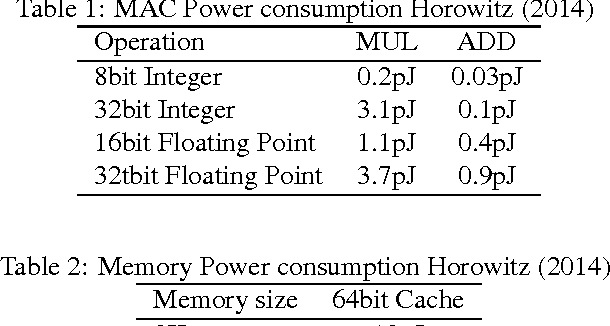
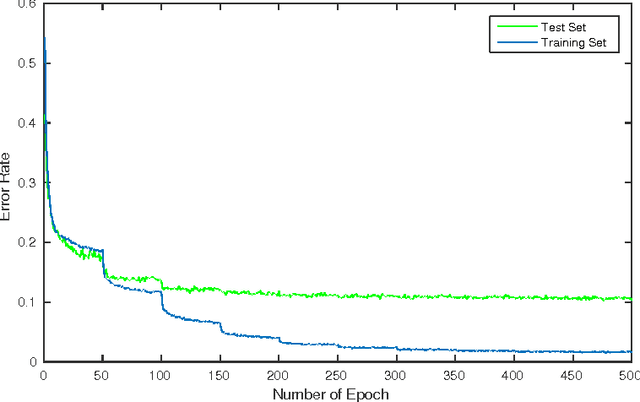

We introduce a method to train Binarized Neural Networks (BNNs) - neural networks with binary weights and activations at run-time and when computing the parameters' gradient at train-time. We conduct two sets of experiments, each based on a different framework, namely Torch7 and Theano, where we train BNNs on MNIST, CIFAR-10 and SVHN, and achieve nearly state-of-the-art results. During the forward pass, BNNs drastically reduce memory size and accesses, and replace most arithmetic operations with bit-wise operations, which might lead to a great increase in power-efficiency. Last but not least, we wrote a binary matrix multiplication GPU kernel with which it is possible to run our MNIST BNN 7 times faster than with an unoptimized GPU kernel, without suffering any loss in classification accuracy. The code for training and running our BNNs is available.