 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Information Systems Research
Oct 07, 2020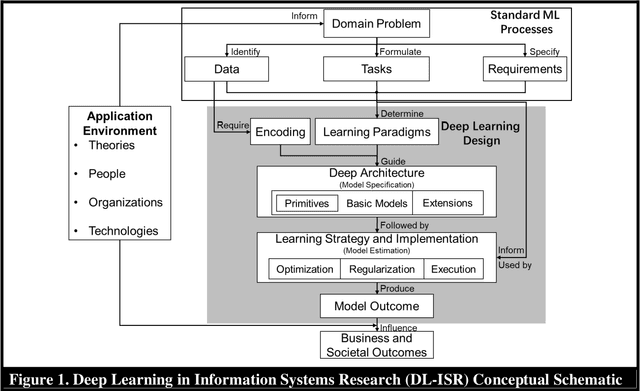
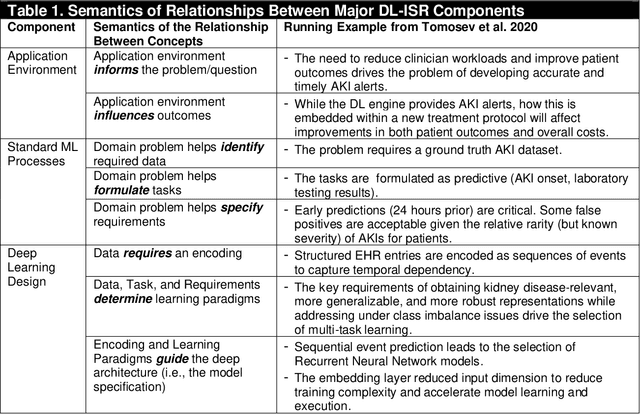
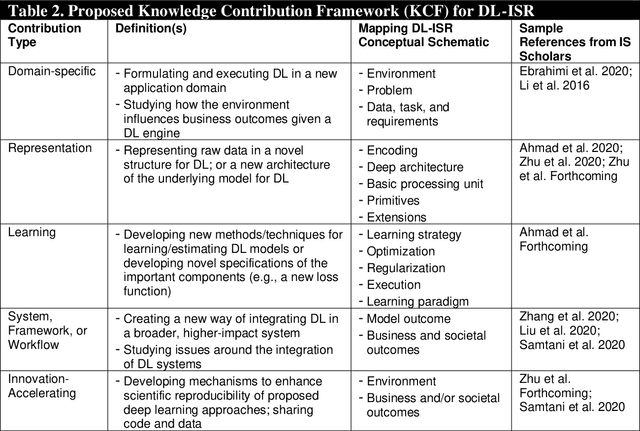
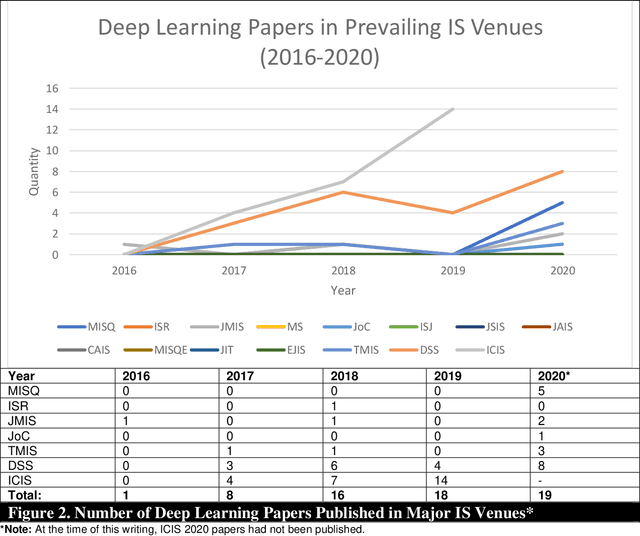
Artificial Intelligence (AI) has rapidly emerged as a key disruptive technology in the 21st century. At the heart of modern AI lies Deep Learning (DL), an emerging class of algorithms that has enabled today's platforms and organizations to operate at unprecedented efficiency, effectiveness, and scale. Despite significant interest, IS contributions in DL have been limited, which we argue is in part due to issues with defining, positioning, and conducting DL research. Recognizing the tremendous opportunity here for the IS community, this work clarifies, streamlines, and presents approaches for IS scholars to make timely and high-impact contributions. Related to this broader goal, this paper makes five timely contributions. First, we systematically summarize the major components of DL in a novel Deep Learning for Information Systems Research (DL-ISR) schematic that illustrates how technical DL processes are driven by key factors from an application environment. Second, we present a novel Knowledge Contribution Framework (KCF) to help IS scholars position their DL contributions for maximum impact. Third, we provide ten guidelines to help IS scholars generate rigorous and relevant DL-ISR in a systematic, high-quality fashion. Fourth, we present a review of prevailing journal and conference venues to examine how IS scholars have leveraged DL for various research inquiries. Finally, we provide a unique perspective on how IS scholars can formulate DL-ISR inquiries by carefully considering the interplay of business function(s), application areas(s), and the KCF. This perspective intentionally emphasizes inter-disciplinary, intra-disciplinary, and cross-IS tradition perspectives. Taken together, these contributions provide IS scholars a timely framework to advance the scale, scope, and impact of deep learning research.
Evaluating the Usefulness of Sentiment Information for Focused Crawlers
Sep 27, 2013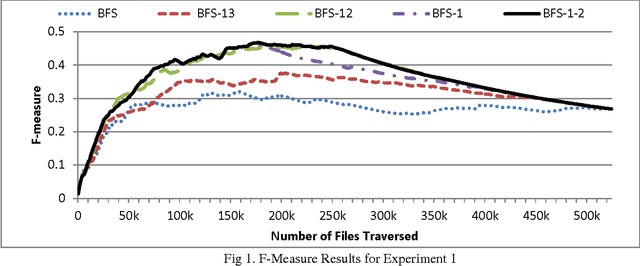
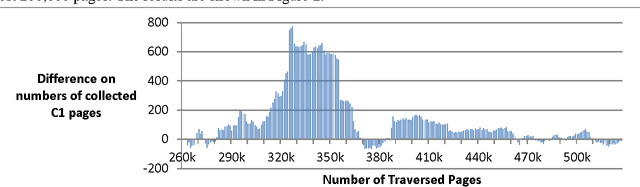
Despite the prevalence of sentiment-related content on the Web, there has been limited work on focused crawlers capable of effectively collecting such content. In this study, we evaluated the efficacy of using sentiment-related information for enhanced focused crawling of opinion-rich web content regarding a particular topic. We also assessed the impact of using sentiment-labeled web graphs to further improve collection accuracy. Experimental results on a large test bed encompassing over half a million web pages revealed that focused crawlers utilizing sentiment information as well as sentiment-labeled web graphs are capable of gathering more holistic collections of opinion-related content regarding a particular topic. The results have important implications for business and marketing intelligence gathering efforts in the Web 2.0 era.
A Statistical Learning Based System for Fake Website Detection
Sep 27, 2013Existing fake website detection systems are unable to effectively detect fake websites. In this study, we advocate the development of fake website detection systems that employ classification methods grounded in statistical learning theory (SLT). Experimental results reveal that a prototype system developed using SLT-based methods outperforms seven existing fake website detection systems on a test bed encompassing 900 real and fake websites.
Detecting Fake Escrow Websites using Rich Fraud Cues and Kernel Based Methods
Sep 27, 2013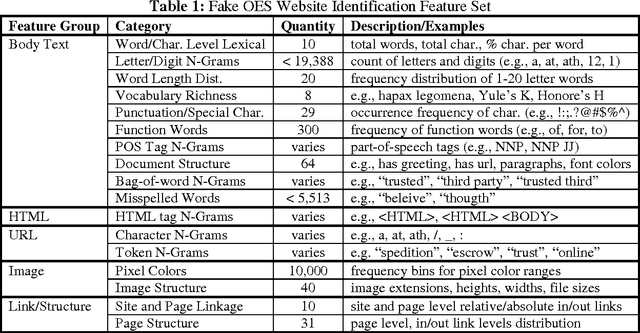

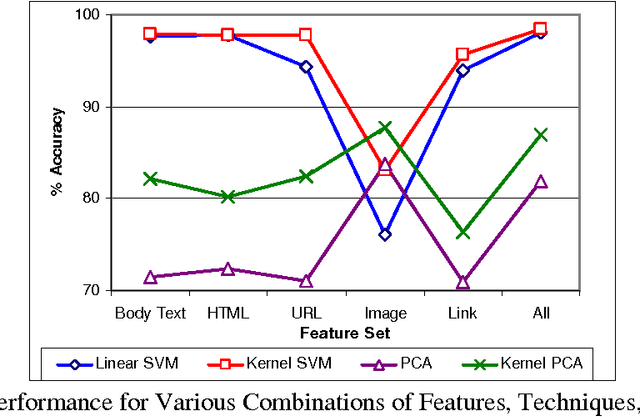
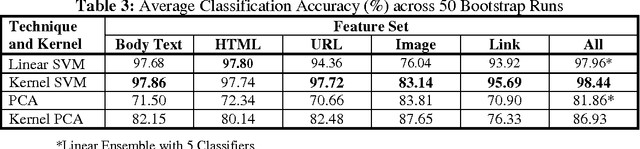
The ability to automatically detect fraudulent escrow websites is important in order to alleviate online auction fraud. Despite research on related topics, fake escrow website categorization has received little attention. In this study we evaluated the effectiveness of various features and techniques for detecting fake escrow websites. Our analysis included a rich set of features extracted from web page text, image, and link information. We also proposed a composite kernel tailored to represent the properties of fake websites, including content duplication and structural attributes. Experiments were conducted to assess the proposed features, techniques, and kernels on a test bed encompassing nearly 90,000 web pages derived from 410 legitimate and fake escrow sites. The combination of an extended feature set and the composite kernel attained over 98% accuracy when differentiating fake sites from real ones, using the support vector machines algorithm. The results suggest that automated web-based information systems for detecting fake escrow sites could be feasible and may be utilized as authentication mechanisms.