 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEMESIS: Noise-suppressed Efficient MAE with Enhanced Superpatch Integration Strategy
Apr 02, 2026Volumetric CT imaging is essential for clinical diagnosis, yet annotating 3D volumes is expensive and time-consuming, motivating self-supervised learning (SSL) from unlabeled data. However, applying SSL to 3D CT remains challenging due to the high memory cost of full-volume transformers and the anisotropic spatial structure of CT data, which is not well captured by conventional masking strategies. We propose NEMESIS, a masked autoencoder (MAE) framework that operates on local 128x128x128 superpatches, enabling memory-efficient training while preserving anatomical detail. NEMESIS introduces three key components: (i) noise-enhanced reconstruction as a pretext task, (ii) Masked Anatomical Transformer Blocks (MATB) that perform dual-masking through parallel plane-wise and axis-wise token removal, and (iii) NEMESIS Tokens (NT) for cross-scale context aggregation. On the BTCV multi-organ classification benchmark, NEMESIS with a frozen backbone and a linear classifier achieves a mean AUROC of 0.9633, surpassing fully fine-tuned SuPreM (0.9493) and VoCo (0.9387). Under a low-label regime with only 10% of available annotations, it retains an AUROC of 0.9075, demonstrating strong label efficiency. Furthermore, the superpatch-based design reduces computational cost to 31.0 GFLOPs per forward pass, compared to 985.8 GFLOPs for the full-volume baseline, providing a scalable and robust foundation for 3D medical imaging.
Co-salient Object Detection Based on Deep Saliency Networks and Seed Propagation over an Integrated Graph
Jun 29, 2017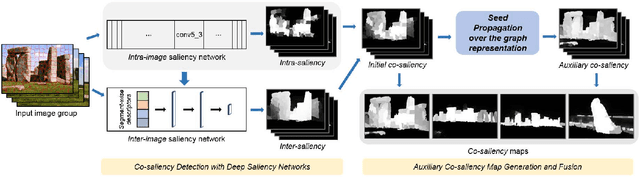



This paper presents a co-salient object detection method to find common salient regions in a set of images. We utilize deep saliency networks to transfer co-saliency prior knowledge and better capture high-level semantic information, and the resulting initial co-saliency maps are enhanced by seed propagation steps over an integrated graph. The deep saliency networks are trained in a supervised manner to avoid online weakly supervised learning and exploit them not only to extract high-level features but also to produce both intra- and inter-image saliency maps. Through a refinement step, the initial co-saliency maps can uniformly highlight co-salient regions and locate accurate object boundaries. To handle input image groups inconsistent in size, we propose to pool multi-regional descriptors including both within-segment and within-group information. In addition, the integrated multilayer graph is constructed to find the regions that the previous steps may not detect by seed propagation with low-level descriptors. In this work, we utilize the useful complementary components of high-, low-level information, and several learning-based steps. Our experiments have demonstrated that the proposed approach outperforms comparable co-saliency detection methods on widely used public databases and can also be directly applied to co-segmentation tasks.
A New Convolutional Network-in-Network Structure and Its Applications in Skin Detection, Semantic Segmentation, and Artifact Reduction
Jan 22, 2017
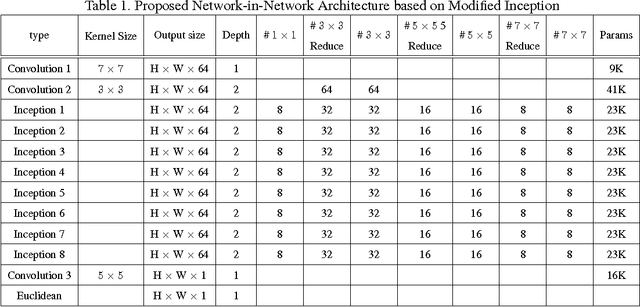
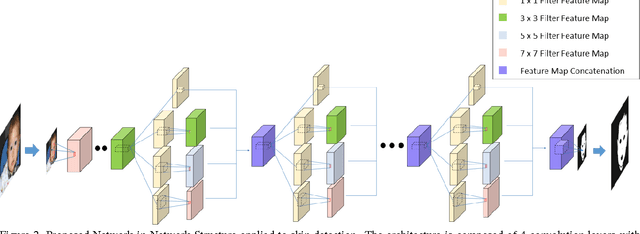
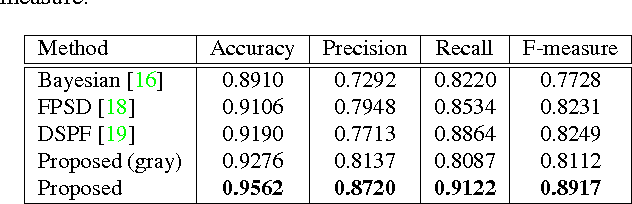
The inception network has been shown to provide good performance on image classification problems, but there are not much evidences that it is also effective for the image restoration or pixel-wise labeling problems. For image restoration problems, the pooling is generally not used because the decimated features are not helpful for the reconstruction of an image as the output. Moreover, most deep learning architectures for the restoration problems do not use dense prediction that need lots of training parameters. From these observations, for enjoying the performance of inception-like structure on the image based problems we propose a new convolutional network-in-network structure. The proposed network can be considered a modification of inception structure where pool projection and pooling layer are removed for maintaining the entire feature map size, and a larger kernel filter is added instead. Proposed network greatly reduces the number of parameters on account of removed dense prediction and pooling, which is an advantage, but may also reduce the receptive field in each layer. Hence, we add a larger kernel than the original inception structure for not increasing the depth of layers. The proposed structure is applied to typical image-to-image learning problems, i.e., the problems where the size of input and output are same such as skin detection, semantic segmentation, and compression artifacts reduction. Extensive experiments show that the proposed network brings comparable or better results than the state-of-the-art convolutional neural networks for these problems.