 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-AF 13: An Interpretable Atrial Fibrillation Risk Score Mined from Discharge Reports
Jun 09, 2026Background. Atrial fibrillation (AF) is the most prevalent cardiac arrhythmia and a major determinant of prognosis. Established AF risk scores rely on factors (older age, hypertension) nearly ubiquitous among patients with cardiovascular disease (CVD), offering limited stratification in this high-risk group. Most target long-term (5-10 year) rather than medium-term prediction. We developed interpretable ML models predicting AF risk over a 24-month and entire follow-up horizon in CVD patients using routinely collected hospital data. Methods. Single-center retrospective study of electronic health records from the National Research Cardiology Center (Russia) for patients aged >=18 with CVD but without pre-existing AF, hospitalized more than once between January 2012 and May 2019. A custom NLP pipeline transformed unstructured discharge reports into 73 structured features, combining a rule-based parser with transformer-based NER. Using LightAutoML we built a full model (73 features), a simple model (reduced subset), and a linear model for a bedside risk score. Performance was assessed by ROC AUC, compared with CHARGE-AF, C2HEST, MHS, and HAVOC, and interpreted via SHAP. Results. Of 80,576 records from 45,000 patients, 17,562 met inclusion criteria; 1,438 (8.19%) developed AF. The full model reached ROC AUC 0.735 (24-month) and 0.696 (entire follow-up); the simple model was nearly identical (0.725, 0.696). All non-linear models outperformed the four clinical risk scores (ROC AUC 0.53-0.64). The simple model uses 13 features and is named Pre-AF 13. SHAP identified age and left atrial volume as dominant predictors. A linear risk score (Pre-AF 9) stratified observed 24-month AF incidence from ~7% to 36%. Conclusion. Interpretable ML models built from routinely collected EHR data identify high-AF-risk CVD patients, outperforming established clinical risk scores.
The Limitations of Cross-language Word Embeddings Evaluation
Jun 06, 2018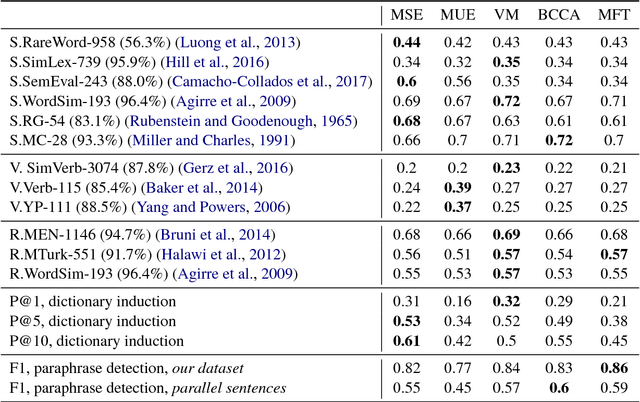

The aim of this work is to explore the possible limitations of existing methods of cross-language word embeddings evaluation, addressing the lack of correlation between intrinsic and extrinsic cross-language evaluation methods. To prove this hypothesis, we construct English-Russian datasets for extrinsic and intrinsic evaluation tasks and compare performances of 5 different cross-language models on them. The results say that the scores even on different intrinsic benchmarks do not correlate to each other. We can conclude that the use of human references as ground truth for cross-language word embeddings is not proper unless one does not understand how do native speakers process semantics in their cognition.