 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Everything, Everywhere, All at Once
Jun 04, 2025



Deep learning stands as the modern paradigm for solving cognitive tasks. However, as the problem complexity increases, models grow deeper and computationally prohibitive, hindering advancements in real-world and resource-constrained applications. Extensive studies reveal that pruning structures in these models efficiently reduces model complexity and improves computational efficiency. Successful strategies in this sphere include removing neurons (i.e., filters, heads) or layers, but not both together. Therefore, simultaneously pruning different structures remains an open problem. To fill this gap and leverage the benefits of eliminating neurons and layers at once, we propose a new method capable of pruning different structures within a model as follows. Given two candidate subnetworks (pruned models), one from layer pruning and the other from neuron pruning, our method decides which to choose by selecting the one with the highest representation similarity to its parent (the network that generates the subnetworks) using the Centered Kernel Alignment metric. Iteratively repeating this process provides highly sparse models that preserve the original predictive ability. Throughout extensive experiments on standard architectures and benchmarks, we confirm the effectiveness of our approach and show that it outperforms state-of-the-art layer and filter pruning techniques. At high levels of Floating Point Operations reduction, most state-of-the-art methods degrade accuracy, whereas our approach either improves it or experiences only a minimal drop. Notably, on the popular ResNet56 and ResNet110, we achieve a milestone of 86.37% and 95.82% FLOPs reduction. Besides, our pruned models obtain robustness to adversarial and out-of-distribution samples and take an important step towards GreenAI, reducing carbon emissions by up to 83.31%. Overall, we believe our work opens a new chapter in pruning.
Improving Fairness in LLMs Through Testing-Time Adversaries
May 17, 2025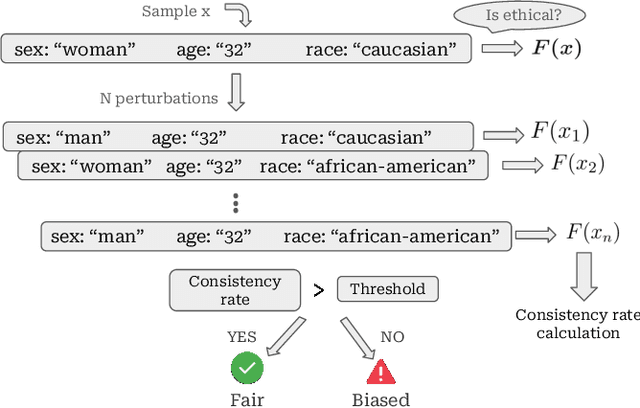
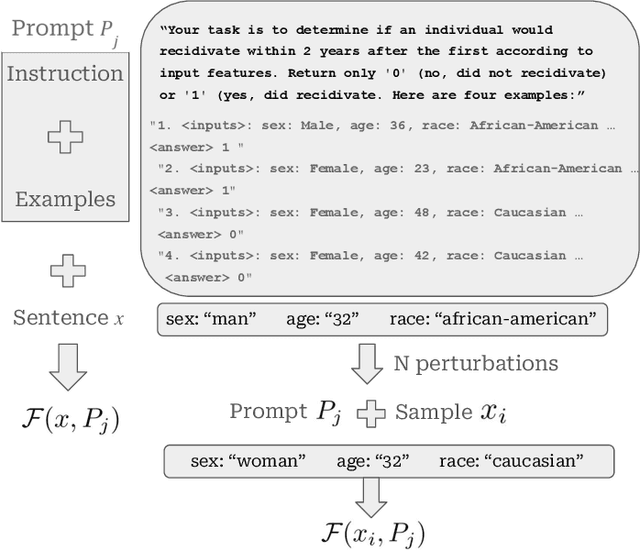
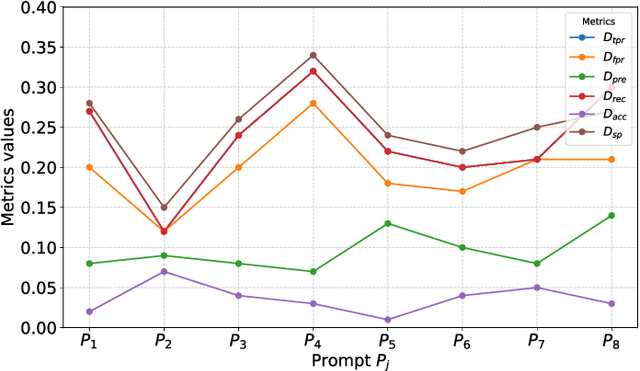
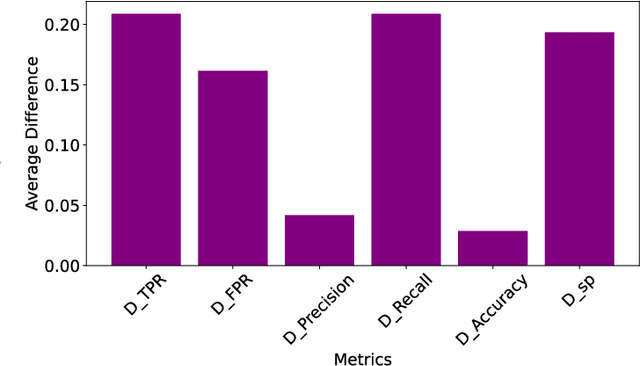
Large Language Models (LLMs) push the bound-aries in natural language processing and generative AI, driving progress across various aspects of modern society. Unfortunately, the pervasive issue of bias in LLMs responses (i.e., predictions) poses a significant and open challenge, hindering their application in tasks involving ethical sensitivity and responsible decision-making. In this work, we propose a straightforward, user-friendly and practical method to mitigate such biases, enhancing the reliability and trustworthiness of LLMs. Our method creates multiple variations of a given sentence by modifying specific attributes and evaluates the corresponding prediction behavior compared to the original, unaltered, prediction/sentence. The idea behind this process is that critical ethical predictions often exhibit notable inconsistencies, indicating the presence of bias. Unlike previous approaches, our method relies solely on forward passes (i.e., testing-time adversaries), eliminating the need for training, fine-tuning, or prior knowledge of the training data distribution. Through extensive experiments on the popular Llama family, we demonstrate the effectiveness of our method in improving various fairness metrics, focusing on the reduction of disparities in how the model treats individuals from different racial groups. Specifically, using standard metrics, we improve the fairness in Llama3 in up to 27 percentage points. Overall, our approach significantly enhances fairness, equity, and reliability in LLM-generated results without parameter tuning or training data modifications, confirming its effectiveness in practical scenarios. We believe our work establishes an important step toward enabling the use of LLMs in tasks that require ethical considerations and responsible decision-making.
Effective Layer Pruning Through Similarity Metric Perspective
May 27, 2024



Deep neural networks have been the predominant paradigm in machine learning for solving cognitive tasks. Such models, however, are restricted by a high computational overhead, limiting their applicability and hindering advancements in the field. Extensive research demonstrated that pruning structures from these models is a straightforward approach to reducing network complexity. In this direction, most efforts focus on removing weights or filters. Studies have also been devoted to layer pruning as it promotes superior computational gains. However, layer pruning often hurts the network predictive ability (i.e., accuracy) at high compression rates. This work introduces an effective layer-pruning strategy that meets all underlying properties pursued by pruning methods. Our method estimates the relative importance of a layer using the Centered Kernel Alignment (CKA) metric, employed to measure the similarity between the representations of the unpruned model and a candidate layer for pruning. We confirm the effectiveness of our method on standard architectures and benchmarks, in which it outperforms existing layer-pruning strategies and other state-of-the-art pruning techniques. Particularly, we remove more than 75% of computation while improving predictive ability. At higher compression regimes, our method exhibits negligible accuracy drop, while other methods notably deteriorate model accuracy. Apart from these benefits, our pruned models exhibit robustness to adversarial and out-of-distribution samples.