 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparisons between a Large Language Model-based Real-Time Compound Diagnostic Medical AI Interface and Physicians for Common Internal Medicine Cases using Simulated Patients
May 27, 2025Objective To develop an LLM based realtime compound diagnostic medical AI interface and performed a clinical trial comparing this interface and physicians for common internal medicine cases based on the United States Medical License Exam (USMLE) Step 2 Clinical Skill (CS) style exams. Methods A nonrandomized clinical trial was conducted on August 20, 2024. We recruited one general physician, two internal medicine residents (2nd and 3rd year), and five simulated patients. The clinical vignettes were adapted from the USMLE Step 2 CS style exams. We developed 10 representative internal medicine cases based on actual patients and included information available on initial diagnostic evaluation. Primary outcome was the accuracy of the first differential diagnosis. Repeatability was evaluated based on the proportion of agreement. Results The accuracy of the physicians' first differential diagnosis ranged from 50% to 70%, whereas the realtime compound diagnostic medical AI interface achieved an accuracy of 80%. The proportion of agreement for the first differential diagnosis was 0.7. The accuracy of the first and second differential diagnoses ranged from 70% to 90% for physicians, whereas the AI interface achieved an accuracy rate of 100%. The average time for the AI interface (557 sec) was 44.6% shorter than that of the physicians (1006 sec). The AI interface ($0.08) also reduced costs by 98.1% compared to the physicians' average ($4.2). Patient satisfaction scores ranged from 4.2 to 4.3 for care by physicians and were 3.9 for the AI interface Conclusion An LLM based realtime compound diagnostic medical AI interface demonstrated diagnostic accuracy and patient satisfaction comparable to those of a physician, while requiring less time and lower costs. These findings suggest that AI interfaces may have the potential to assist primary care consultations for common internal medicine cases.
Reinforcement learning with distance-based incentive/penalty (DIP) updates for highly constrained industrial control systems
Nov 22, 2020



Typical reinforcement learning (RL) methods show limited applicability for real-world industrial control problems because industrial systems involve various constraints and simultaneously require continuous and discrete control. To overcome these challenges, we devise a novel RL algorithm that enables an agent to handle a highly constrained action space. This algorithm has two main features. First, we devise two distance-based Q-value update schemes, incentive update and penalty update, in a distance-based incentive/penalty update technique to enable the agent to decide discrete and continuous actions in the feasible region and to update the value of these types of actions. Second, we propose a method for defining the penalty cost as a shadow price-weighted penalty. This approach affords two advantages compared to previous methods to efficiently induce the agent to not select an infeasible action. We apply our algorithm to an industrial control problem, microgrid system operation, and the experimental results demonstrate its superiority.
Delayed Q-update: A novel credit assignment technique for deriving an optimal operation policy for the Grid-Connected Microgrid
Jun 30, 2020



A microgrid is an innovative system that integrates distributed energy resources to supply electricity demand within electrical boundaries. This study proposes an approach for deriving a desirable microgrid operation policy that enables sophisticated controls in the microgrid system using the proposed novel credit assignment technique, delayed-Q update. The technique employs novel features such as the ability to tackle and resolve the delayed effective property of the microgrid, which prevents learning agents from deriving a well-fitted policy under sophisticated controls. The proposed technique tracks the history of the charging period and retroactively assigns an adjusted value to the ESS charging control. The operation policy derived using the proposed approach is well-fitted for the real effects of ESS operation because of the process of the technique. Therefore, it supports the search for a near-optimal operation policy under a sophisticatedly controlled microgrid environment. To validate our technique, we simulate the operation policy under a real-world grid-connected microgrid system and demonstrate the convergence to a near-optimal policy by comparing performance measures of our policy with benchmark policy and optimal policy.
An intelligent financial portfolio trading strategy using deep Q-learning
Aug 31, 2019
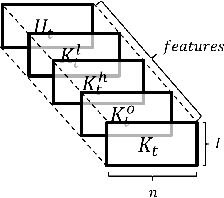


Portfolio traders strive to identify dynamic portfolio allocation schemes so that their total budgets are well allocated through the investment horizon. This study proposes a novel portfolio trading strategy in which an intelligent agent is trained to identify an optimal trading action by using an algorithm called deep Q-learning. This study formulates a portfolio trading process as a Markov decision process in which the agent can learn about the financial market environment, and it identifies a deep neural network structure as an approximation of the Q-function. To ensure applicability to real-world trading, we devise three novel techniques that are both reasonable and implementable. First, the agent's action space is modeled as a combinatorial action space of trading directions with prespecified trading sizes for each asset. Second, we introduce a mapping function that can replace an initially-determined action that may be infeasible with a feasible action that is reasonably close to the original, ideal action. Last, we introduce a technique by which an agent simulates all feasible actions in each state and learns about these experiences to derive a multi-asset trading strategy that best reflects financial data. To validate our approach, we conduct backtests for two representative portfolios and demonstrate superior results over the benchmark strategies.