 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Taxi Carpool Policies via Reinforcement Learning and Spatio-Temporal Mining
Nov 11, 2018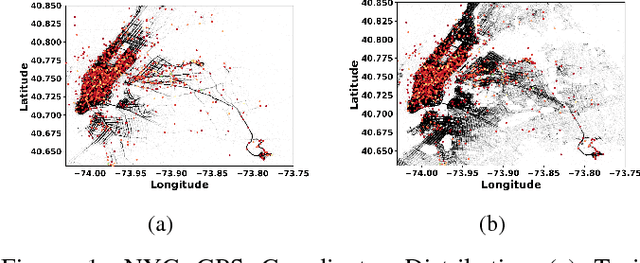
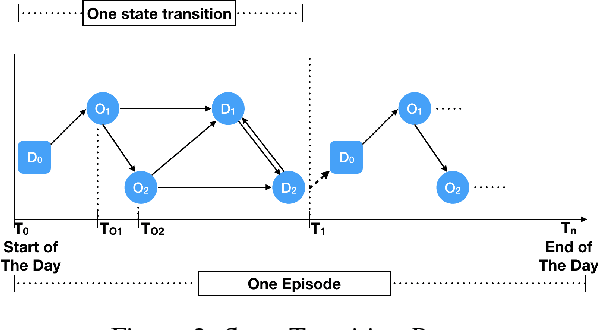

In this paper, we develop a reinforcement learning (RL) based system to learn an effective policy for carpooling that maximizes transportation efficiency so that fewer cars are required to fulfill the given amount of trip demand. For this purpose, first, we develop a deep neural network model, called ST-NN (Spatio-Temporal Neural Network), to predict taxi trip time from the raw GPS trip data. Secondly, we develop a carpooling simulation environment for RL training, with the output of ST-NN and using the NYC taxi trip dataset. In order to maximize transportation efficiency and minimize traffic congestion, we choose the effective distance covered by the driver on a carpool trip as the reward. Therefore, the more effective distance a driver achieves over a trip (i.e. to satisfy more trip demand) the higher the efficiency and the less will be the traffic congestion. We compared the performance of RL learned policy to a fixed policy (which always accepts carpool) as a baseline and obtained promising results that are interpretable and demonstrate the advantage of our RL approach. We also compare the performance of ST-NN to that of state-of-the-art travel time estimation methods and observe that ST-NN significantly improves the prediction performance and is more robust to outliers.
Tensor Matched Kronecker-Structured Subspace Detection for Missing Information
Oct 25, 2018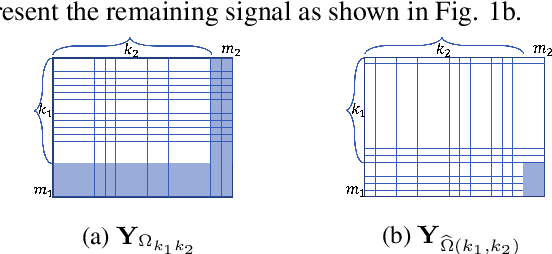
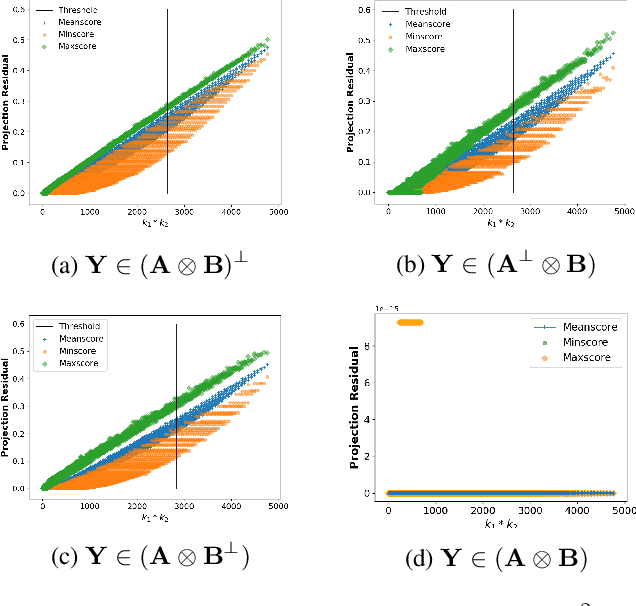
We consider the problem of detecting whether a tensor signal having many missing entities lies within a given low dimensional Kronecker-Structured (KS) subspace. This is a matched subspace detection problem. Tensor matched subspace detection problem is more challenging because of the intertwined signal dimensions. We solve this problem by projecting the signal onto the Kronecker structured subspace, which is a Kronecker product of different subspaces corresponding to each signal dimension. Under this framework, we define the KS subspaces and the orthogonal projection of the signal onto the KS subspace. We prove that reliable detection is possible as long as the cardinality of the missing signal is greater than the dimensions of the KS subspace by bounding the residual energy of the sampling signal with high probability.
Classification and Representation via Separable Subspaces: Performance Limits and Algorithms
Dec 29, 2017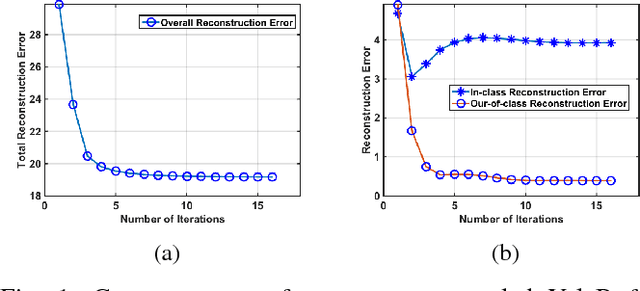
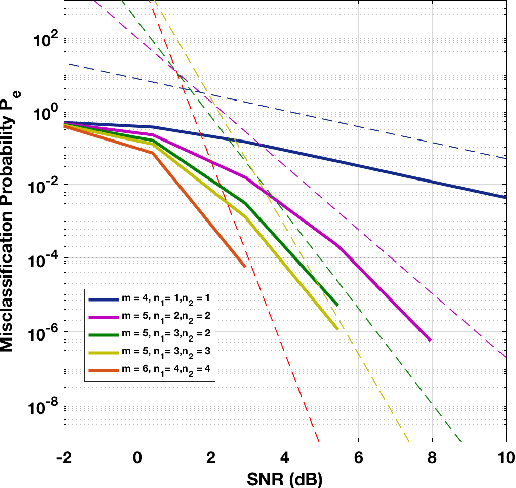
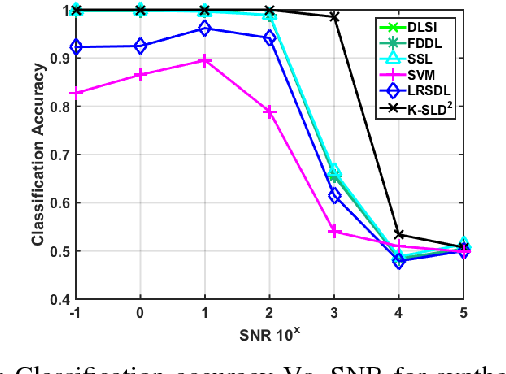

We study the classification performance of Kronecker-structured models in two asymptotic regimes and developed an algorithm for separable, fast and compact K-S dictionary learning for better classification and representation of multidimensional signals by exploiting the structure in the signal. First, we study the classification performance in terms of diversity order and pairwise geometry of the subspaces. We derive an exact expression for the diversity order as a function of the signal and subspace dimensions of a K-S model. Next, we study the classification capacity, the maximum rate at which the number of classes can grow as the signal dimension goes to infinity. Then we describe a fast algorithm for Kronecker-Structured Learning of Discriminative Dictionaries (K-SLD2). Finally, we evaluate the empirical classification performance of K-S models for the synthetic data, showing that they agree with the diversity order analysis. We also evaluate the performance of K-SLD2 on synthetic and real-world datasets showing that the K-SLD2 balances compact signal representation and good classification performance.
* This paper is submitted to IEEE JSTSP Special Issue on Information-Theoretic Methods in Data Acquisition, Analysis, and Processing 2018
A Unified Neural Network Approach for Estimating Travel Time and Distance for a Taxi Trip
Oct 12, 2017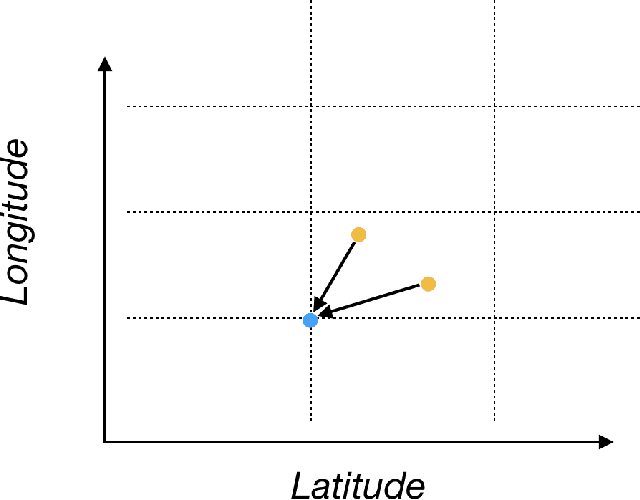
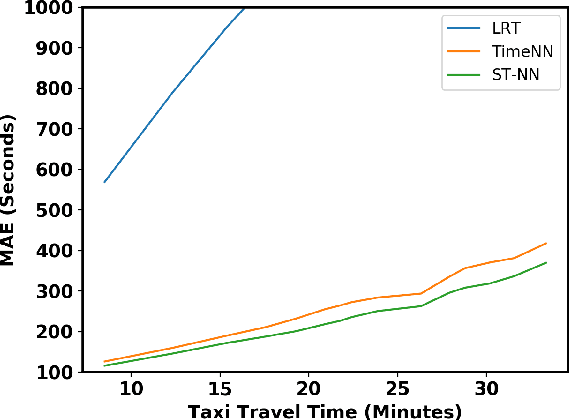
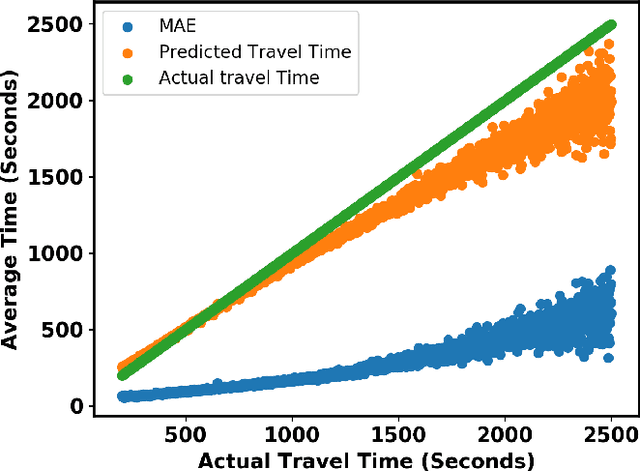
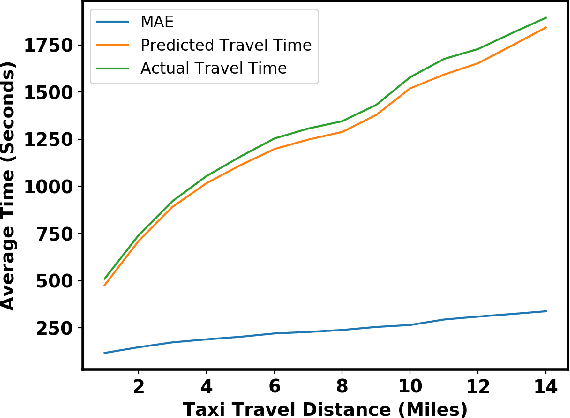
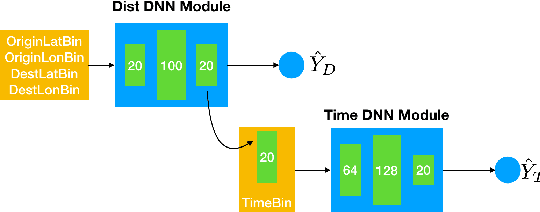
In building intelligent transportation systems such as taxi or rideshare services, accurate prediction of travel time and distance is crucial for customer experience and resource management. Using the NYC taxi dataset, which contains taxi trips data collected from GPS-enabled taxis [23], this paper investigates the use of deep neural networks to jointly predict taxi trip time and distance. We propose a model, called ST-NN (Spatio-Temporal Neural Network), which first predicts the travel distance between an origin and a destination GPS coordinate, then combines this prediction with the time of day to predict the travel time. The beauty of ST-NN is that it uses only the raw trips data without requiring further feature engineering and provides a joint estimate of travel time and distance. We compare the performance of ST-NN to that of state-of-the-art travel time estimation methods, and we observe that the proposed approach generalizes better than state-of-the-art methods. We show that ST-NN approach significantly reduces the mean absolute error for both predicted travel time and distance, about 17% for travel time prediction. We also observe that the proposed approach is more robust to outliers present in the dataset by testing the performance of ST-NN on the datasets with and without outliers.
Learning Deep Networks from Noisy Labels with Dropout Regularization
May 09, 2017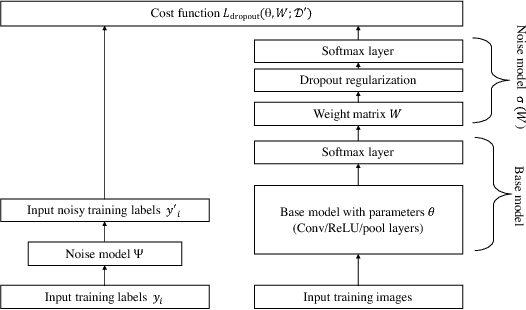


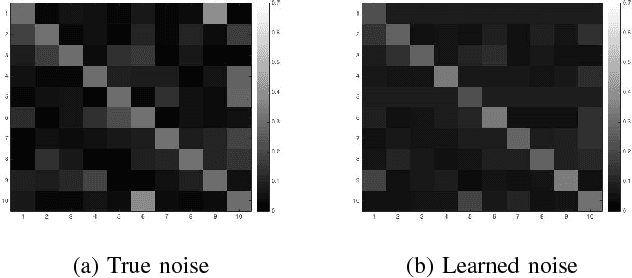
Large datasets often have unreliable labels-such as those obtained from Amazon's Mechanical Turk or social media platforms-and classifiers trained on mislabeled datasets often exhibit poor performance. We present a simple, effective technique for accounting for label noise when training deep neural networks. We augment a standard deep network with a softmax layer that models the label noise statistics. Then, we train the deep network and noise model jointly via end-to-end stochastic gradient descent on the (perhaps mislabeled) dataset. The augmented model is overdetermined, so in order to encourage the learning of a non-trivial noise model, we apply dropout regularization to the weights of the noise model during training. Numerical experiments on noisy versions of the CIFAR-10 and MNIST datasets show that the proposed dropout technique outperforms state-of-the-art methods.
Effective Object Tracking in Unstructured Crowd Scenes
Oct 02, 2015
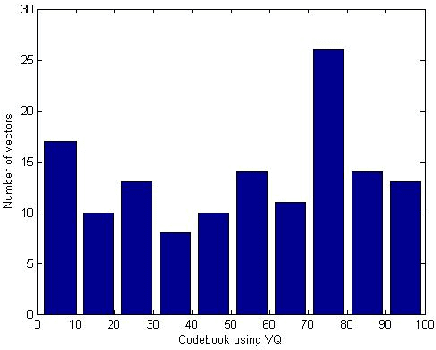


In this paper, we are presenting a rotation variant Oriented Texture Curve (OTC) descriptor based mean shift algorithm for tracking an object in an unstructured crowd scene. The proposed algorithm works by first obtaining the OTC features for a manually selected object target, then a visual vocabulary is created by using all the OTC features of the target. The target histogram is obtained using codebook encoding method which is then used in mean shift framework to perform similarity search. Results are obtained on different videos of challenging scenes and the comparison of the proposed approach with several state-of-the-art approaches are provided. The analysis shows the advantages and limitations of the proposed approach for tracking an object in unstructured crowd scenes.
SA-CNN: Dynamic Scene Classification using Convolutional Neural Networks
Aug 29, 2015
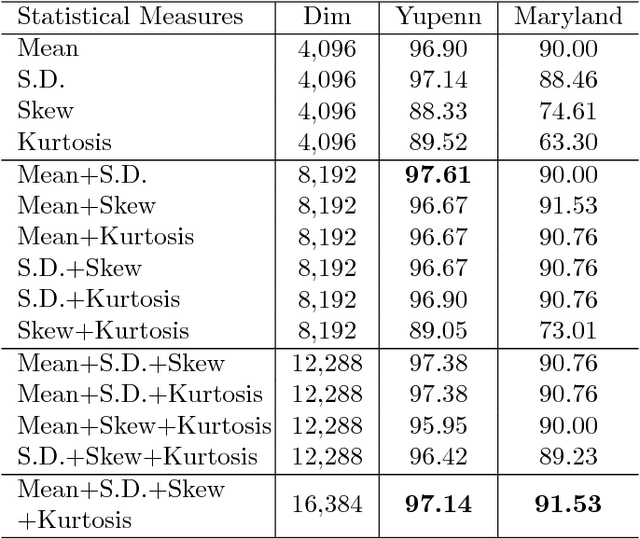
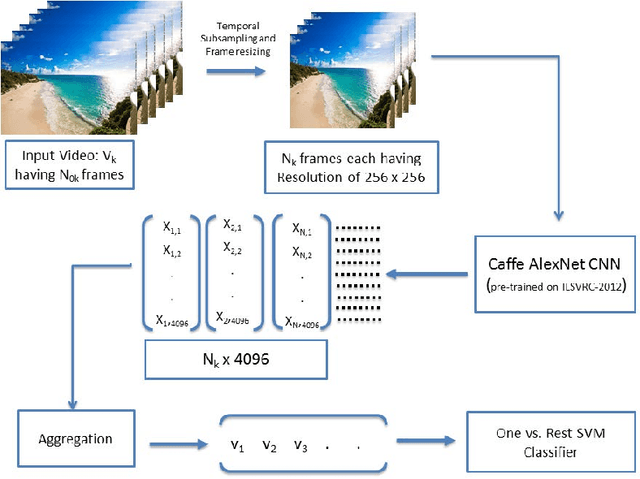
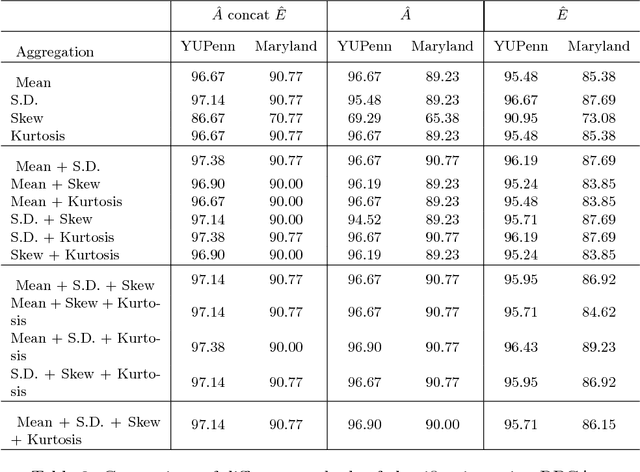
The task of classifying videos of natural dynamic scenes into appropriate classes has gained lot of attention in recent years. The problem especially becomes challenging when the camera used to capture the video is dynamic. In this paper, we analyse the performance of statistical aggregation (SA) techniques on various pre-trained convolutional neural network(CNN) models to address this problem. The proposed approach works by extracting CNN activation features for a number of frames in a video and then uses an aggregation scheme in order to obtain a robust feature descriptor for the video. We show through results that the proposed approach performs better than the-state-of-the arts for the Maryland and YUPenn dataset. The final descriptor obtained is powerful enough to distinguish among dynamic scenes and is even capable of addressing the scenario where the camera motion is dominant and the scene dynamics are complex. Further, this paper shows an extensive study on the performance of various aggregation methods and their combinations. We compare the proposed approach with other dynamic scene classification algorithms on two publicly available datasets - Maryland and YUPenn to demonstrate the superior performance of the proposed approach.