 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Video Enhancement with Deblurring, Super-Resolution, and Frame Interpolation Network
Jun 04, 2025Video quality is often severely degraded by multiple factors rather than a single factor. These low-quality videos can be restored to high-quality videos by sequentially performing appropriate video enhancement techniques. However, the sequential approach was inefficient and sub-optimal because most video enhancement approaches were designed without taking into account that multiple factors together degrade video quality. In this paper, we propose a new joint video enhancement method that mitigates multiple degradation factors simultaneously by resolving an integrated enhancement problem. Our proposed network, named DSFN, directly produces a high-resolution, high-frame-rate, and clear video from a low-resolution, low-frame-rate, and blurry video. In the DSFN, low-resolution and blurry input frames are enhanced by a joint deblurring and super-resolution (JDSR) module. Meanwhile, intermediate frames between input adjacent frames are interpolated by a triple-frame-based frame interpolation (TFBFI) module. The proper combination of the proposed modules of DSFN can achieve superior performance on the joint video enhancement task. Experimental results show that the proposed method outperforms other sequential state-of-the-art techniques on public datasets with a smaller network size and faster processing time.
Video Deblurring with Deconvolution and Aggregation Networks
Jun 04, 2025In contrast to single-image deblurring, video deblurring has the advantage that neighbor frames can be utilized to deblur a target frame. However, existing video deblurring algorithms often fail to properly employ the neighbor frames, resulting in sub-optimal performance. In this paper, we propose a deconvolution and aggregation network (DAN) for video deblurring that utilizes the information of neighbor frames well. In DAN, both deconvolution and aggregation strategies are achieved through three sub-networks: the preprocessing network (PPN) and the alignment-based deconvolution network (ABDN) for the deconvolution scheme; the frame aggregation network (FAN) for the aggregation scheme. In the deconvolution part, blurry inputs are first preprocessed by the PPN with non-local operations. Then, the output frames from the PPN are deblurred by the ABDN based on the frame alignment. In the FAN, these deblurred frames from the deconvolution part are combined into a latent frame according to reliability maps which infer pixel-wise sharpness. The proper combination of three sub-networks can achieve favorable performance on video deblurring by using the neighbor frames suitably. In experiments, the proposed DAN was demonstrated to be superior to existing state-of-the-art methods through both quantitative and qualitative evaluations on the public datasets.
Only-Train-Once MR Fingerprinting for Magnetization Transfer Contrast Quantification
Jun 09, 2022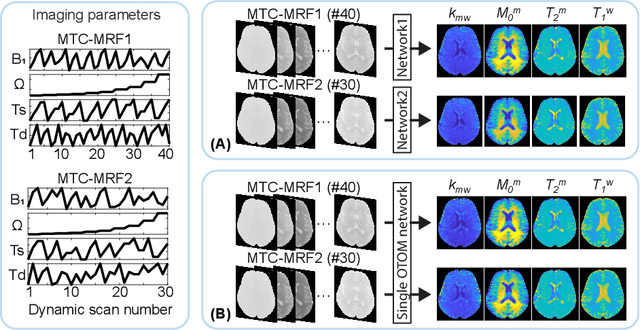
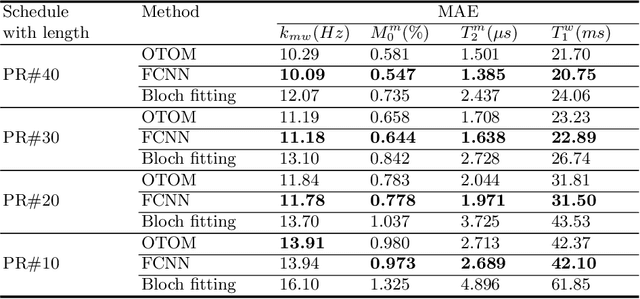
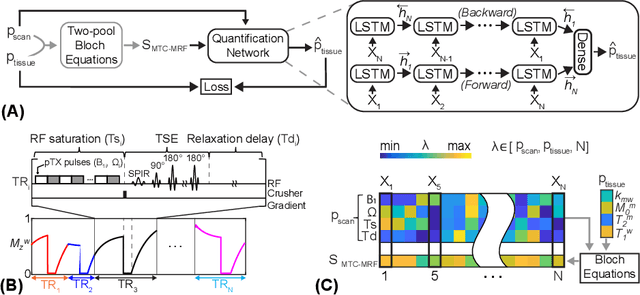

Magnetization transfer contrast magnetic resonance fingerprinting (MTC-MRF) is a novel quantitative imaging technique that simultaneously measures several tissue parameters of semisolid macromolecule and free bulk water. In this study, we propose an Only-Train-Once MR fingerprinting (OTOM) framework that estimates the free bulk water and MTC tissue parameters from MR fingerprints regardless of MRF schedule, thereby avoiding time-consuming process such as generation of training dataset and network training according to each MRF schedule. A recurrent neural network is designed to cope with two types of variants of MRF schedules: 1) various lengths and 2) various patterns. Experiments on digital phantoms and in vivo data demonstrate that our approach can achieve accurate quantification for the water and MTC parameters with multiple MRF schedules. Moreover, the proposed method is in excellent agreement with the conventional deep learning and fitting methods. The flexible OTOM framework could be an efficient tissue quantification tool for various MRF protocols.
Synthesis of Brain Tumor MR Images for Learning Data Augmentation
Mar 17, 2020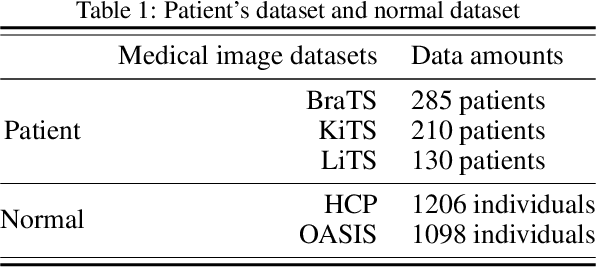
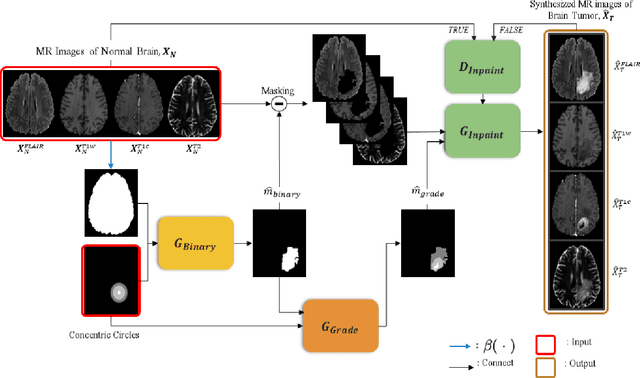
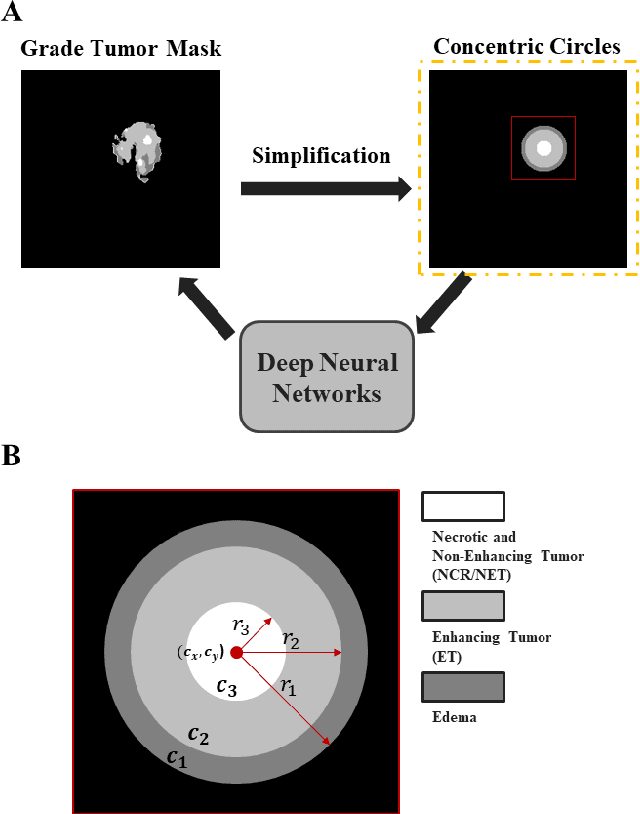

Medical image analysis using deep neural networks has been actively studied. Deep neural networks are trained by learning data. For accurate training of deep neural networks, the learning data should be sufficient, of good quality, and should have a generalized property. However, in medical images, it is difficult to acquire sufficient patient data because of the difficulty of patient recruitment, the burden of annotation of lesions by experts, and the invasion of patients' privacy. In comparison, the medical images of healthy volunteers can be easily acquired. Using healthy brain images, the proposed method synthesizes multi-contrast magnetic resonance images of brain tumors. Because tumors have complex features, the proposed method simplifies them into concentric circles that are easily controllable. Then it converts the concentric circles into various realistic shapes of tumors through deep neural networks. Because numerous healthy brain images are easily available, our method can synthesize a huge number of the brain tumor images with various concentric circles. We performed qualitative and quantitative analysis to assess the usefulness of augmented data from the proposed method. Intuitive and interesting experimental results are available online at https://github.com/KSH0660/BrainTumor
Attention Guided Metal Artifact Correction in MRI using Deep Neural Networks
Oct 19, 2019



An attention guided scheme for metal artifact correction in MRI using deep neural network is proposed in this paper. The inputs of the networks are two distorted images obtained with dual-polarity readout gradients. With MR image generation module and the additional data consistency loss to the previous work [1], the network is trained to estimate the frequency-shift map, off-resonance map, and attention map. The attention map helps to produce better distortion-corrected images by weighting on more relevant distortion-corrected images where two distortion-corrected images are produced with half of the frequency-shift maps. In this paper, we observed that in a real MRI environment, two distorted images obtained with opposite polarities of readout gradient showed artifacts in a different region. Therefore, we proved that using the attention map was important in that it reduced the residual ripple and pile-up artifacts near metallic implants.
* 6 pages, 5 figures