 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDumb++: Drift-Aware Continual Test-Time Adaptation
Jan 22, 2026Continual Test-Time Adaptation (CTTA) seeks to update a pretrained model during deployment using only the incoming, unlabeled data stream. Although prior approaches such as Tent, EATA etc. provide meaningful improvements under short evolving shifts, they struggle when the test distribution changes rapidly or over extremely long horizons. This challenge is exemplified by the CCC benchmark, where models operate over streams of 7.5M samples with continually changing corruption types and severities. We propose RDumb++, a principled extension of RDumb that introduces two drift-detection mechanisms i.e entropy-based drift scoring and KL-divergence drift scoring, together with adaptive reset strategies. These mechanisms allow the model to detect when accumulated adaptation becomes harmful and to recover before prediction collapse occurs. Across CCC-medium with three speeds and three seeds (nine runs, each containing one million samples), RDumb++ consistently surpasses RDumb, yielding approx 3% absolute accuracy gains while maintaining stable adaptation throughout the entire stream. Ablation experiments on drift thresholds and reset strengths further show that drift-aware resetting is essential for preventing collapse and achieving reliable long-horizon CTTA.
QUAIL: Quantization Aware Unlearning for Mitigating Misinformation in LLMs
Jan 21, 2026Machine unlearning aims to remove specific knowledge (e.g., copyrighted or private data) from a trained model without full retraining. In practice, models are often quantized (e.g., 4-bit) for deployment, but we find that quantization can catastrophically restore forgotten information [1]. In this paper, we (1) analyze why low-bit quantization undermines unlearning, and (2) propose a quantization-aware unlearning method to mitigate this. We first compute weight-change statistics and bucket overlaps in quantization to show that typical unlearning updates are too small to cross quantization thresholds. Building on this insight, we introduce a logits space hinge loss: for each forget example, we force the output logits of the unlearned model to differ from the original model by at least a margin (half the quantization step). This ensures forgotten examples remain distinguishable even after quantization. We evaluate on language and classification tasks (including a Twitter misinformation dataset) and show our method preserves forgetting under 4-bit quantization, whereas existing methods almost entirely recover the forgotten knowledge.
Mic-hackathon 2024: Hackathon on Machine Learning for Electron and Scanning Probe Microscopy
Jun 10, 2025

Microscopy is a primary source of information on materials structure and functionality at nanometer and atomic scales. The data generated is often well-structured, enriched with metadata and sample histories, though not always consistent in detail or format. The adoption of Data Management Plans (DMPs) by major funding agencies promotes preservation and access. However, deriving insights remains difficult due to the lack of standardized code ecosystems, benchmarks, and integration strategies. As a result, data usage is inefficient and analysis time is extensive. In addition to post-acquisition analysis, new APIs from major microscope manufacturers enable real-time, ML-based analytics for automated decision-making and ML-agent-controlled microscope operation. Yet, a gap remains between the ML and microscopy communities, limiting the impact of these methods on physics, materials discovery, and optimization. Hackathons help bridge this divide by fostering collaboration between ML researchers and microscopy experts. They encourage the development of novel solutions that apply ML to microscopy, while preparing a future workforce for instrumentation, materials science, and applied ML. This hackathon produced benchmark datasets and digital twins of microscopes to support community growth and standardized workflows. All related code is available at GitHub: https://github.com/KalininGroup/Mic-hackathon-2024-codes-publication/tree/1.0.0.1
Scared into Action: How Partisanship and Fear are Associated with Reactions to Public Health Directives
Jan 14, 2021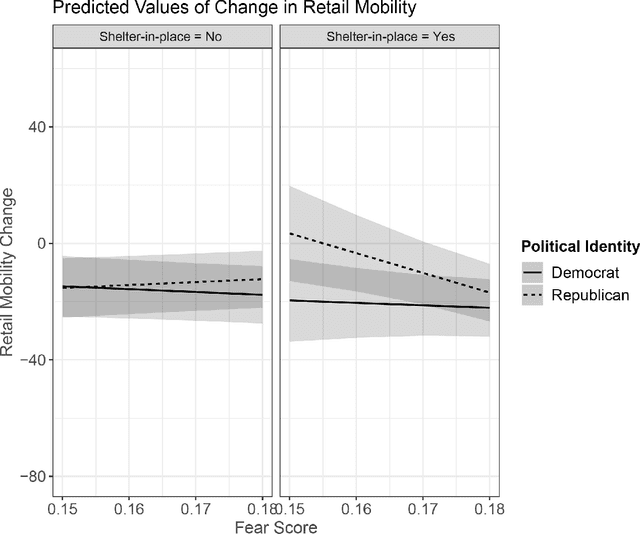
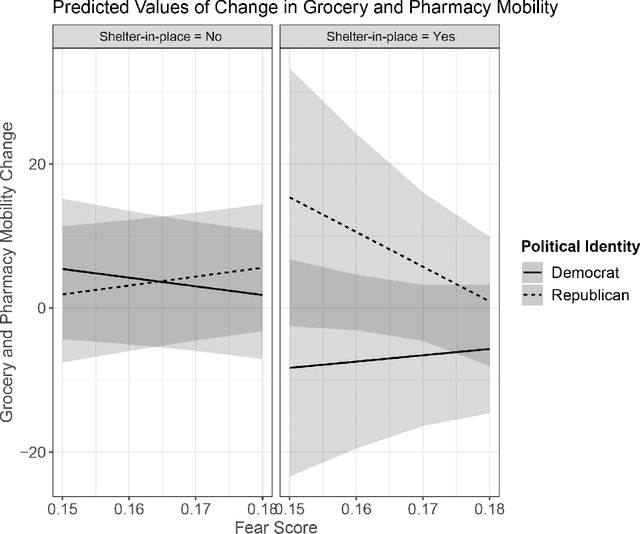
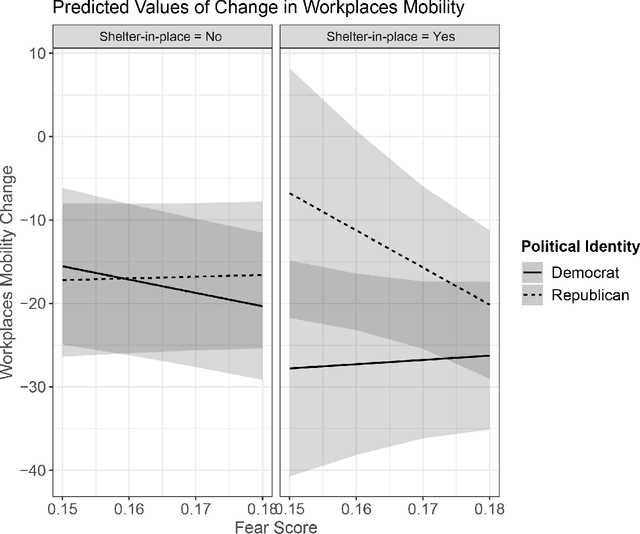
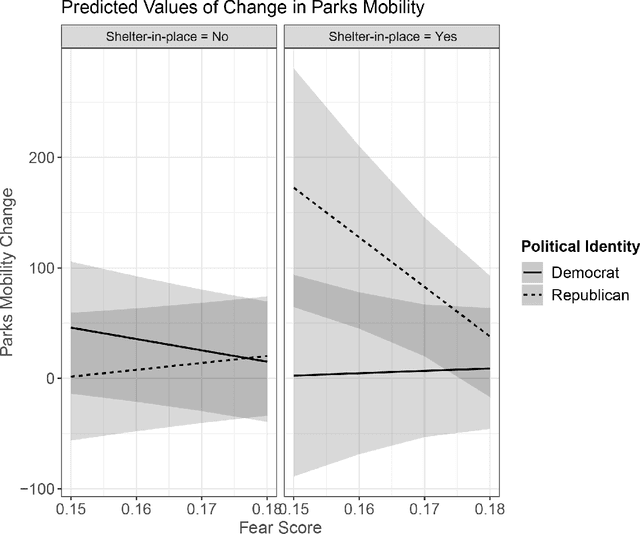
Differences in political ideology are increasingly appearing as an impediment to successful bipartisan communication from local leadership. For example, recent empirical findings have shown that conservatives are less likely to adhere to COVID-19 health directives. This behavior is in direct contradiction to past research which indicates that conservatives are more rule abiding, prefer to avoid loss, and are more prevention-motivated than liberals. We reconcile this disconnect between recent empirical findings and past research by using insights gathered from press releases, millions of tweets, and mobility data capturing local movement in retail, grocery, workplace, parks, and transit domains during COVID-19 shelter-in-place orders. We find that conservatives adhere to health directives when they express more fear of the virus. In order to better understand this phenomenon, we analyze both official and citizen communications and find that press releases from local and federal government, along with the number of confirmed COVID-19 cases, lead to an increase in expressions of fear on Twitter.