 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill Once, Adapt Life-Long: Exploring Dataset Distillation for Continual Test-Time Adaptation
Jun 18, 2026Continual Test-Time Adaptation (CTTA) aims to maintain model performance under evolving target domains by adapting online without labeled data. However, practical deployments often cannot retain the source dataset due to privacy or licensing constraints, and purely source-free CTTA methods tend to become unstable under long-term distribution shift, suffering from compounding self-training errors and catastrophic forgetting. We introduce DO-ALL (Distill Once, Adapt Life-Long), a plug-and-play framework that revisits source information in a compact and privacy-conscious form via Dataset Distillation (DD). Before deployment, DO-ALL performs DD to produce a small set of synthetic distilled anchors that summarize the source distribution. During adaptation, each target sample is matched with its most semantically aligned anchor, which provides a stable reference for various CTTA via source replay, representation alignment, and manifold-smoothing regularization. DO-ALL can be seamlessly integrated into existing CTTA algorithms, consistently improving long-term robustness across CIFAR100-C, ImageNet-C, and the CCC benchmark. This demonstrates the potential of leveraging DD to enable stable and continuous adaptation without retaining raw source data. The code is available at https://github.com/blue-531/DOALL.
Bootstrapping Video Semantic Segmentation Model via Distillation-assisted Test-Time Adaptation
Apr 14, 2026Fully supervised Video Semantic Segmentation (VSS) relies heavily on densely annotated video data, limiting practical applicability. Alternatively, applying pre-trained Image Semantic Segmentation (ISS) models frame-by-frame avoids annotation costs but ignores crucial temporal coherence. Recent foundation models such as SAM2 enable high-quality mask propagation yet remain impractical for direct VSS due to limited semantic understanding and computational overhead. In this paper, we propose DiTTA (Distillation-assisted Test-Time Adaptation), a novel framework that converts an ISS model into a temporally-aware VSS model through efficient test-time adaptation (TTA), without annotated videos. DiTTA distills SAM2's temporal segmentation knowledge into the ISS model during a brief, single-pass initialization phase, complemented by a lightweight temporal fusion module to aggregate cross-frame context. Crucially, DiTTA achieves robust generalization even when adapting with highly limited partial video snippets (e.g., initial 10%), significantly outperforming zero-shot refinement approaches that repeatedly invoke SAM2 during inference. Extensive experiments on VSPW and Cityscapes demonstrate DiTTA's effectiveness, achieving competitive or superior performance relative to fully-supervised VSS methods, thus providing a practical and annotation-free solution for real-world VSS tasks.
TALoS: Enhancing Semantic Scene Completion via Test-time Adaptation on the Line of Sight
Oct 21, 2024Semantic Scene Completion (SSC) aims to perform geometric completion and semantic segmentation simultaneously. Despite the promising results achieved by existing studies, the inherently ill-posed nature of the task presents significant challenges in diverse driving scenarios. This paper introduces TALoS, a novel test-time adaptation approach for SSC that excavates the information available in driving environments. Specifically, we focus on that observations made at a certain moment can serve as Ground Truth (GT) for scene completion at another moment. Given the characteristics of the LiDAR sensor, an observation of an object at a certain location confirms both 1) the occupation of that location and 2) the absence of obstacles along the line of sight from the LiDAR to that point. TALoS utilizes these observations to obtain self-supervision about occupancy and emptiness, guiding the model to adapt to the scene in test time. In a similar manner, we aggregate reliable SSC predictions among multiple moments and leverage them as semantic pseudo-GT for adaptation. Further, to leverage future observations that are not accessible at the current time, we present a dual optimization scheme using the model in which the update is delayed until the future observation is available. Evaluations on the SemanticKITTI validation and test sets demonstrate that TALoS significantly improves the performance of the pre-trained SSC model. Our code is available at https://github.com/blue-531/TALoS.
Finding Meaning in Points: Weakly Supervised Semantic Segmentation for Event Cameras
Jul 15, 2024



Event cameras excel in capturing high-contrast scenes and dynamic objects, offering a significant advantage over traditional frame-based cameras. Despite active research into leveraging event cameras for semantic segmentation, generating pixel-wise dense semantic maps for such challenging scenarios remains labor-intensive. As a remedy, we present EV-WSSS: a novel weakly supervised approach for event-based semantic segmentation that utilizes sparse point annotations. To fully leverage the temporal characteristics of event data, the proposed framework performs asymmetric dual-student learning between 1) the original forward event data and 2) the longer reversed event data, which contain complementary information from the past and the future, respectively. Besides, to mitigate the challenges posed by sparse supervision, we propose feature-level contrastive learning based on class-wise prototypes, carefully aggregated at both spatial region and sample levels. Additionally, we further excavate the potential of our dual-student learning model by exchanging prototypes between the two learning paths, thereby harnessing their complementary strengths. With extensive experiments on various datasets, including DSEC Night-Point with sparse point annotations newly provided by this paper, the proposed method achieves substantial segmentation results even without relying on pixel-level dense ground truths. The code and dataset are available at https://github.com/Chohoonhee/EV-WSSS.
Pixel-wise Deep Image Stitching
Dec 12, 2021
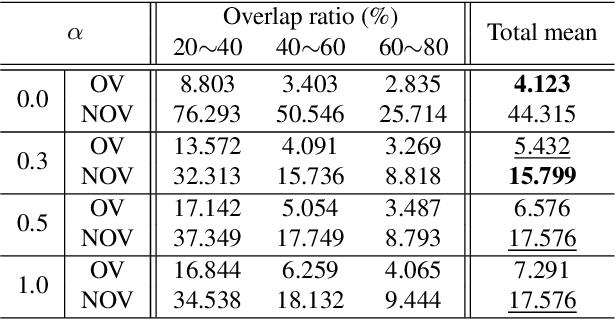
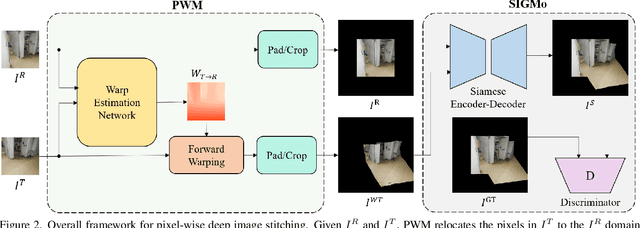
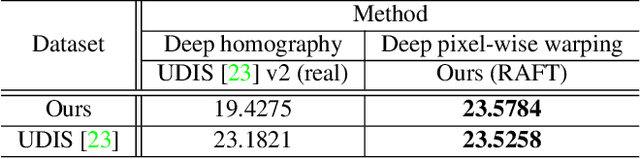
Image stitching aims at stitching the images taken from different viewpoints into an image with a wider field of view. Existing methods warp the target image to the reference image using the estimated warp function, and a homography is one of the most commonly used warping functions. However, when images have large parallax due to non-planar scenes and translational motion of a camera, the homography cannot fully describe the mapping between two images. Existing approaches based on global or local homography estimation are not free from this problem and suffer from undesired artifacts due to parallax. In this paper, instead of relying on the homography-based warp, we propose a novel deep image stitching framework exploiting the pixel-wise warp field to handle the large-parallax problem. The proposed deep image stitching framework consists of two modules: Pixel-wise Warping Module (PWM) and Stitched Image Generating Module (SIGMo). PWM employs an optical flow estimation model to obtain pixel-wise warp of the whole image, and relocates the pixels of the target image with the obtained warp field. SIGMo blends the warped target image and the reference image while eliminating unwanted artifacts such as misalignments, seams, and holes that harm the plausibility of the stitched result. For training and evaluating the proposed framework, we build a large-scale dataset that includes image pairs with corresponding pixel-wise ground truth warp and sample stitched result images. We show that the results of the proposed framework are qualitatively superior to those of the conventional methods, especially when the images have large parallax. The code and the proposed dataset will be publicly available soon.
Exploring Pixel-level Self-supervision for Weakly Supervised Semantic Segmentation
Dec 10, 2021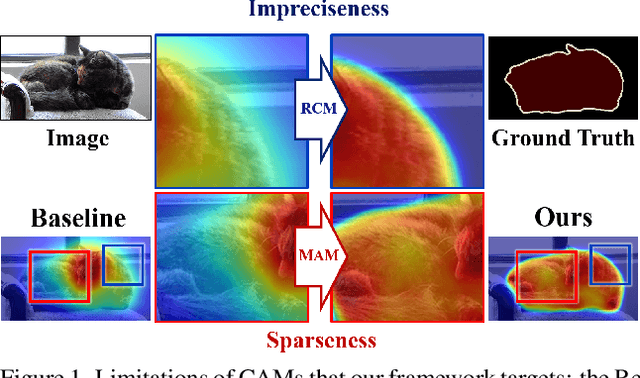
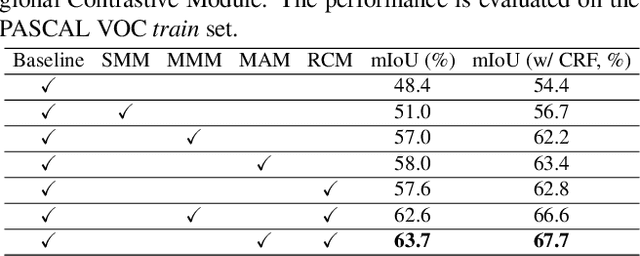
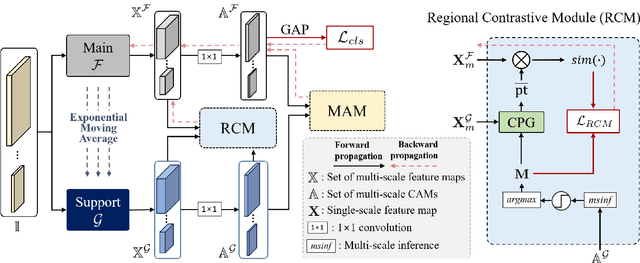
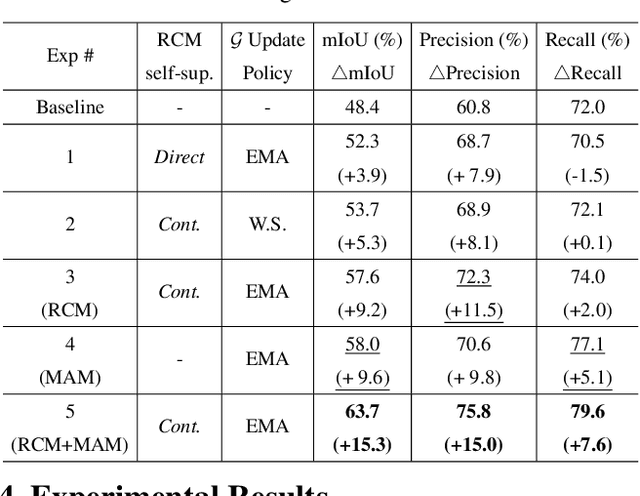
Existing studies in weakly supervised semantic segmentation (WSSS) have utilized class activation maps (CAMs) to localize the class objects. However, since a classification loss is insufficient for providing precise object regions, CAMs tend to be biased towards discriminative patterns (i.e., sparseness) and do not provide precise object boundary information (i.e., impreciseness). To resolve these limitations, we propose a novel framework (composed of MainNet and SupportNet.) that derives pixel-level self-supervision from given image-level supervision. In our framework, with the help of the proposed Regional Contrastive Module (RCM) and Multi-scale Attentive Module (MAM), MainNet is trained by self-supervision from the SupportNet. The RCM extracts two forms of self-supervision from SupportNet: (1) class region masks generated from the CAMs and (2) class-wise prototypes obtained from the features according to the class region masks. Then, every pixel-wise feature of the MainNet is trained by the prototype in a contrastive manner, sharpening the resulting CAMs. The MAM utilizes CAMs inferred at multiple scales from the SupportNet as self-supervision to guide the MainNet. Based on the dissimilarity between the multi-scale CAMs from MainNet and SupportNet, CAMs from the MainNet are trained to expand to the less-discriminative regions. The proposed method shows state-of-the-art WSSS performance both on the train and validation sets on the PASCAL VOC 2012 dataset. For reproducibility, code will be available publicly soon.