 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Lower Bounds for Regret in Reinforcement Learning
Aug 09, 2016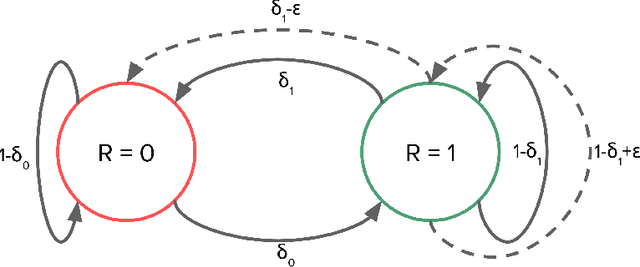
This is a brief technical note to clarify the state of lower bounds on regret for reinforcement learning. In particular, this paper: - Reproduces a lower bound on regret for reinforcement learning, similar to the result of Theorem 5 in the journal UCRL2 paper (Jaksch et al 2010). - Clarifies that the proposed proof of Theorem 6 in the REGAL paper (Bartlett and Tewari 2009) does not hold using the standard techniques without further work. We suggest that this result should instead be considered a conjecture as it has no rigorous proof. - Suggests that the conjectured lower bound given by (Bartlett and Tewari 2009) is incorrect and, in fact, it is possible to improve the scaling of the upper bound to match the weaker lower bounds presented in this paper. We hope that this note serves to clarify existing results in the field of reinforcement learning and provides interesting motivation for future work.
Posterior Sampling for Reinforcement Learning Without Episodes
Aug 09, 2016This is a brief technical note to clarify some of the issues with applying the application of the algorithm posterior sampling for reinforcement learning (PSRL) in environments without fixed episodes. In particular, this paper aims to: - Review some of results which have been proven for finite horizon MDPs (Osband et al 2013, 2014a, 2014b, 2016) and also for MDPs with finite ergodic structure (Gopalan et al 2014). - Review similar results for optimistic algorithms in infinite horizon problems (Jaksch et al 2010, Bartlett and Tewari 2009, Abbasi-Yadkori and Szepesvari 2011), with particular attention to the dynamic episode growth. - Highlight the delicate technical issue which has led to a fault in the proof of the lazy-PSRL algorithm (Abbasi-Yadkori and Szepesvari 2015). We present an explicit counterexample to this style of argument. Therefore, we suggest that the Theorem 2 in (Abbasi-Yadkori and Szepesvari 2015) be instead considered a conjecture, as it has no rigorous proof. - Present pragmatic approaches to apply PSRL in infinite horizon problems. We conjecture that, under some additional assumptions, it will be possible to obtain bounds $O( \sqrt{T} )$ even without episodic reset. We hope that this note serves to clarify existing results in the field of reinforcement learning and provides interesting motivation for future work.
Deep Exploration via Bootstrapped DQN
Jul 04, 2016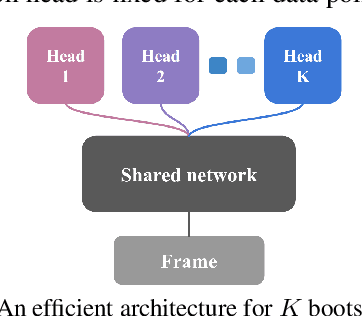
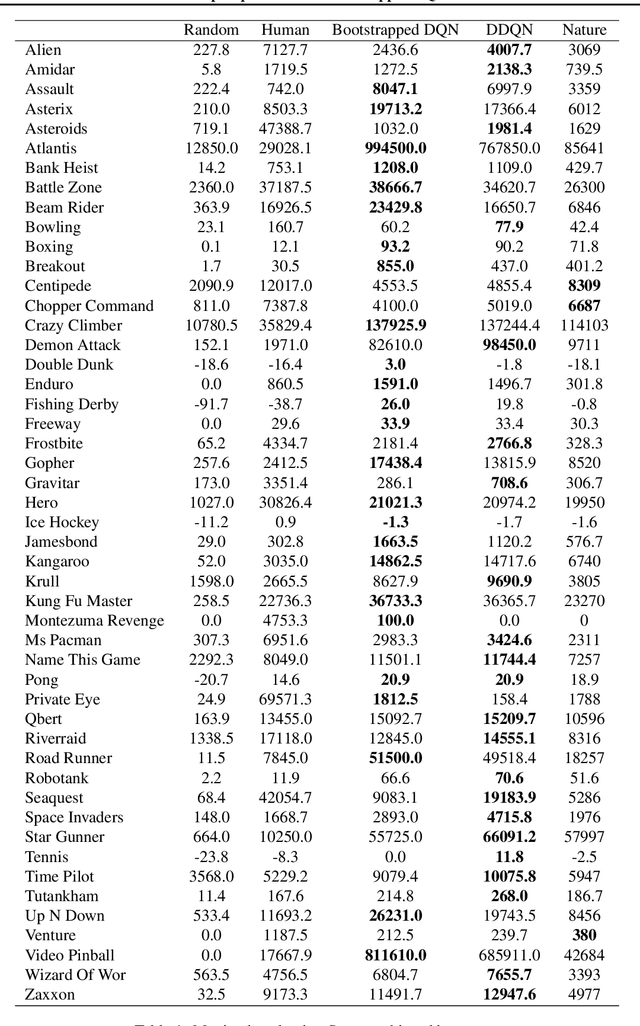
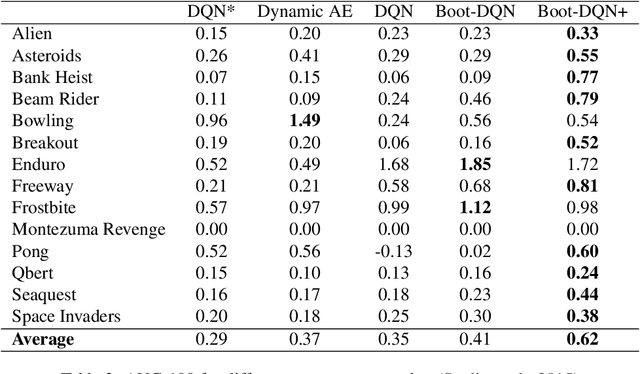
Efficient exploration in complex environments remains a major challenge for reinforcement learning. We propose bootstrapped DQN, a simple algorithm that explores in a computationally and statistically efficient manner through use of randomized value functions. Unlike dithering strategies such as epsilon-greedy exploration, bootstrapped DQN carries out temporally-extended (or deep) exploration; this can lead to exponentially faster learning. We demonstrate these benefits in complex stochastic MDPs and in the large-scale Arcade Learning Environment. Bootstrapped DQN substantially improves learning times and performance across most Atari games.
Generalization and Exploration via Randomized Value Functions
Feb 15, 2016
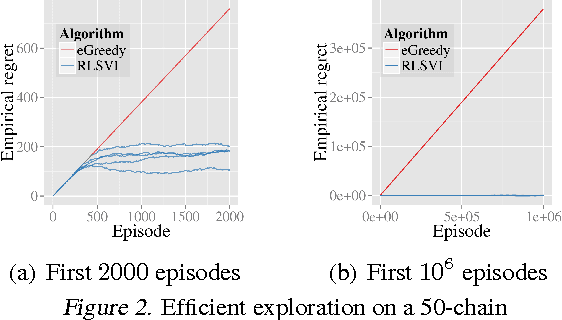
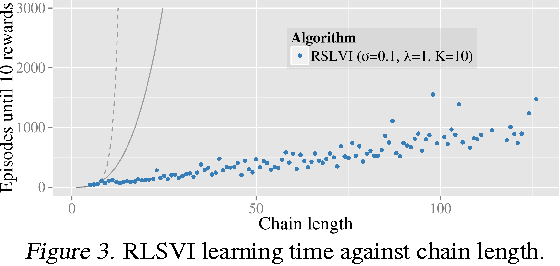
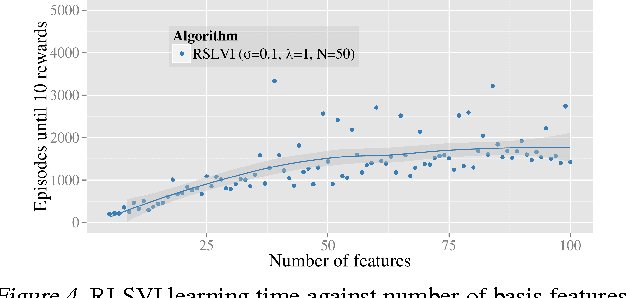
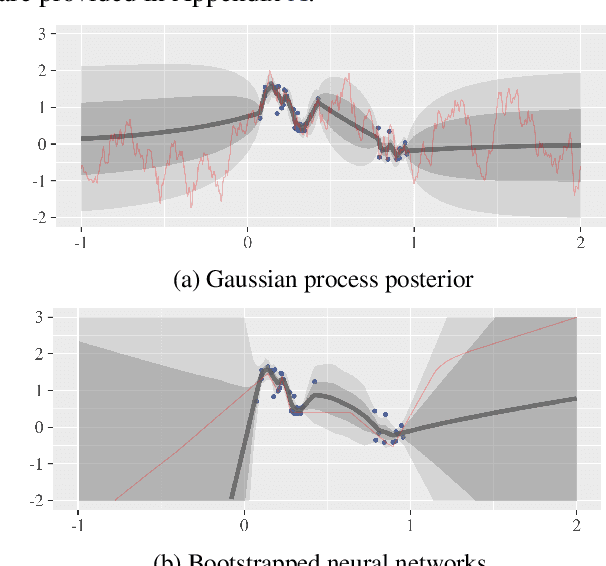
We propose randomized least-squares value iteration (RLSVI) -- a new reinforcement learning algorithm designed to explore and generalize efficiently via linearly parameterized value functions. We explain why versions of least-squares value iteration that use Boltzmann or epsilon-greedy exploration can be highly inefficient, and we present computational results that demonstrate dramatic efficiency gains enjoyed by RLSVI. Further, we establish an upper bound on the expected regret of RLSVI that demonstrates near-optimality in a tabula rasa learning context. More broadly, our results suggest that randomized value functions offer a promising approach to tackling a critical challenge in reinforcement learning: synthesizing efficient exploration and effective generalization.
Bootstrapped Thompson Sampling and Deep Exploration
Jul 01, 2015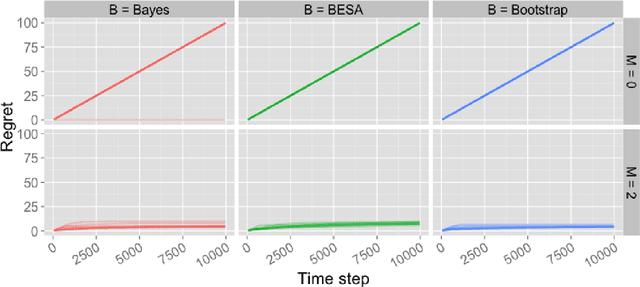
This technical note presents a new approach to carrying out the kind of exploration achieved by Thompson sampling, but without explicitly maintaining or sampling from posterior distributions. The approach is based on a bootstrap technique that uses a combination of observed and artificially generated data. The latter serves to induce a prior distribution which, as we will demonstrate, is critical to effective exploration. We explain how the approach can be applied to multi-armed bandit and reinforcement learning problems and how it relates to Thompson sampling. The approach is particularly well-suited for contexts in which exploration is coupled with deep learning, since in these settings, maintaining or generating samples from a posterior distribution becomes computationally infeasible.
Model-based Reinforcement Learning and the Eluder Dimension
Oct 31, 2014We consider the problem of learning to optimize an unknown Markov decision process (MDP). We show that, if the MDP can be parameterized within some known function class, we can obtain regret bounds that scale with the dimensionality, rather than cardinality, of the system. We characterize this dependence explicitly as $\tilde{O}(\sqrt{d_K d_E T})$ where $T$ is time elapsed, $d_K$ is the Kolmogorov dimension and $d_E$ is the \emph{eluder dimension}. These represent the first unified regret bounds for model-based reinforcement learning and provide state of the art guarantees in several important settings. Moreover, we present a simple and computationally efficient algorithm \emph{posterior sampling for reinforcement learning} (PSRL) that satisfies these bounds.
Near-optimal Reinforcement Learning in Factored MDPs
Oct 31, 2014Any reinforcement learning algorithm that applies to all Markov decision processes (MDPs) will suffer $\Omega(\sqrt{SAT})$ regret on some MDP, where $T$ is the elapsed time and $S$ and $A$ are the cardinalities of the state and action spaces. This implies $T = \Omega(SA)$ time to guarantee a near-optimal policy. In many settings of practical interest, due to the curse of dimensionality, $S$ and $A$ can be so enormous that this learning time is unacceptable. We establish that, if the system is known to be a \emph{factored} MDP, it is possible to achieve regret that scales polynomially in the number of \emph{parameters} encoding the factored MDP, which may be exponentially smaller than $S$ or $A$. We provide two algorithms that satisfy near-optimal regret bounds in this context: posterior sampling reinforcement learning (PSRL) and an upper confidence bound algorithm (UCRL-Factored).
(More) Efficient Reinforcement Learning via Posterior Sampling
Dec 26, 2013

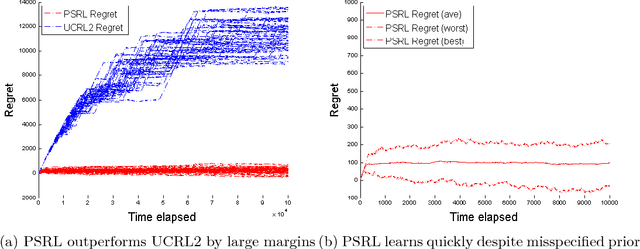
Most provably-efficient learning algorithms introduce optimism about poorly-understood states and actions to encourage exploration. We study an alternative approach for efficient exploration, posterior sampling for reinforcement learning (PSRL). This algorithm proceeds in repeated episodes of known duration. At the start of each episode, PSRL updates a prior distribution over Markov decision processes and takes one sample from this posterior. PSRL then follows the policy that is optimal for this sample during the episode. The algorithm is conceptually simple, computationally efficient and allows an agent to encode prior knowledge in a natural way. We establish an $\tilde{O}(\tau S \sqrt{AT})$ bound on the expected regret, where $T$ is time, $\tau$ is the episode length and $S$ and $A$ are the cardinalities of the state and action spaces. This bound is one of the first for an algorithm not based on optimism, and close to the state of the art for any reinforcement learning algorithm. We show through simulation that PSRL significantly outperforms existing algorithms with similar regret bounds.