 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCP-CLIP:A Coarse-to-Fine Framework for Open-Vocabulary Semantic Segmentation with Dual Interaction
Mar 14, 2026The recent years have witnessed the remarkable development for open-vocabulary semantic segmentation (OVSS) using visual-language foundation models, yet still suffer from following fundamental challenges: (1) insufficient cross-modal communications between textual and visual spaces, and (2) significant computational costs from the interactions with massive number of categories. To address these issues, this paper describes a novel coarse-to-fine framework, called DCP-CLIP, for OVSS. Unlike prior efforts that mainly relied on pre-established category content and the inherent spatial-class interaction capability of CLIP, we dynamic constructing category-relevant textual features and explicitly models dual interactions between spatial image features and textual class semantics. Specifically, we first leverage CLIP's open-vocabulary recognition capability to identify semantic categories relevant to the image context, upon which we dynamically generate corresponding textual features to serve as initial textual guidance. Subsequently, we conduct a coarse segmentation by cross-modally integrating semantic information from textual guidance into the visual representations and achieve refined segmentation by integrating spatially enriched features from the encoder to recover fine-grained details and enhance spatial resolution. In final, we leverage spatial information from the segmentation side to refine category predictions for each mask, facilitating more precise semantic labeling. Experiments on multiple OVSS benchmarks demonstrate that DCP-CLIP outperforms existing methods by delivering both higher accuracy and greater efficiency.
DPNet: Dual-Path Network for Real-time Object Detection with Lightweight Attention
Sep 28, 2022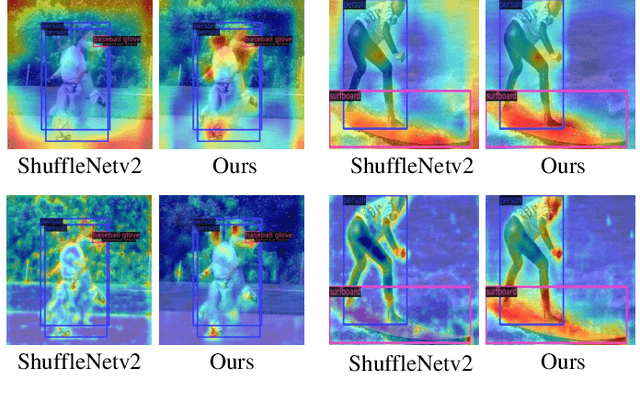
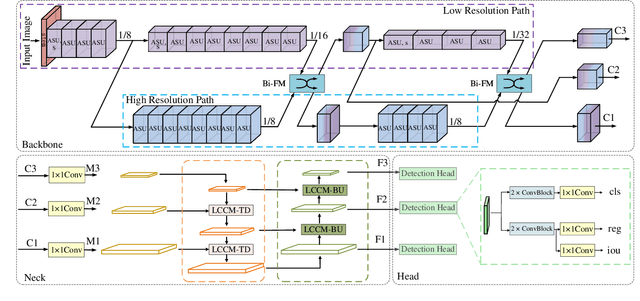
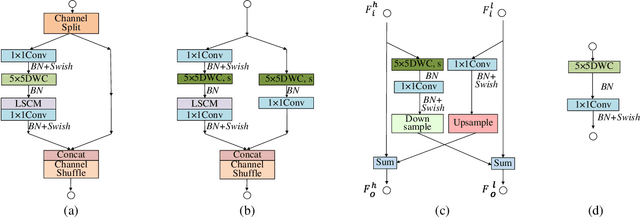
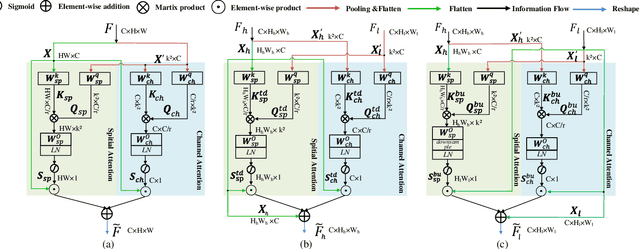
The recent advances of compressing high-accuracy convolution neural networks (CNNs) have witnessed remarkable progress for real-time object detection. To accelerate detection speed, lightweight detectors always have few convolution layers using single-path backbone. Single-path architecture, however, involves continuous pooling and downsampling operations, always resulting in coarse and inaccurate feature maps that are disadvantageous to locate objects. On the other hand, due to limited network capacity, recent lightweight networks are often weak in representing large scale visual data. To address these problems, this paper presents a dual-path network, named DPNet, with a lightweight attention scheme for real-time object detection. The dual-path architecture enables us to parallelly extract high-level semantic features and low-level object details. Although DPNet has nearly duplicated shape with respect to single-path detectors, the computational costs and model size are not significantly increased. To enhance representation capability, a lightweight self-correlation module (LSCM) is designed to capture global interactions, with only few computational overheads and network parameters. In neck, LSCM is extended into a lightweight crosscorrelation module (LCCM), capturing mutual dependencies among neighboring scale features. We have conducted exhaustive experiments on MS COCO and Pascal VOC 2007 datasets. The experimental results demonstrate that DPNet achieves state-of the-art trade-off between detection accuracy and implementation efficiency. Specifically, DPNet achieves 30.5% AP on MS COCO test-dev and 81.5% mAP on Pascal VOC 2007 test set, together mwith nearly 2.5M model size, 1.04 GFLOPs, and 164 FPS and 196 FPS for 320 x 320 input images of two datasets.
DPNET: Dual-Path Network for Efficient Object Detectioj with Lightweight Self-Attention
Oct 31, 2021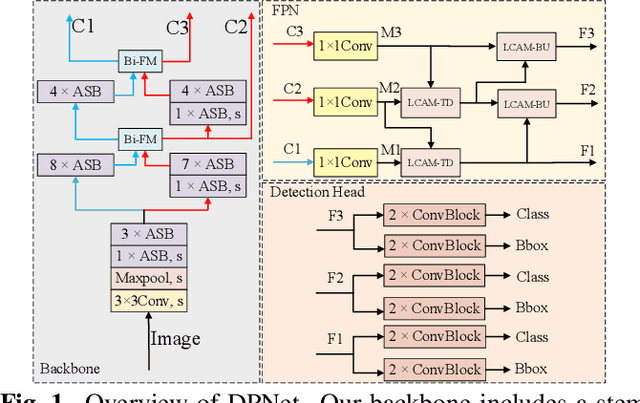
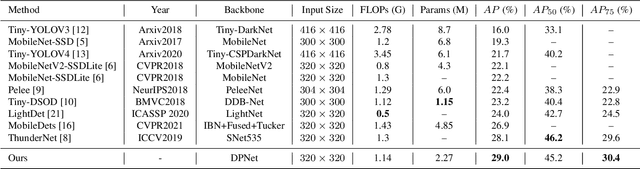
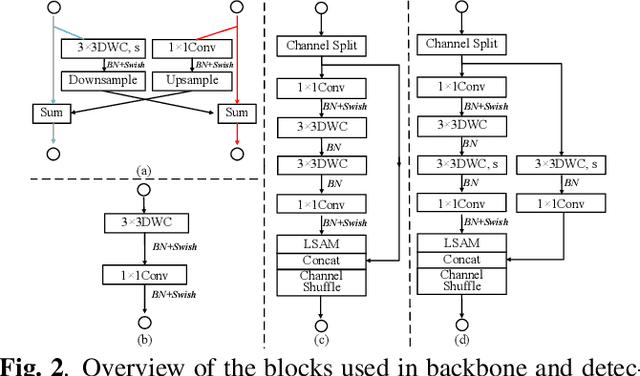
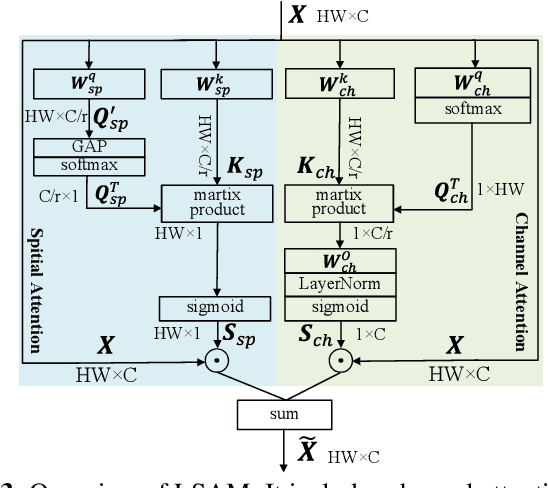
Object detection often costs a considerable amount of computation to get satisfied performance, which is unfriendly to be deployed in edge devices. To address the trade-off between computational cost and detection accuracy, this paper presents a dual path network, named DPNet, for efficient object detection with lightweight self-attention. In backbone, a single input/output lightweight self-attention module (LSAM) is designed to encode global interactions between different positions. LSAM is also extended into a multiple-inputs version in feature pyramid network (FPN), which is employed to capture cross-resolution dependencies in two paths. Extensive experiments on the COCO dataset demonstrate that our method achieves state-of-the-art detection results. More specifically, DPNet obtains 29.0% AP on COCO test-dev, with only 1.14 GFLOPs and 2.27M model size for a 320x320 image.