 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Semantic Correspondence where Every Pixel is a Classifier
May 15, 2015


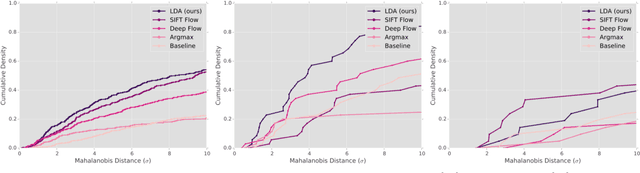
Determining dense semantic correspondences across objects and scenes is a difficult problem that underpins many higher-level computer vision algorithms. Unlike canonical dense correspondence problems which consider images that are spatially or temporally adjacent, semantic correspondence is characterized by images that share similar high-level structures whose exact appearance and geometry may differ. Motivated by object recognition literature and recent work on rapidly estimating linear classifiers, we treat semantic correspondence as a constrained detection problem, where an exemplar LDA classifier is learned for each pixel. LDA classifiers have two distinct benefits: (i) they exhibit higher average precision than similarity metrics typically used in correspondence problems, and (ii) unlike exemplar SVM, can output globally interpretable posterior probabilities without calibration, whilst also being significantly faster to train. We pose the correspondence problem as a graphical model, where the unary potentials are computed via convolution with the set of exemplar classifiers, and the joint potentials enforce smoothly varying correspondence assignment.
Regression-Based Image Alignment for General Object Categories
Jul 08, 2014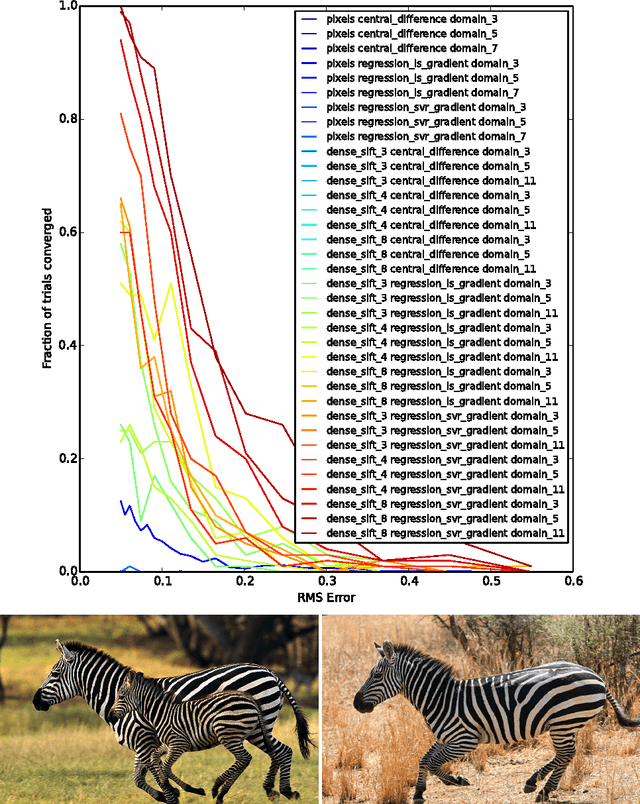


Gradient-descent methods have exhibited fast and reliable performance for image alignment in the facial domain, but have largely been ignored by the broader vision community. They require the image function be smooth and (numerically) differentiable -- properties that hold for pixel-based representations obeying natural image statistics, but not for more general classes of non-linear feature transforms. We show that transforms such as Dense SIFT can be incorporated into a Lucas Kanade alignment framework by predicting descent directions via regression. This enables robust matching of instances from general object categories whilst maintaining desirable properties of Lucas Kanade such as the capacity to handle high-dimensional warp parametrizations and a fast rate of convergence. We present alignment results on a number of objects from ImageNet, and an extension of the method to unsupervised joint alignment of objects from a corpus of images.
Why do linear SVMs trained on HOG features perform so well?
Jun 10, 2014
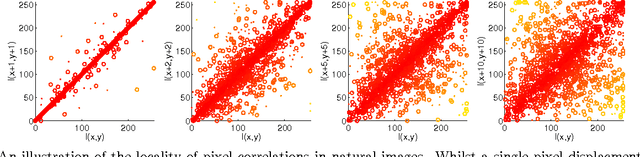
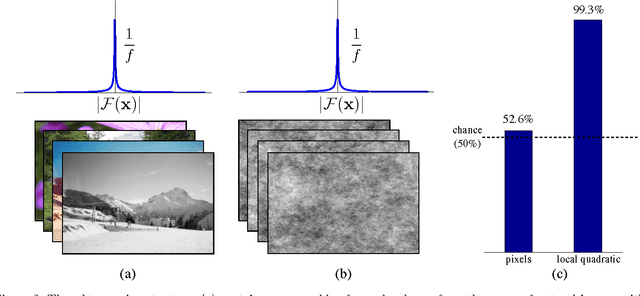

Linear Support Vector Machines trained on HOG features are now a de facto standard across many visual perception tasks. Their popularisation can largely be attributed to the step-change in performance they brought to pedestrian detection, and their subsequent successes in deformable parts models. This paper explores the interactions that make the HOG-SVM symbiosis perform so well. By connecting the feature extraction and learning processes rather than treating them as disparate plugins, we show that HOG features can be viewed as doing two things: (i) inducing capacity in, and (ii) adding prior to a linear SVM trained on pixels. From this perspective, preserving second-order statistics and locality of interactions are key to good performance. We demonstrate surprising accuracy on expression recognition and pedestrian detection tasks, by assuming only the importance of preserving such local second-order interactions.
Optimization Methods for Convolutional Sparse Coding
Jun 10, 2014
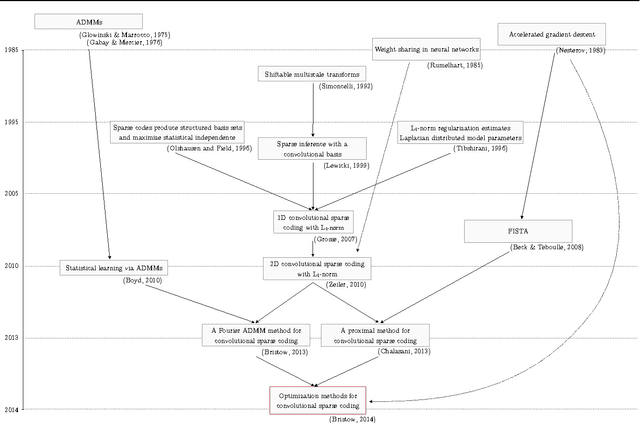
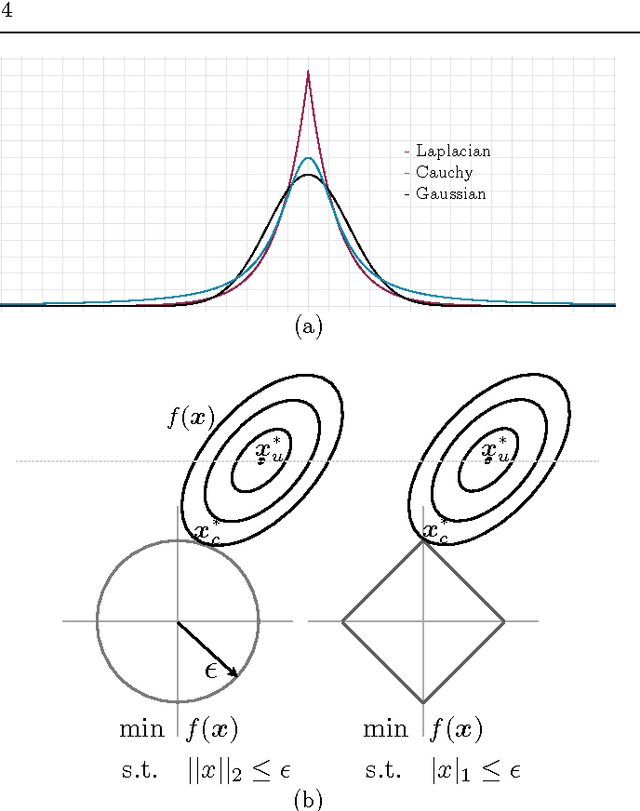

Sparse and convolutional constraints form a natural prior for many optimization problems that arise from physical processes. Detecting motifs in speech and musical passages, super-resolving images, compressing videos, and reconstructing harmonic motions can all leverage redundancies introduced by convolution. Solving problems involving sparse and convolutional constraints remains a difficult computational problem, however. In this paper we present an overview of convolutional sparse coding in a consistent framework. The objective involves iteratively optimizing a convolutional least-squares term for the basis functions, followed by an L1-regularized least squares term for the sparse coefficients. We discuss a range of optimization methods for solving the convolutional sparse coding objective, and the properties that make each method suitable for different applications. In particular, we concentrate on computational complexity, speed to {\epsilon} convergence, memory usage, and the effect of implied boundary conditions. We present a broad suite of examples covering different signal and application domains to illustrate the general applicability of convolutional sparse coding, and the efficacy of the available optimization methods.