 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTighnari v2: Mitigating Label Noise and Distribution Shift in Multimodal Plant Distribution Prediction via Mixture of Experts and Weakly Supervised Learning
Feb 09, 2026Large-scale, cross-species plant distribution prediction plays a crucial role in biodiversity conservation, yet modeling efforts in this area still face significant challenges due to the sparsity and bias of observational data. Presence-Absence (PA) data provide accurate and noise-free labels, but are costly to obtain and limited in quantity; Presence-Only (PO) data, by contrast, offer broad spatial coverage and rich spatiotemporal distribution, but suffer from severe label noise in negative samples. To address these real-world constraints, this paper proposes a multimodal fusion framework that fully leverages the strengths of both PA and PO data. We introduce an innovative pseudo-label aggregation strategy for PO data based on the geographic coverage of satellite imagery, enabling geographic alignment between the label space and remote sensing feature space. In terms of model architecture, we adopt Swin Transformer Base as the backbone for satellite imagery, utilize the TabM network for tabular feature extraction, retain the Temporal Swin Transformer for time-series modeling, and employ a stackable serial tri-modal cross-attention mechanism to optimize the fusion of heterogeneous modalities. Furthermore, empirical analysis reveals significant geographic distribution shifts between PA training and test samples, and models trained by directly mixing PO and PA data tend to experience performance degradation due to label noise in PO data. To address this, we draw on the mixture-of-experts paradigm: test samples are partitioned according to their spatial proximity to PA samples, and different models trained on distinct datasets are used for inference and post-processing within each partition. Experiments on the GeoLifeCLEF 2025 dataset demonstrate that our approach achieves superior predictive performance in scenarios with limited PA coverage and pronounced distribution shifts.
Weak to Strong: VLM-Based Pseudo-Labeling as a Weakly Supervised Training Strategy in Multimodal Video-based Hidden Emotion Understanding Tasks
Feb 08, 2026To tackle the automatic recognition of "concealed emotions" in videos, this paper proposes a multimodal weak-supervision framework and achieves state-of-the-art results on the iMiGUE tennis-interview dataset. First, YOLO 11x detects and crops human portraits frame-by-frame, and DINOv2-Base extracts visual features from the cropped regions. Next, by integrating Chain-of-Thought and Reflection prompting (CoT + Reflection), Gemini 2.5 Pro automatically generates pseudo-labels and reasoning texts that serve as weak supervision for downstream models. Subsequently, OpenPose produces 137-dimensional key-point sequences, augmented with inter-frame offset features; the usual graph neural network backbone is simplified to an MLP to efficiently model the spatiotemporal relationships of the three key-point streams. An ultra-long-sequence Transformer independently encodes both the image and key-point sequences, and their representations are concatenated with BERT-encoded interview transcripts. Each modality is first pre-trained in isolation, then fine-tuned jointly, with pseudo-labeled samples merged into the training set for further gains. Experiments demonstrate that, despite severe class imbalance, the proposed approach lifts accuracy from under 0.6 in prior work to over 0.69, establishing a new public benchmark. The study also validates that an "MLP-ified" key-point backbone can match - or even surpass - GCN-based counterparts in this task.
Learning Continuous Solvent Effects from Transient Flow Data: A Graph Neural Network Benchmark on Catechol Rearrangement
Dec 22, 2025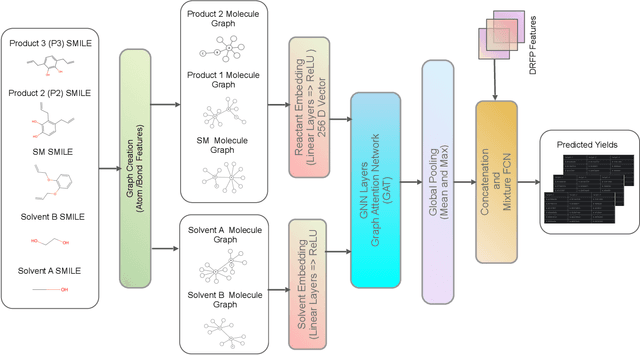
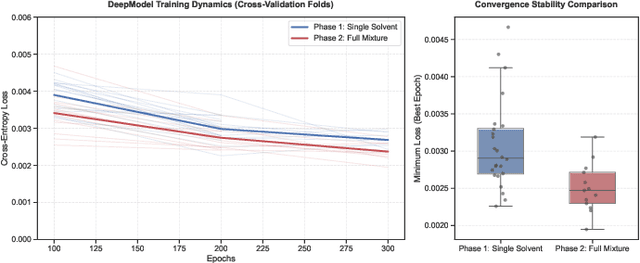
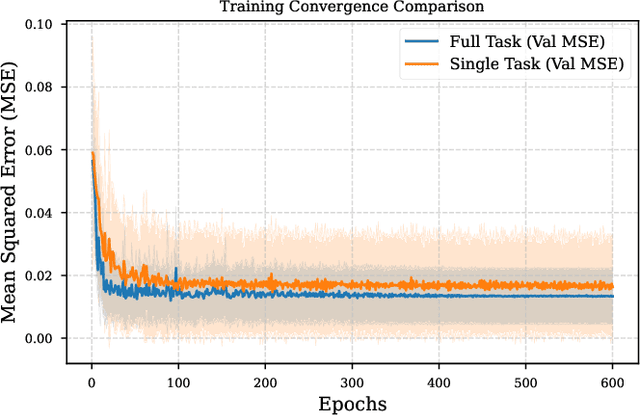
Predicting reaction outcomes across continuous solvent composition ranges remains a critical challenge in organic synthesis and process chemistry. Traditional machine learning approaches often treat solvent identity as a discrete categorical variable, which prevents systematic interpolation and extrapolation across the solvent space. This work introduces the \textbf{Catechol Benchmark}, a high-throughput transient flow chemistry dataset comprising 1,227 experimental yield measurements for the rearrangement of allyl-substituted catechol in 24 pure solvents and their binary mixtures, parameterized by continuous volume fractions ($\% B$). We evaluate various architectures under rigorous leave-one-solvent-out and leave-one-mixture-out protocols to test generalization to unseen chemical environments. Our results demonstrate that classical tabular methods (e.g., Gradient-Boosted Decision Trees) and large language model embeddings (e.g., Qwen-7B) struggle with quantitative precision, yielding Mean Squared Errors (MSE) of 0.099 and 0.129, respectively. In contrast, we propose a hybrid GNN-based architecture that integrates Graph Attention Networks (GATs) with Differential Reaction Fingerprints (DRFP) and learned mixture-aware solvent encodings. This approach achieves an \textbf{MSE of 0.0039} ($\pm$ 0.0003), representing a 60\% error reduction over competitive baselines and a $>25\times$ improvement over tabular ensembles. Ablation studies confirm that explicit molecular graph message-passing and continuous mixture encoding are essential for robust generalization. The complete dataset, evaluation protocols, and reference implementations are released to facilitate data-efficient reaction prediction and continuous solvent representation learning.