 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based SQL Generation: Prompting, Self-Refinement, and Adaptive Weighted Majority Voting
Jan 25, 2026Text-to-SQL has emerged as a prominent research area, particularly with the rapid advancement of large language models (LLMs). By enabling users to query databases through natural language rather than SQL, this technology significantly lowers the barrier to data analysis. However, generating accurate SQL from natural language remains challenging due to ambiguity in user queries, the complexity of schema linking, limited generalization across SQL dialects, and the need for domain-specific understanding. In this study, we propose a Single-Agent Self-Refinement with Ensemble Voting (SSEV) pipeline built on PET-SQL that operates without ground-truth data, integrating self-refinement with Weighted Majority Voting (WMV) and its randomized variant (RWMA). Experimental results show that the SSEV achieves competitive performance across multiple benchmarks, attaining execution accuracies of 85.5% on Spider 1.0-Dev, 86.4% on Spider 1.0-Test, and 66.3% on BIRD-Dev. Building on insights from the SSEV pipeline, we further propose ReCAPAgent-SQL (Refinement-Critique-Act-Plan agent-based SQL framework) to address the growing complexity of enterprise databases and real-world Text-to-SQL tasks. The framework integrates multiple specialized agents for planning, external knowledge retrieval, critique, action generation, self-refinement, schema linking, and result validation, enabling iterative refinement of SQL predictions through agent collaboration. ReCAPAgent-SQL's WMA results achieve 31% execution accuracy on the first 100 queries of Spider 2.0-Lite, demonstrating significant improvements in handling real-world enterprise scenarios. Overall, our work facilitates the deployment of scalable Text-to-SQL systems in practical settings, supporting better data-driven decision-making at lower cost and with greater efficiency.
Coding With AI: From a Reflection on Industrial Practices to Future Computer Science and Software Engineering Education
Dec 30, 2025Recent advances in large language models (LLMs) have introduced new paradigms in software development, including vibe coding, AI-assisted coding, and agentic coding, fundamentally reshaping how software is designed, implemented, and maintained. Prior research has primarily examined AI-based coding at the individual level or in educational settings, leaving industrial practitioners' perspectives underexplored. This paper addresses this gap by investigating how LLM coding tools are used in professional practice, the associated concerns and risks, and the resulting transformations in development workflows, with particular attention to implications for computing education. We conducted a qualitative analysis of 57 curated YouTube videos published between late 2024 and 2025, capturing reflections and experiences shared by practitioners. Following a filtering and quality assessment process, the selected sources were analyzed to compare LLM-based and traditional programming, identify emerging risks, and characterize evolving workflows. Our findings reveal definitions of AI-based coding practices, notable productivity gains, and lowered barriers to entry. Practitioners also report a shift in development bottlenecks toward code review and concerns regarding code quality, maintainability, security vulnerabilities, ethical issues, erosion of foundational problem-solving skills, and insufficient preparation of entry-level engineers. Building on these insights, we discuss implications for computer science and software engineering education and argue for curricular shifts toward problem-solving, architectural thinking, code review, and early project-based learning that integrates LLM tools. This study offers an industry-grounded perspective on AI-based coding and provides guidance for aligning educational practices with rapidly evolving professional realities.
Evaluation of Traffic Signals for Daily Traffic Pattern
Jun 26, 2025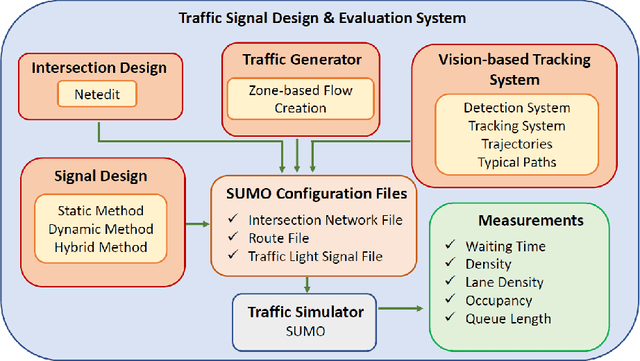

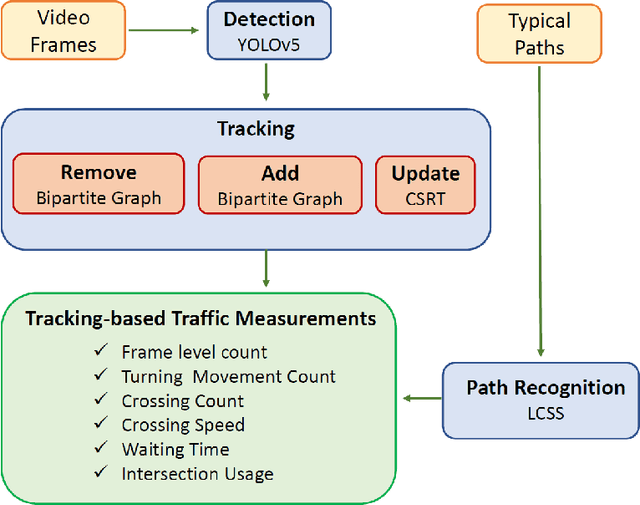
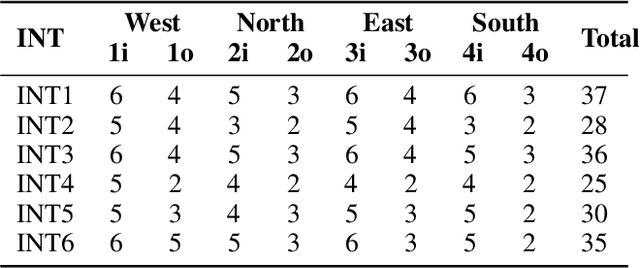
The turning movement count data is crucial for traffic signal design, intersection geometry planning, traffic flow, and congestion analysis. This work proposes three methods called dynamic, static, and hybrid configuration for TMC-based traffic signals. A vision-based tracking system is developed to estimate the TMC of six intersections in Las Vegas using traffic cameras. The intersection design, route (e.g. vehicle movement directions), and signal configuration files with compatible formats are synthesized and imported into Simulation of Urban MObility for signal evaluation with realistic data. The initial experimental results based on estimated waiting times indicate that the cycle time of 90 and 120 seconds works best for all intersections. In addition, four intersections show better performance for dynamic signal timing configuration, and the other two with lower performance have a lower ratio of total vehicle count to total lanes of the intersection leg. Since daily traffic flow often exhibits a bimodal pattern, we propose a hybrid signal method that switches between dynamic and static methods, adapting to peak and off-peak traffic conditions for improved flow management. So, a built-in traffic generator module creates vehicle routes for 4 hours, including peak hours, and a signal design module produces signal schedule cycles according to static, dynamic, and hybrid methods. Vehicle count distributions are weighted differently for each zone (i.e., West, North, East, South) to generate diverse traffic patterns. The extended experimental results for 6 intersections with 4 hours of simulation time imply that zone-based traffic pattern distributions affect signal design selection. Although the static method works great for evenly zone-based traffic distribution, the hybrid method works well for highly weighted traffic at intersection pairs of the West-East and North-South zones.
A Systematic Approach for Assessing Large Language Models' Test Case Generation Capability
Feb 05, 2025



Software testing ensures the quality and reliability of software products, but manual test case creation is labor-intensive. With the rise of large language models (LLMs), there is growing interest in unit test creation with LLMs. However, effective assessment of LLM-generated test cases is limited by the lack of standardized benchmarks that comprehensively cover diverse programming scenarios. To address the assessment of LLM's test case generation ability and lacking dataset for evaluation, we propose the Generated Benchmark from Control-Flow Structure and Variable Usage Composition (GBCV) approach, which systematically generates programs used for evaluating LLMs' test generation capabilities. By leveraging basic control-flow structures and variable usage, GBCV provides a flexible framework to create a spectrum of programs ranging from simple to complex. Because GPT-4o and GPT-3-Turbo are publicly accessible models, to present real-world regular user's use case, we use GBCV to assess LLM performance on them. Our findings indicate that GPT-4o performs better on complex program structures, while all models effectively detect boundary values in simple conditions but face challenges with arithmetic computations. This study highlights the strengths and limitations of LLMs in test generation, provides a benchmark framework, and suggests directions for future improvement.
A Framework for Collaborating a Large Language Model Tool in Brainstorming for Triggering Creative Thoughts
Oct 10, 2024



Creativity involves not only generating new ideas from scratch but also redefining existing concepts and synthesizing previous insights. Among various techniques developed to foster creative thinking, brainstorming is widely used. With recent advancements in Large Language Models (LLMs), tools like ChatGPT have significantly impacted various fields by using prompts to facilitate complex tasks. While current research primarily focuses on generating accurate responses, there is a need to explore how prompt engineering can enhance creativity, particularly in brainstorming. Therefore, this study addresses this gap by proposing a framework called GPS, which employs goals, prompts, and strategies to guide designers to systematically work with an LLM tool for improving the creativity of ideas generated during brainstorming. Additionally, we adapted the Torrance Tests of Creative Thinking (TTCT) for measuring the creativity of the ideas generated by AI. Our framework, tested through a design example and a case study, demonstrates its effectiveness in stimulating creativity and its seamless LLM tool integration into design practices. The results indicate that our framework can benefit brainstorming sessions with LLM tools, enhancing both the creativity and usefulness of generated ideas.
Leveraging Fundamental Analysis for Stock Trend Prediction for Profit
Oct 04, 2024

This paper investigates the application of machine learning models, Long Short-Term Memory (LSTM), one-dimensional Convolutional Neural Networks (1D CNN), and Logistic Regression (LR), for predicting stock trends based on fundamental analysis. Unlike most existing studies that predominantly utilize technical or sentiment analysis, we emphasize the use of a company's financial statements and intrinsic value for trend forecasting. Using a dataset of 269 data points from publicly traded companies across various sectors from 2019 to 2023, we employ key financial ratios and the Discounted Cash Flow (DCF) model to formulate two prediction tasks: Annual Stock Price Difference (ASPD) and Difference between Current Stock Price and Intrinsic Value (DCSPIV). These tasks assess the likelihood of annual profit and current profitability, respectively. Our results demonstrate that LR models outperform CNN and LSTM models, achieving an average test accuracy of 74.66% for ASPD and 72.85% for DCSPIV. This study contributes to the limited literature on integrating fundamental analysis into machine learning for stock prediction, offering valuable insights for both academic research and practical investment strategies. By leveraging fundamental data, our approach highlights the potential for long-term stock trend prediction, supporting portfolio managers in their decision-making processes.