 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomically constrained CT image translation for heterogeneous blood vessel segmentation
Oct 04, 2022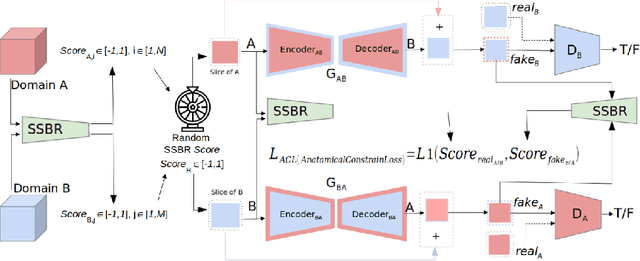
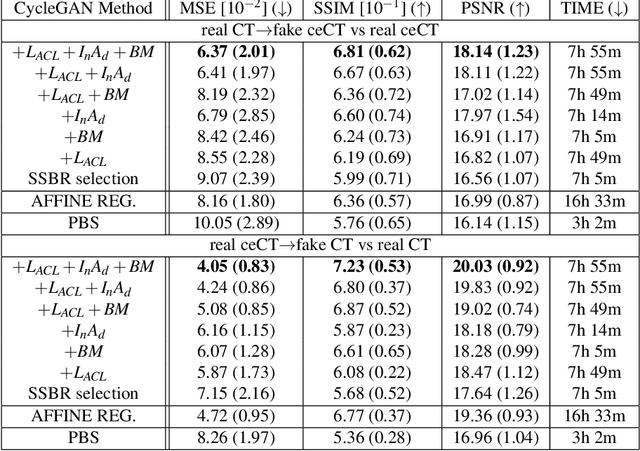
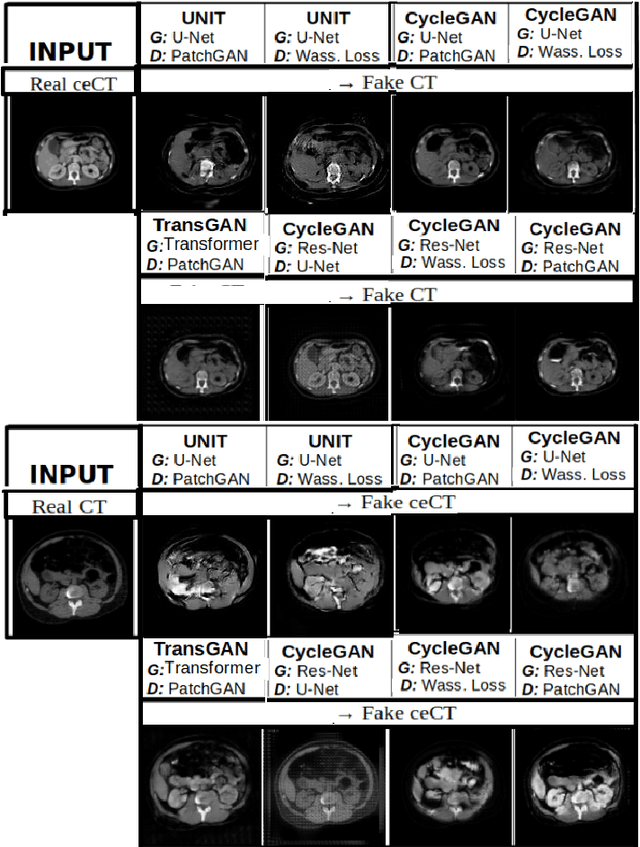
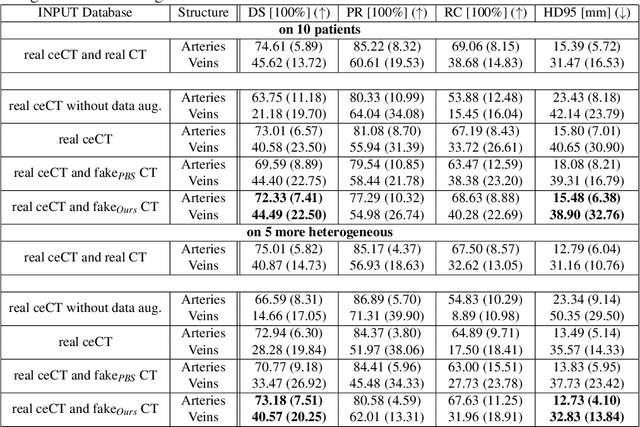
Anatomical structures such as blood vessels in contrast-enhanced CT (ceCT) images can be challenging to segment due to the variability in contrast medium diffusion. The combined use of ceCT and contrast-free (CT) CT images can improve the segmentation performances, but at the cost of a double radiation exposure. To limit the radiation dose, generative models could be used to synthesize one modality, instead of acquiring it. The CycleGAN approach has recently attracted particular attention because it alleviates the need for paired data that are difficult to obtain. Despite the great performances demonstrated in the literature, limitations still remain when dealing with 3D volumes generated slice by slice from unpaired datasets with different fields of view. We present an extension of CycleGAN to generate high fidelity images, with good structural consistency, in this context. We leverage anatomical constraints and automatic region of interest selection by adapting the Self-Supervised Body Regressor. These constraints enforce anatomical consistency and allow feeding anatomically-paired input images to the algorithm. Results show qualitative and quantitative improvements, compared to stateof-the-art methods, on the translation task between ceCT and CT images (and vice versa).
Morphological adjunctions represented by matrices in max-plus algebra for signal and image processing
Jul 28, 2022In discrete signal and image processing, many dilations and erosions can be written as the max-plus and min-plus product of a matrix on a vector. Previous studies considered operators on symmetrical, unbounded complete lattices, such as Cartesian powers of the completed real line. This paper focuses on adjunctions on closed hypercubes, which are the complete lattices used in practice to represent digital signals and images. We show that this constrains the representing matrices to be doubly-0-astic and we characterise the adjunctions that can be represented by them. A graph interpretation of the defined operators naturally arises from the adjacency relationship encoded by the matrices, as well as a max-plus spectral interpretation.
Optimizing transformations for contrastive learning in a differentiable framework
Jul 27, 2022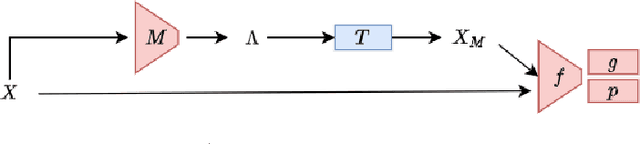
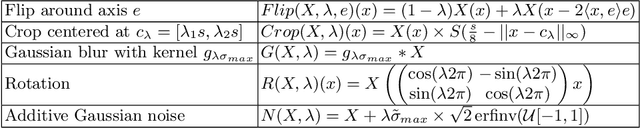

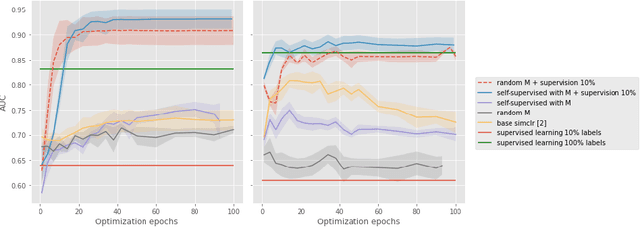
Current contrastive learning methods use random transformations sampled from a large list of transformations, with fixed hyperparameters, to learn invariance from an unannotated database. Following previous works that introduce a small amount of supervision, we propose a framework to find optimal transformations for contrastive learning using a differentiable transformation network. Our method increases performances at low annotated data regime both in supervision accuracy and in convergence speed. In contrast to previous work, no generative model is needed for transformation optimization. Transformed images keep relevant information to solve the supervised task, here classification. Experiments were performed on 34000 2D slices of brain Magnetic Resonance Images and 11200 chest X-ray images. On both datasets, with 10% of labeled data, our model achieves better performances than a fully supervised model with 100% labels.
Is the U-Net Directional-Relationship Aware?
Jul 06, 2022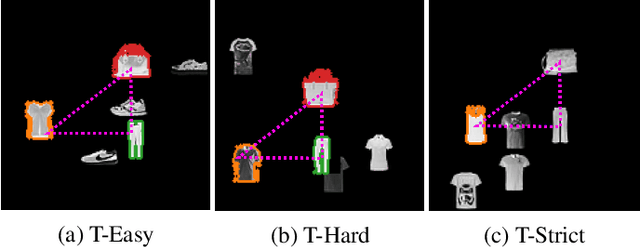
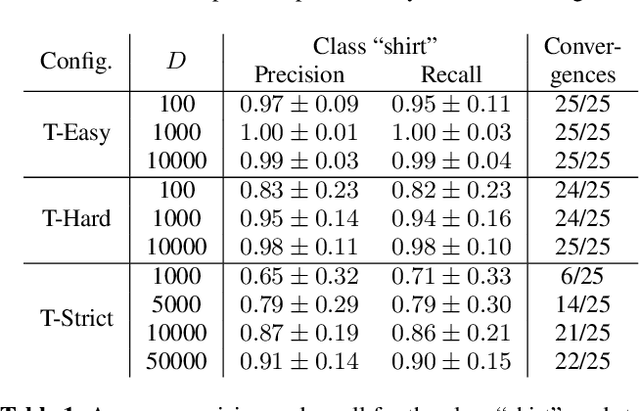

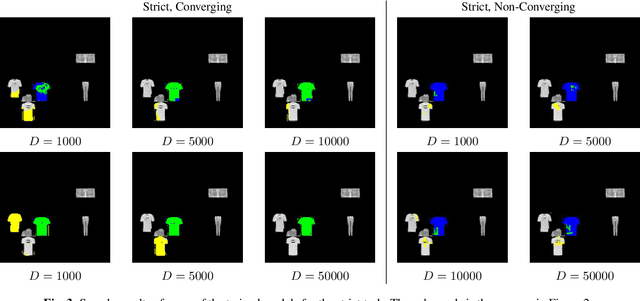
CNNs are often assumed to be capable of using contextual information about distinct objects (such as their directional relations) inside their receptive field. However, the nature and limits of this capacity has never been explored in full. We explore a specific type of relationship~-- directional~-- using a standard U-Net trained to optimize a cross-entropy loss function for segmentation. We train this network on a pretext segmentation task requiring directional relation reasoning for success and state that, with enough data and a sufficiently large receptive field, it succeeds to learn the proposed task. We further explore what the network has learned by analysing scenarios where the directional relationships are perturbed, and show that the network has learned to reason using these relationships.
Real-time Virtual-Try-On from a Single Example Image through Deep Inverse Graphics and Learned Differentiable Renderers
May 12, 2022

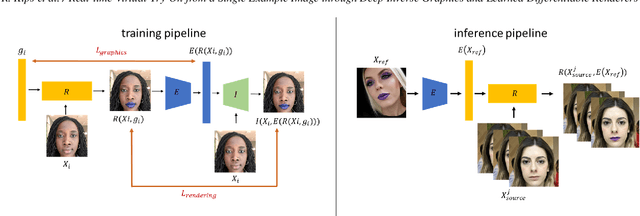

Augmented reality applications have rapidly spread across online platforms, allowing consumers to virtually try-on a variety of products, such as makeup, hair dying, or shoes. However, parametrizing a renderer to synthesize realistic images of a given product remains a challenging task that requires expert knowledge. While recent work has introduced neural rendering methods for virtual try-on from example images, current approaches are based on large generative models that cannot be used in real-time on mobile devices. This calls for a hybrid method that combines the advantages of computer graphics and neural rendering approaches. In this paper we propose a novel framework based on deep learning to build a real-time inverse graphics encoder that learns to map a single example image into the parameter space of a given augmented reality rendering engine. Our method leverages self-supervised learning and does not require labeled training data which makes it extendable to many virtual try-on applications. Furthermore, most augmented reality renderers are not differentiable in practice due to algorithmic choices or implementation constraints to reach real-time on portable devices. To relax the need for a graphics-based differentiable renderer in inverse graphics problems, we introduce a trainable imitator module. Our imitator is a generative network that learns to accurately reproduce the behavior of a given non-differentiable renderer. We propose a novel rendering sensitivity loss to train the imitator, which ensures that the network learns an accurate and continuous representation for each rendering parameter. Our framework enables novel applications where consumers can virtually try-on a novel unknown product from an inspirational reference image on social media. It can also be used by graphics artists to automatically create realistic rendering from a reference product image.
Hair Color Digitization through Imaging and Deep Inverse Graphics
Feb 08, 2022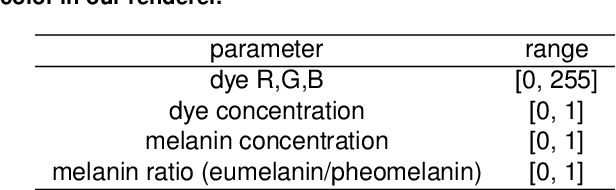


Hair appearance is a complex phenomenon due to hair geometry and how the light bounces on different hair fibers. For this reason, reproducing a specific hair color in a rendering environment is a challenging task that requires manual work and expert knowledge in computer graphics to tune the result visually. While current hair capture methods focus on hair shape estimation many applications could benefit from an automated method for capturing the appearance of a physical hair sample, from augmented/virtual reality to hair dying development. Building on recent advances in inverse graphics and material capture using deep neural networks, we introduce a novel method for hair color digitization. Our proposed pipeline allows capturing the color appearance of a physical hair sample and renders synthetic images of hair with a similar appearance, simulating different hair styles and/or lighting environments. Since rendering realistic hair images requires path-tracing rendering, the conventional inverse graphics approach based on differentiable rendering is untractable. Our method is based on the combination of a controlled imaging device, a path-tracing renderer, and an inverse graphics model based on self-supervised machine learning, which does not require to use differentiable rendering to be trained. We illustrate the performance of our hair digitization method on both real and synthetic images and show that our approach can accurately capture and render hair color.
A deep residual learning implementation of Metamorphosis
Feb 01, 2022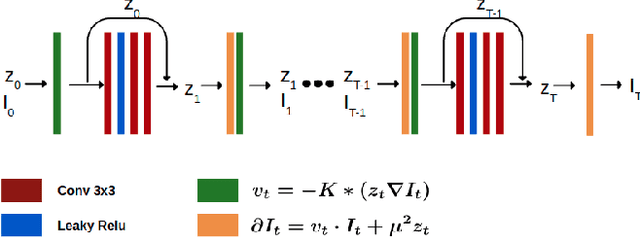
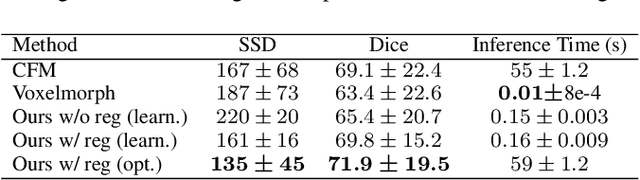
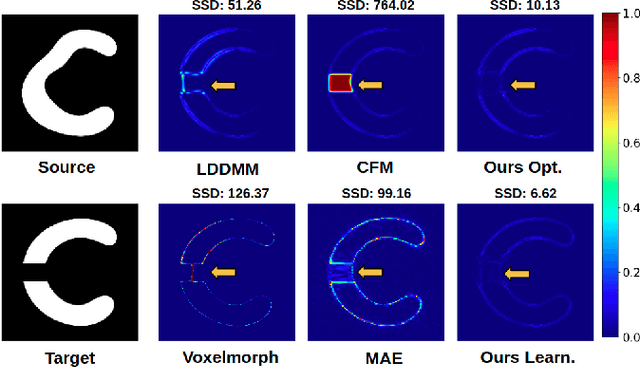
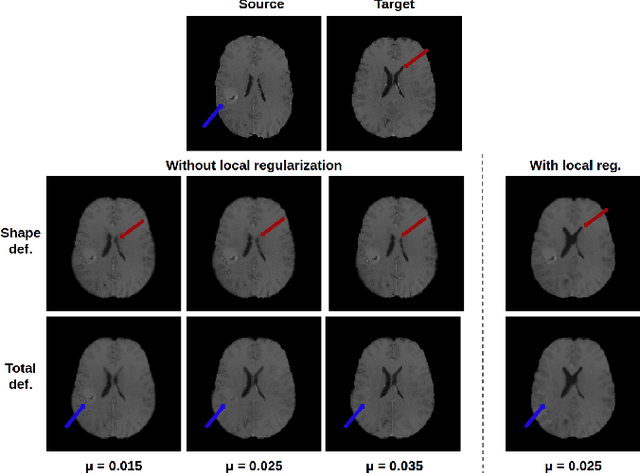
In medical imaging, most of the image registration methods implicitly assume a one-to-one correspondence between the source and target images (i.e., diffeomorphism). However, this is not necessarily the case when dealing with pathological medical images (e.g., presence of a tumor, lesion, etc.). To cope with this issue, the Metamorphosis model has been proposed. It modifies both the shape and the appearance of an image to deal with the geometrical and topological differences. However, the high computational time and load have hampered its applications so far. Here, we propose a deep residual learning implementation of Metamorphosis that drastically reduces the computational time at inference. Furthermore, we also show that the proposed framework can easily integrate prior knowledge of the localization of topological changes (e.g., segmentation masks) that can act as spatial regularization to correctly disentangle appearance and shape changes. We test our method on the BraTS 2021 dataset, showing that it outperforms current state-of-the-art methods in the alignment of images with brain tumors.
Automatic size and pose homogenization with spatial transformer network to improve and accelerate pediatric segmentation
Jul 06, 2021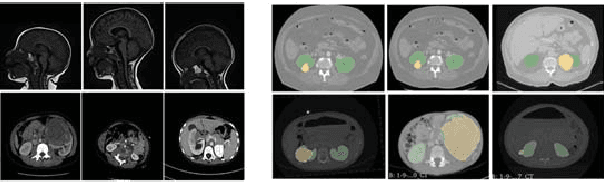


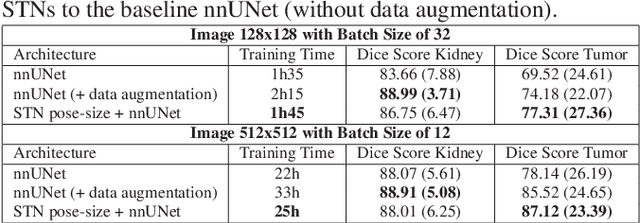
Due to a high heterogeneity in pose and size and to a limited number of available data, segmentation of pediatric images is challenging for deep learning methods. In this work, we propose a new CNN architecture that is pose and scale invariant thanks to the use of Spatial Transformer Network (STN). Our architecture is composed of three sequential modules that are estimated together during training: (i) a regression module to estimate a similarity matrix to normalize the input image to a reference one; (ii) a differentiable module to find the region of interest to segment; (iii) a segmentation module, based on the popular UNet architecture, to delineate the object. Unlike the original UNet, which strives to learn a complex mapping, including pose and scale variations, from a finite training dataset, our segmentation module learns a simpler mapping focusing on images with normalized pose and size. Furthermore, the use of an automatic bounding box detection through STN allows saving time and especially memory, while keeping similar performance. We test the proposed method in kidney and renal tumor segmentation on abdominal pediatric CT scanners. Results indicate that the estimated STN homogenization of size and pose accelerates the segmentation (25h), compared to standard data-augmentation (33h), while obtaining a similar quality for the kidney (88.01\% of Dice score) and improving the renal tumor delineation (from 85.52\% to 87.12\%).
* ISBI 2021
Template-Based Graph Clustering
Jul 05, 2021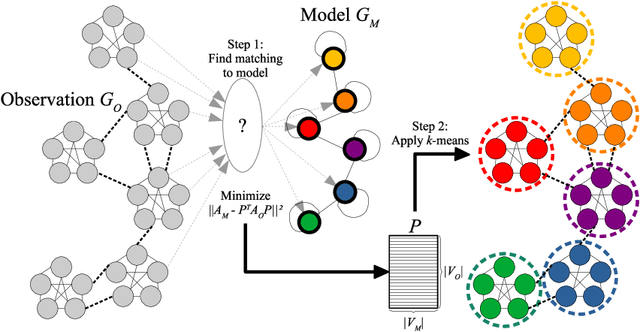
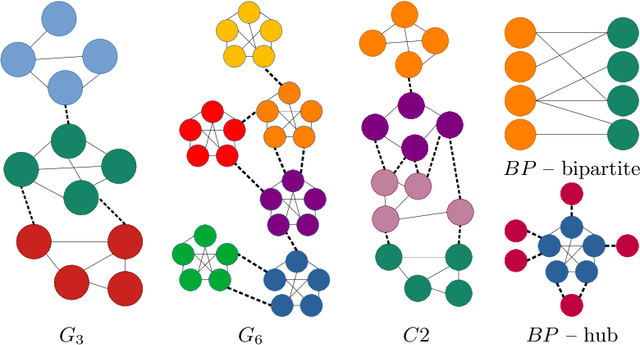
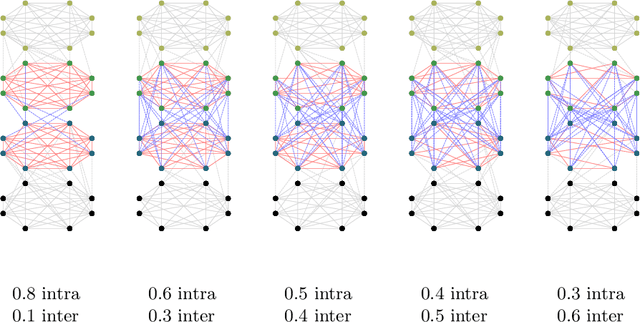
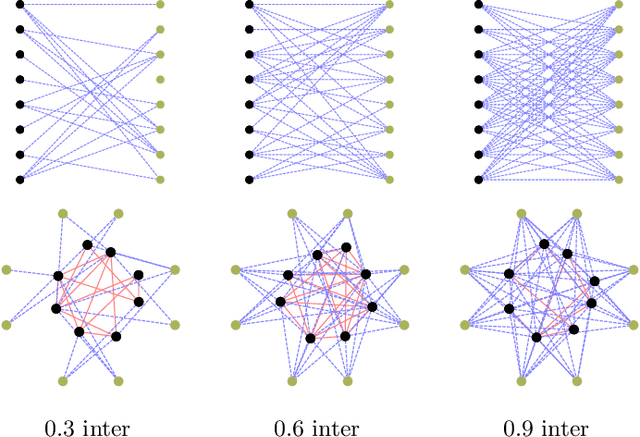
We propose a novel graph clustering method guided by additional information on the underlying structure of the clusters (or communities). The problem is formulated as the matching of a graph to a template with smaller dimension, hence matching $n$ vertices of the observed graph (to be clustered) to the $k$ vertices of a template graph, using its edges as support information, and relaxed on the set of orthonormal matrices in order to find a $k$ dimensional embedding. With relevant priors that encode the density of the clusters and their relationships, our method outperforms classical methods, especially for challenging cases.
* ECML-PKDD, Workshop on Graph Embedding and Minin (GEM) 2020
Knowledge distillation from multi-modal to mono-modal segmentation networks
Jun 17, 2021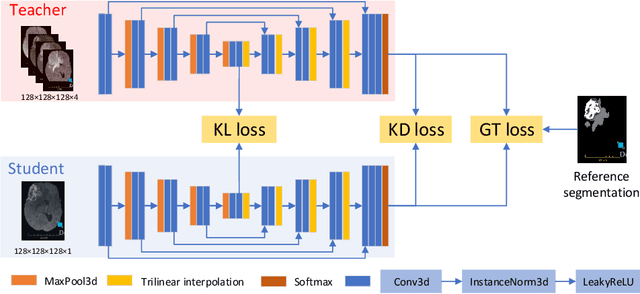
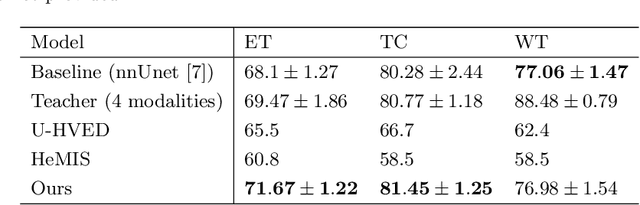
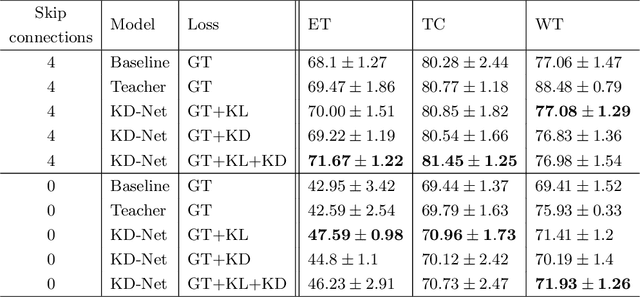
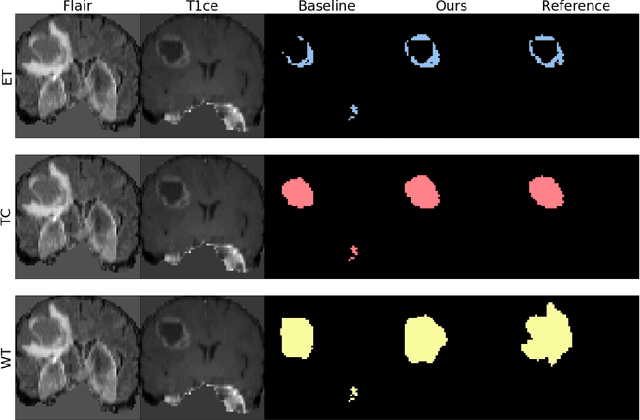
The joint use of multiple imaging modalities for medical image segmentation has been widely studied in recent years. The fusion of information from different modalities has demonstrated to improve the segmentation accuracy, with respect to mono-modal segmentations, in several applications. However, acquiring multiple modalities is usually not possible in a clinical setting due to a limited number of physicians and scanners, and to limit costs and scan time. Most of the time, only one modality is acquired. In this paper, we propose KD-Net, a framework to transfer knowledge from a trained multi-modal network (teacher) to a mono-modal one (student). The proposed method is an adaptation of the generalized distillation framework where the student network is trained on a subset (1 modality) of the teacher's inputs (n modalities). We illustrate the effectiveness of the proposed framework in brain tumor segmentation with the BraTS 2018 dataset. Using different architectures, we show that the student network effectively learns from the teacher and always outperforms the baseline mono-modal network in terms of segmentation accuracy.
* MICCAI 2020