 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Evaluation of Supervision Signals for Style Transfer Models
Jan 15, 2021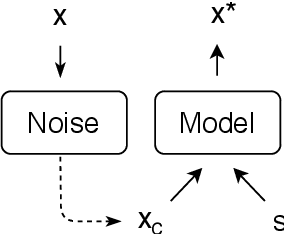
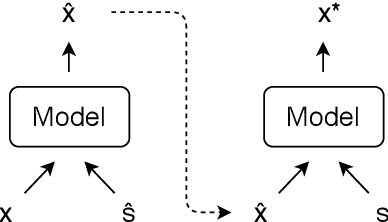
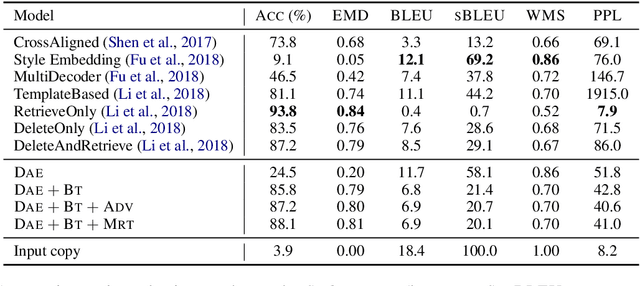
Text style transfer has gained increasing attention from the research community over the recent years. However, the proposed approaches vary in many ways, which makes it hard to assess the individual contribution of the model components. In style transfer, the most important component is the optimization technique used to guide the learning in the absence of parallel training data. In this work we empirically compare the dominant optimization paradigms which provide supervision signals during training: backtranslation, adversarial training and reinforcement learning. We find that backtranslation has model-specific limitations, which inhibits training style transfer models. Reinforcement learning shows the best performance gains, while adversarial training, despite its popularity, does not offer an advantage over the latter alternative. In this work we also experiment with Minimum Risk Training, a popular technique in the machine translation community, which, to our knowledge, has not been empirically evaluated in the task of style transfer. We fill this research gap and empirically show its efficacy.
A Framework for Learning Invariant Physical Relations in Multimodal Sensory Processing
Jun 30, 2020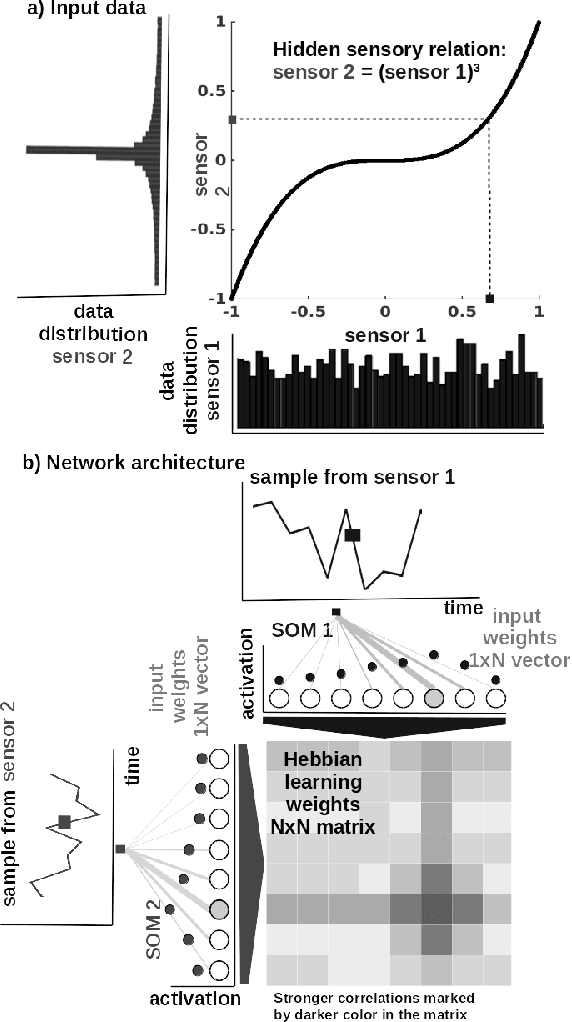
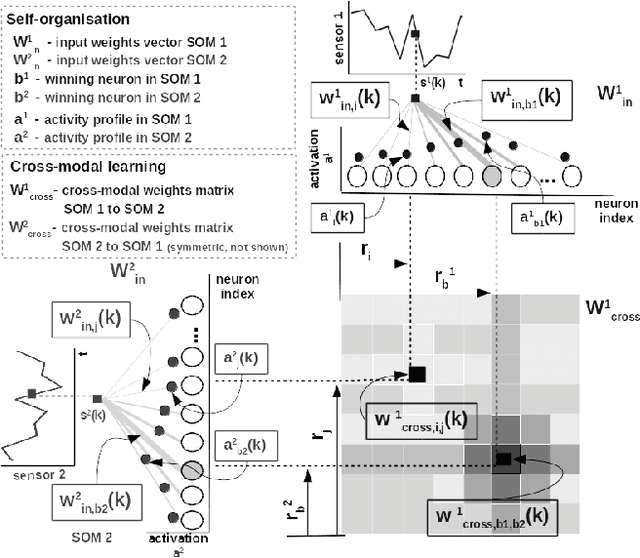
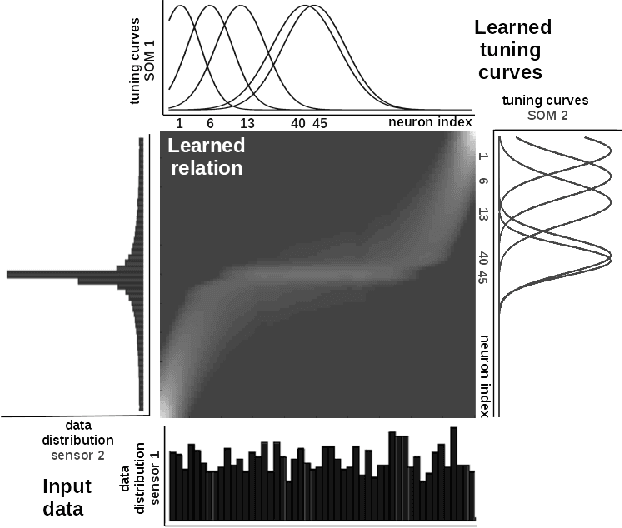
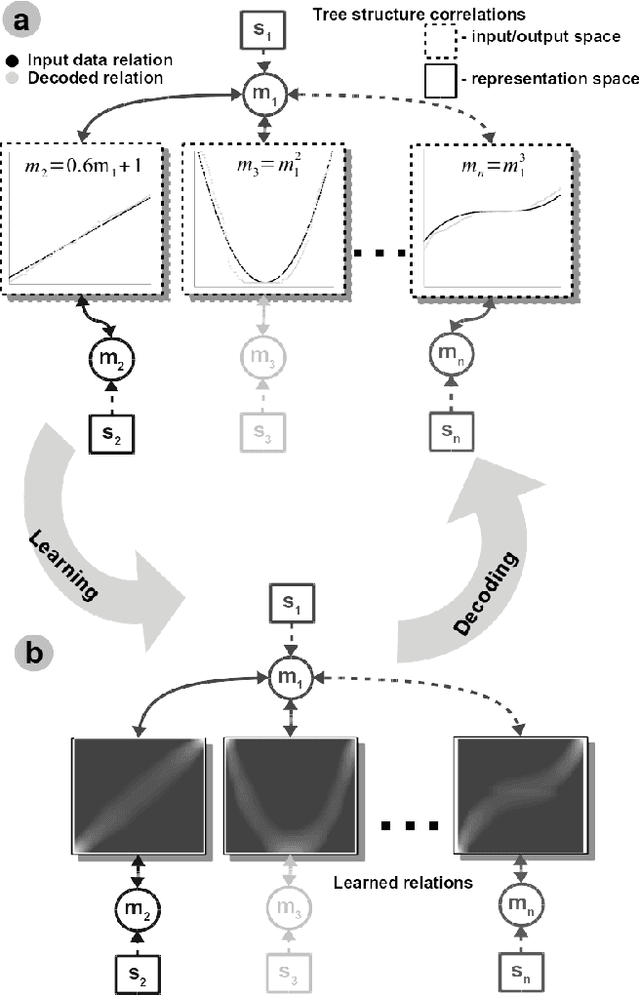
Perceptual learning enables humans to recognize and represent stimuli invariant to various transformations and build a consistent representation of the self and physical world. Such representations preserve the invariant physical relations among the multiple perceived sensory cues. This work is an attempt to exploit these principles in an engineered system. We design a novel neural network architecture capable of learning, in an unsupervised manner, relations among multiple sensory cues. The system combines computational principles, such as competition, cooperation, and correlation, in a neurally plausible computational substrate. It achieves that through a parallel and distributed processing architecture in which the relations among the multiple sensory quantities are extracted from time-sequenced data. We describe the core system functionality when learning arbitrary non-linear relations in low-dimensional sensory data. Here, an initial benefit rises from the fact that such a network can be engineered in a relatively straightforward way without prior information about the sensors and their interactions. Moreover, alleviating the need for tedious modelling and parametrization, the network converges to a consistent description of any arbitrary high-dimensional multisensory setup. We demonstrate this through a real-world learning problem, where, from standard RGB camera frames, the network learns the relations between physical quantities such as light intensity, spatial gradient, and optical flow, describing a visual scene. Overall, the benefits of such a framework lie in the capability to learn non-linear pairwise relations among sensory streams in an architecture that is stable under noise and missing sensor input.