 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning how to Share Credit among Macro-Actions
Jun 16, 2025One proposed mechanism to improve exploration in reinforcement learning is through the use of macro-actions. Paradoxically though, in many scenarios the naive addition of macro-actions does not lead to better exploration, but rather the opposite. It has been argued that this was caused by adding non-useful macros and multiple works have focused on mechanisms to discover effectively environment-specific useful macros. In this work, we take a slightly different perspective. We argue that the difficulty stems from the trade-offs between reducing the average number of decisions per episode versus increasing the size of the action space. Namely, one typically treats each potential macro-action as independent and atomic, hence strictly increasing the search space and making typical exploration strategies inefficient. To address this problem we propose a novel regularization term that exploits the relationship between actions and macro-actions to improve the credit assignment mechanism by reducing the effective dimension of the action space and, therefore, improving exploration. The term relies on a similarity matrix that is meta-learned jointly with learning the desired policy. We empirically validate our strategy looking at macro-actions in Atari games, and the StreetFighter II environment. Our results show significant improvements over the Rainbow-DQN baseline in all environments. Additionally, we show that the macro-action similarity is transferable to related environments. We believe this work is a small but important step towards understanding how the similarity-imposed geometry on the action space can be exploited to improve credit assignment and exploration, therefore making learning more effective.
Playing Atari Games with Deep Reinforcement Learning and Human Checkpoint Replay
Jul 18, 2016

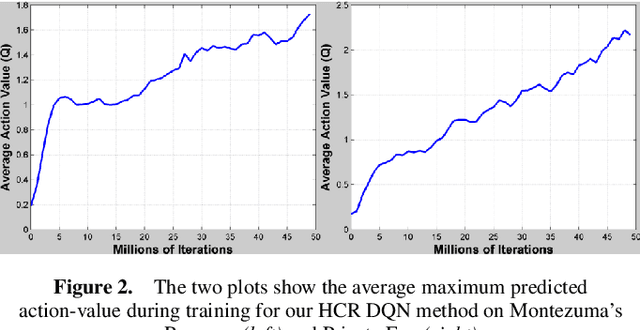
This paper introduces a novel method for learning how to play the most difficult Atari 2600 games from the Arcade Learning Environment using deep reinforcement learning. The proposed method, human checkpoint replay, consists in using checkpoints sampled from human gameplay as starting points for the learning process. This is meant to compensate for the difficulties of current exploration strategies, such as epsilon-greedy, to find successful control policies in games with sparse rewards. Like other deep reinforcement learning architectures, our model uses a convolutional neural network that receives only raw pixel inputs to estimate the state value function. We tested our method on Montezuma's Revenge and Private Eye, two of the most challenging games from the Atari platform. The results we obtained show a substantial improvement compared to previous learning approaches, as well as over a random player. We also propose a method for training deep reinforcement learning agents using human gameplay experience, which we call human experience replay.