 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformers for Efficient Indoor Pathloss Radio Map Prediction
Dec 12, 2024



Vision Transformers (ViTs) have demonstrated remarkable success in achieving state-of-the-art performance across various image-based tasks and beyond. In this study, we employ a ViT-based neural network to address the problem of indoor pathloss radio map prediction. The network's generalization ability is evaluated across diverse settings, including unseen buildings, frequencies, and antennas with varying radiation patterns. By leveraging extensive data augmentation techniques and pretrained DINOv2 weights, we achieve promising results, even under the most challenging scenarios.
In-context Learning in Presence of Spurious Correlations
Oct 04, 2024



Large language models exhibit a remarkable capacity for in-context learning, where they learn to solve tasks given a few examples. Recent work has shown that transformers can be trained to perform simple regression tasks in-context. This work explores the possibility of training an in-context learner for classification tasks involving spurious features. We find that the conventional approach of training in-context learners is susceptible to spurious features. Moreover, when the meta-training dataset includes instances of only one task, the conventional approach leads to task memorization and fails to produce a model that leverages context for predictions. Based on these observations, we propose a novel technique to train such a learner for a given classification task. Remarkably, this in-context learner matches and sometimes outperforms strong methods like ERM and GroupDRO. However, unlike these algorithms, it does not generalize well to other tasks. We show that it is possible to obtain an in-context learner that generalizes to unseen tasks by training on a diverse dataset of synthetic in-context learning instances.
Small Molecule Optimization with Large Language Models
Jul 26, 2024Recent advancements in large language models have opened new possibilities for generative molecular drug design. We present Chemlactica and Chemma, two language models fine-tuned on a novel corpus of 110M molecules with computed properties, totaling 40B tokens. These models demonstrate strong performance in generating molecules with specified properties and predicting new molecular characteristics from limited samples. We introduce a novel optimization algorithm that leverages our language models to optimize molecules for arbitrary properties given limited access to a black box oracle. Our approach combines ideas from genetic algorithms, rejection sampling, and prompt optimization. It achieves state-of-the-art performance on multiple molecular optimization benchmarks, including an 8% improvement on Practical Molecular Optimization compared to previous methods. We publicly release the training corpus, the language models and the optimization algorithm.
Outdoor Environment Reconstruction with Deep Learning on Radio Propagation Paths
Feb 27, 2024


Conventional methods for outdoor environment reconstruction rely predominantly on vision-based techniques like photogrammetry and LiDAR, facing limitations such as constrained coverage, susceptibility to environmental conditions, and high computational and energy demands. These challenges are particularly pronounced in applications like augmented reality navigation, especially when integrated with wearable devices featuring constrained computational resources and energy budgets. In response, this paper proposes a novel approach harnessing ambient wireless signals for outdoor environment reconstruction. By analyzing radio frequency (RF) data, the paper aims to deduce the environmental characteristics and digitally reconstruct the outdoor surroundings. Investigating the efficacy of selected deep learning (DL) techniques on the synthetic RF dataset WAIR-D, the study endeavors to address the research gap in this domain. Two DL-driven approaches are evaluated (convolutional U-Net and CLIP+ based on vision transformers), with performance assessed using metrics like intersection-over-union (IoU), Hausdorff distance, and Chamfer distance. The results demonstrate promising performance of the RF-based reconstruction method, paving the way towards lightweight and scalable reconstruction solutions.
Analyzing Local Representations of Self-supervised Vision Transformers
Dec 31, 2023



In this paper, we present a comparative analysis of various self-supervised Vision Transformers (ViTs), focusing on their local representative power. Inspired by large language models, we examine the abilities of ViTs to perform various computer vision tasks with little to no fine-tuning. We design an evaluation framework to analyze the quality of local, i.e. patch-level, representations in the context of few-shot semantic segmentation, instance identification, object retrieval, and tracking. We discover that contrastive learning based methods like DINO produce more universal patch representations that can be immediately applied for downstream tasks with no parameter tuning, compared to masked image modeling. The embeddings learned using the latter approach, e.g. in masked autoencoders, have high variance features that harm distance-based algorithms, such as k-NN, and do not contain useful information for most downstream tasks. Furthermore, we demonstrate that removing these high-variance features enhances k-NN by providing an analysis of the benchmarks for this work and for Scale-MAE, a recent extension of masked autoencoders. Finally, we find an object instance retrieval setting where DINOv2, a model pretrained on two orders of magnitude more data, performs worse than its less compute-intensive counterpart DINO.
Identifying and Disentangling Spurious Features in Pretrained Image Representations
Jun 22, 2023



Neural networks employ spurious correlations in their predictions, resulting in decreased performance when these correlations do not hold. Recent works suggest fixing pretrained representations and training a classification head that does not use spurious features. We investigate how spurious features are represented in pretrained representations and explore strategies for removing information about spurious features. Considering the Waterbirds dataset and a few pretrained representations, we find that even with full knowledge of spurious features, their removal is not straightforward due to entangled representation. To address this, we propose a linear autoencoder training method to separate the representation into core, spurious, and other features. We propose two effective spurious feature removal approaches that are applied to the encoding and significantly improve classification performance measured by worst group accuracy.
ML-based Approaches for Wireless NLOS Localization: Input Representations and Uncertainty Estimation
Apr 22, 2023



The challenging problem of non-line-of-sight (NLOS) localization is critical for many wireless networking applications. The lack of available datasets has made NLOS localization difficult to tackle with ML-driven methods, but recent developments in synthetic dataset generation have provided new opportunities for research. This paper explores three different input representations: (i) single wireless radio path features, (ii) wireless radio link features (multi-path), and (iii) image-based representations. Inspired by the two latter new representations, we design two convolutional neural networks (CNNs) and we demonstrate that, although not significantly improving the NLOS localization performance, they are able to support richer prediction outputs, thus allowing deeper analysis of the predictions. In particular, the richer outputs enable reliable identification of non-trustworthy predictions and support the prediction of the top-K candidate locations for a given instance. We also measure how the availability of various features (such as angles of signal departure and arrival) affects the model's performance, providing insights about the types of data that should be collected for enhanced NLOS localization. Our insights motivate future work on building more efficient neural architectures and input representations for improved NLOS localization performance, along with additional useful application features.
BARTSmiles: Generative Masked Language Models for Molecular Representations
Nov 29, 2022



We discover a robust self-supervised strategy tailored towards molecular representations for generative masked language models through a series of tailored, in-depth ablations. Using this pre-training strategy, we train BARTSmiles, a BART-like model with an order of magnitude more compute than previous self-supervised molecular representations. In-depth evaluations show that BARTSmiles consistently outperforms other self-supervised representations across classification, regression, and generation tasks setting a new state-of-the-art on 11 tasks. We then quantitatively show that when applied to the molecular domain, the BART objective learns representations that implicitly encode our downstream tasks of interest. For example, by selecting seven neurons from a frozen BARTSmiles, we can obtain a model having performance within two percentage points of the full fine-tuned model on task Clintox. Lastly, we show that standard attribution interpretability methods, when applied to BARTSmiles, highlight certain substructures that chemists use to explain specific properties of molecules. The code and the pretrained model are publicly available.
Failure Modes of Domain Generalization Algorithms
Nov 26, 2021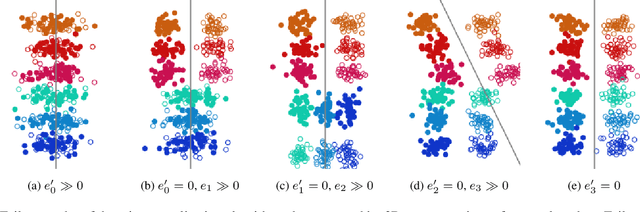

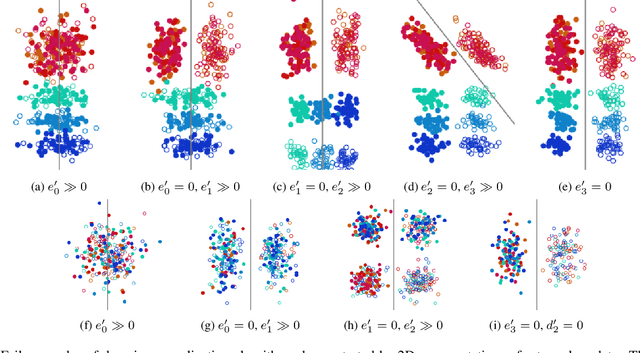
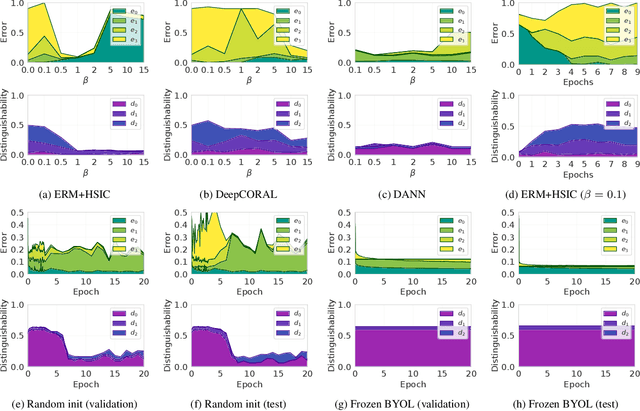
Domain generalization algorithms use training data from multiple domains to learn models that generalize well to unseen domains. While recently proposed benchmarks demonstrate that most of the existing algorithms do not outperform simple baselines, the established evaluation methods fail to expose the impact of various factors that contribute to the poor performance. In this paper we propose an evaluation framework for domain generalization algorithms that allows decomposition of the error into components capturing distinct aspects of generalization. Inspired by the prevalence of algorithms based on the idea of domain-invariant representation learning, we extend the evaluation framework to capture various types of failures in achieving invariance. We show that the largest contributor to the generalization error varies across methods, datasets, regularization strengths and even training lengths. We observe two problems associated with the strategy of learning domain-invariant representations. On Colored MNIST, most domain generalization algorithms fail because they reach domain-invariance only on the training domains. On Camelyon-17, domain-invariance degrades the quality of representations on unseen domains. We hypothesize that focusing instead on tuning the classifier on top of a rich representation can be a promising direction.
WARP: Word-level Adversarial ReProgramming
Jan 01, 2021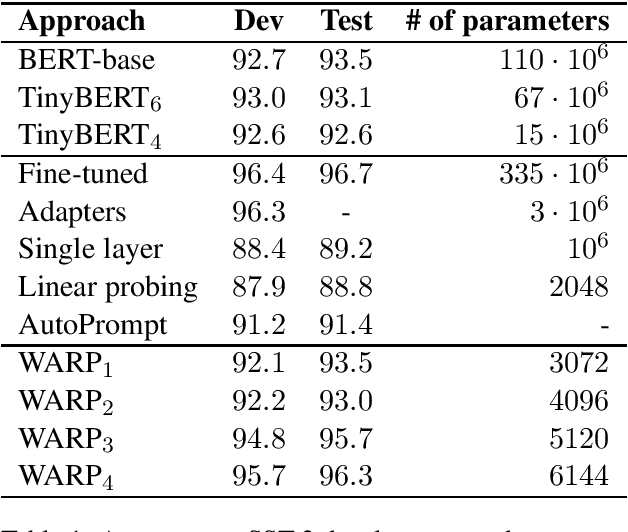
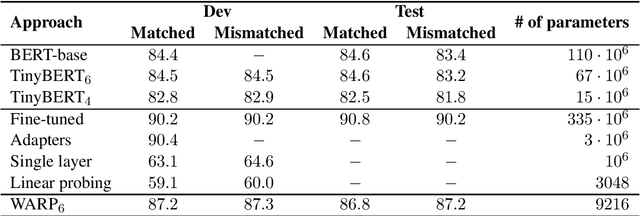

Transfer learning from pretrained language models recently became the dominant approach for solving many NLP tasks. While fine-tuning large language models usually gives the best performance, in many applications it is preferable to tune much smaller sets of parameters, so that the majority of parameters can be shared across multiple tasks. The main approach is to train one or more task-specific layers on top of the language model. In this paper we present an alternative approach based on adversarial reprogramming, which extends earlier work on automatic prompt generation. It attempts to learn task-specific word embeddings that, when concatenated to the input text, instruct the language model to solve the specified task. We show that this approach outperforms other methods with a similar number of trainable parameters on SST-2 and MNLI datasets. On SST-2, the performance of our model is comparable to the fully fine-tuned baseline, while on MNLI it is the best among the methods that do not modify the parameters of the body of the language model.