 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdMem: Advanced Memory for Task-solving Agents
Jun 05, 2026Large Language Models (LLMs) show promise as tool-using agents but remain limited in long-horizon tasks that require remembering, organizing, and reusing knowledge. Prior memory approaches aim to resolve the situation, but mainly focus on storing factual information. Recent work on procedural memory improves task reuse, yet often reduces to replaying past successes without addressing failure cases or online scalability. We introduce a unified and automatic memory framework that integrates semantic, episodic, and procedural memory in a bi-level design combining short-term and long-term stores. A multi-agent architecture with actor, memory, and critic agents enables automatic memory generation, reward annotation, and adaptive retrieval. Long-term memory is managed through reward-based evaluation, merging, and pruning, ensuring scalability and continual improvement. Experiments across various environments show that our approach improves robustness and success on long multi-turn tasks compared to existing baselines. This work highlights the importance of comprehensive, adaptive memory for advancing LLM-based agents.
Auto-Evolve: Enhancing Large Language Model's Performance via Self-Reasoning Framework
Oct 08, 2024

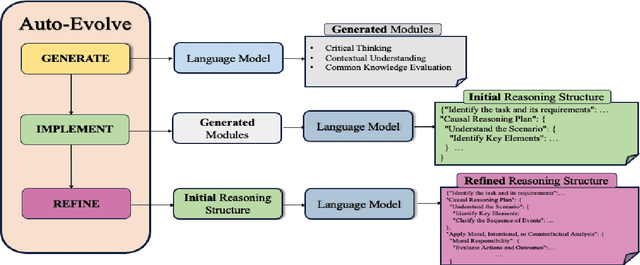

Recent advancements in prompt engineering strategies, such as Chain-of-Thought (CoT) and Self-Discover, have demonstrated significant potential in improving the reasoning abilities of Large Language Models (LLMs). However, these state-of-the-art (SOTA) prompting strategies rely on single or fixed set of static seed reasoning modules like \emph{"think step by step"} or \emph{"break down this problem"} intended to simulate human approach to problem-solving. This constraint limits the flexibility of models in tackling diverse problems effectively. In this paper, we introduce Auto-Evolve, a novel framework that enables LLMs to self-create dynamic reasoning modules and downstream action plan, resulting in significant improvements over current SOTA methods. We evaluate Auto-Evolve on the challenging BigBench-Hard (BBH) dataset with Claude 2.0, Claude 3 Sonnet, Mistral Large, and GPT 4, where it consistently outperforms the SOTA prompt strategies. Auto-Evolve outperforms CoT by up to 10.4\% and on an average by 7\% across these four models. Our framework introduces two innovations: a) Auto-Evolve dynamically generates reasoning modules for each task while aligning with human reasoning paradigm, thus eliminating the need for predefined templates. b) We introduce an iterative refinement component, that incrementally refines instruction guidance for LLMs and helps boost performance by average 2.8\% compared to doing it in a single step.