 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchema Encoding for Transferable Dialogue State Tracking
Oct 05, 2022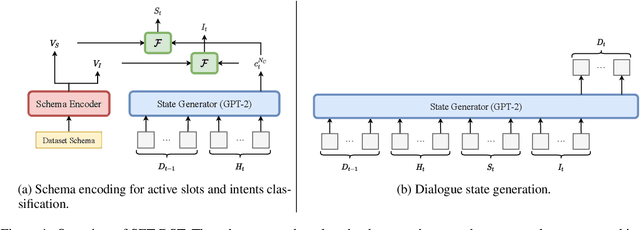
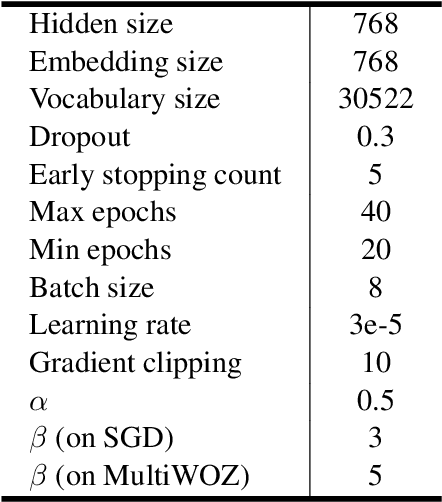

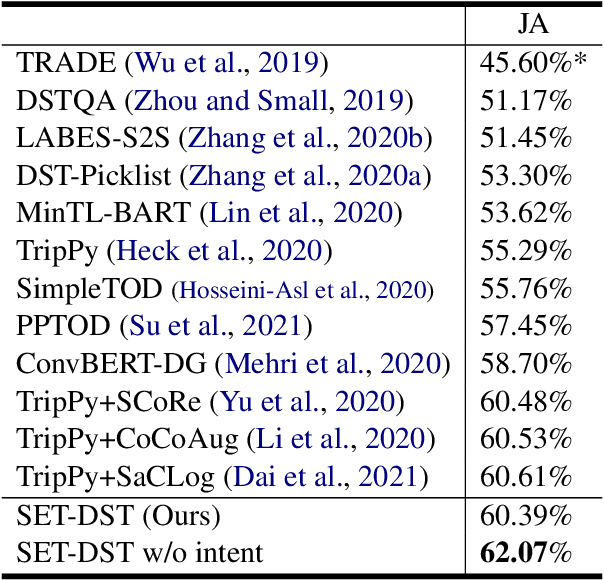
Dialogue state tracking (DST) is an essential sub-task for task-oriented dialogue systems. Recent work has focused on deep neural models for DST. However, the neural models require a large dataset for training. Furthermore, applying them to another domain needs a new dataset because the neural models are generally trained to imitate the given dataset. In this paper, we propose Schema Encoding for Transferable Dialogue State Tracking (SETDST), which is a neural DST method for effective transfer to new domains. Transferable DST could assist developments of dialogue systems even with few dataset on target domains. We use a schema encoder not just to imitate the dataset but to comprehend the schema of the dataset. We aim to transfer the model to new domains by encoding new schemas and using them for DST on multi-domain settings. As a result, SET-DST improved the joint accuracy by 1.46 points on MultiWOZ 2.1.
DORA: Toward Policy Optimization for Task-oriented Dialogue System with Efficient Context
Jul 07, 2021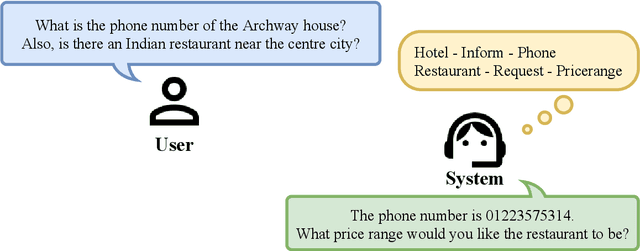
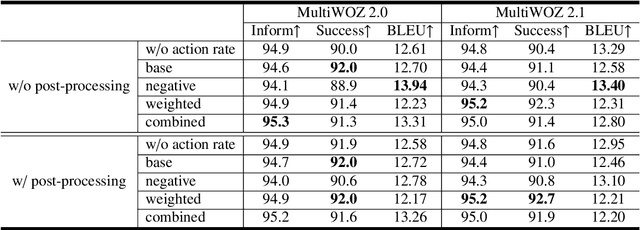
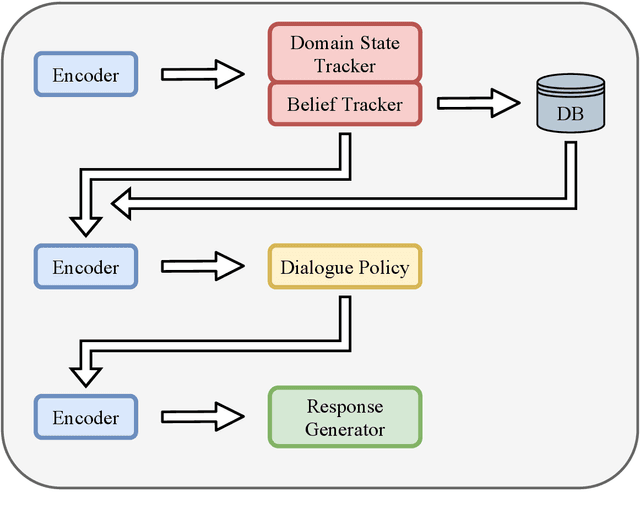
Recently, reinforcement learning (RL) has been applied to task-oriented dialogue systems by using latent actions to solve shortcomings of supervised learning (SL). In this paper, we propose a multi-domain task-oriented dialogue system, called Dialogue System with Optimizing a Recurrent Action Policy using Efficient Context (DORA), that uses SL, with subsequently applied RL to optimize dialogue systems using a recurrent dialogue policy. This dialogue policy recurrently generates explicit system actions as a both word-level and high-level policy. As a result, DORA is clearly optimized during both SL and RL steps by using an explicit system action policy that considers an efficient context instead of the entire dialogue history. The system actions are both interpretable and controllable, whereas the latent actions are not. DORA improved the success rate by 6.6 points on MultiWOZ 2.0 and by 10.9 points on MultiWOZ 2.1.
Domain State Tracking for a Simplified Dialogue System
Mar 11, 2021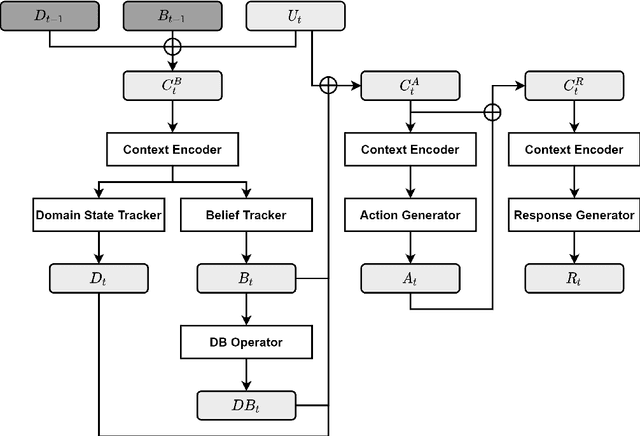
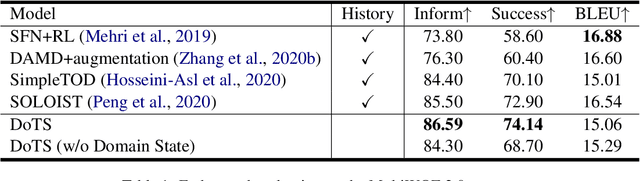
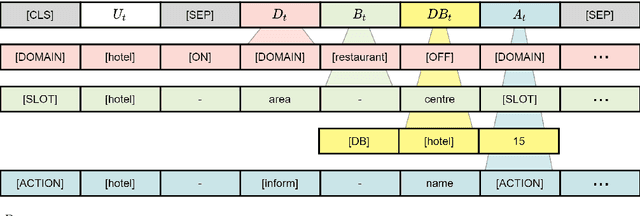
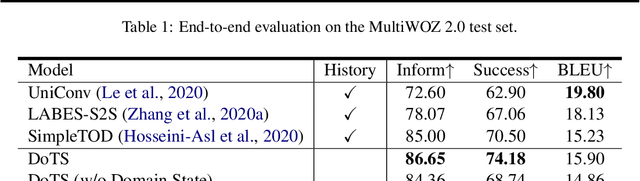
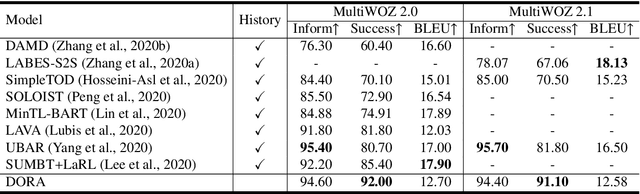
Task-oriented dialogue systems aim to help users achieve their goals in specific domains. Recent neural dialogue systems use the entire dialogue history for abundant contextual information accumulated over multiple conversational turns. However, the dialogue history becomes increasingly longer as the number of turns increases, thereby increasing memory usage and computational costs. In this paper, we present DoTS (Domain State Tracking for a Simplified Dialogue System), a task-oriented dialogue system that uses a simplified input context instead of the entire dialogue history. However, neglecting the dialogue history can result in a loss of contextual information from previous conversational turns. To address this issue, DoTS tracks the domain state in addition to the belief state and uses it for the input context. Using this simplified input, DoTS improves the inform rate and success rate by 1.09 points and 1.24 points, respectively, compared to the previous state-of-the-art model on MultiWOZ, which is a well-known benchmark.