 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Networks and Autoencoders: The Primal-Dual Relationship and Generalization Bounds
Feb 03, 2019Since the introduction of Generative Adversarial Networks (GANs) and Variational Autoencoders (VAE), the literature on generative modelling has witnessed an overwhelming resurgence. The impressive, yet elusive empirical performance of GANs has lead to the rise of many GAN-VAE hybrids, with the hopes of GAN level performance and additional benefits of VAE, such as an encoder for feature reduction, which is not offered by GANs. Recently, the Wasserstein Autoencoder (WAE) was proposed, achieving performance similar to that of GANs, yet it is still unclear whether the two are fundamentally different or can be further improved into a unified model. In this work, we study the $f$-GAN and WAE models and make two main discoveries. First, we find that the $f$-GAN objective is equivalent to an autoencoder-like objective, which has close links, and is in some cases equivalent to the WAE objective - we refer to this as the $f$-WAE. This equivalence allows us to explicate the success of WAE. Second, the equivalence result allows us to, for the first time, prove generalization bounds for Autoencoder models (WAE and $f$-WAE), which is a pertinent problem when it comes to theoretical analyses of generative models. Furthermore, we show that the $f$-WAE objective is related to other statistical quantities such as the $f$-divergence and in particular, upper bounded by the Wasserstein distance, which then allows us to tap into existing efficient (regularized) OT solvers to minimize $f$-WAE. Our findings thus recommend the $f$-WAE as a tighter alternative to WAE, comment on generalization abilities and make a step towards unifying these models.
Integral Privacy for Sampling from Mollifier Densities with Approximation Guarantees
Sep 12, 2018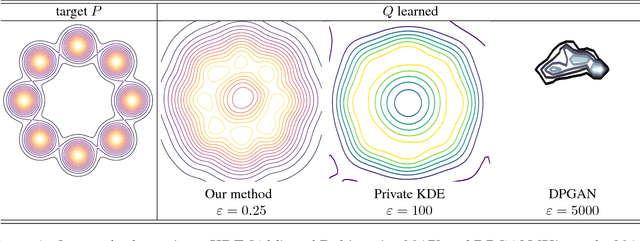
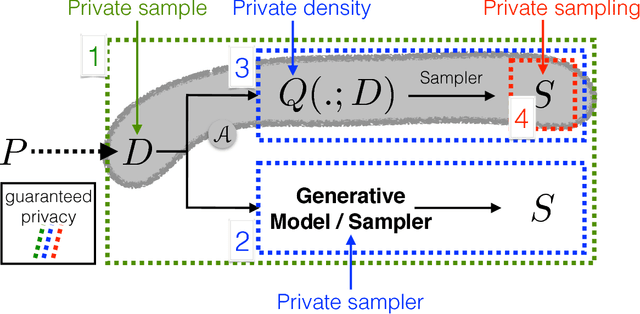
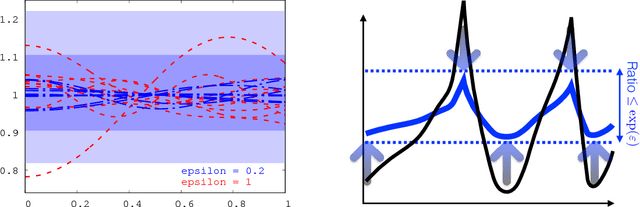
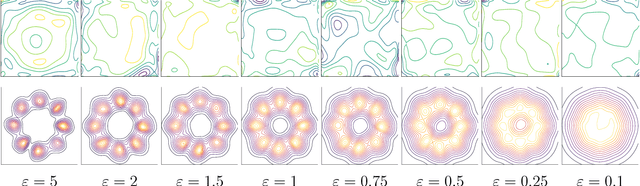
Sampling encompasses old and central problems in statistics and machine learning. There exists several approaches to cast this problem in a differential privacy framework but little is still comparatively known about the approximation guarantees of the unknown density by the private one learned. In this paper, we first introduce a general condition for a set of densities, called an $\varepsilon$-mollifier, to grant privacy for sampling in the $\varepsilon$-differential privacy model, and even in a stronger model where we remove the famed adjacency condition of inputs. We then show how to exploit the boosting toolkit to learn a density within an $\varepsilon$-mollifier with guaranteed approximation of the target density that degrade gracefully with the privacy budget. Approximation guarantees cover the mode capture problem, a problem which is receiving a lot of attention in the generative models literature. To our knowledge, the way we exploit the boosting toolkit has never been done before in the context of density estimation or sampling: we require access to a weak learner in the original boosting sense, so we learn a density out of \textit{classifiers}. Experimental results against a state of the art implementation of private kernel density estimation display that our technique consistently obtains improved results, managing in particular to get similar outputs for a privacy budget $\epsilon$ which is however orders of magnitude smaller.